Let’s go back in time to June, 2012. LinkedIn was compromised and 6.5 million password hashes were released to the internet. Everyone changed their password (right?) and it wasn’t *that* big a deal. Now, let’s jump forward in time, to sometime when biometric authentication becomes more common. In this new era, LinkedIn gets compromised, and 6.5 million hashed fingerprints are released to the internet…so everyone does what? Do users switch the fingers they use for authentication? Biometric authentication is a great idea that, unfortunately, suffers from some serious drawbacks, especially when deployed in the cloud.
Biometric authentication’s greatest weakness is immutability. Your fingerprints aren’t going to change, and failing some pretty major plastic surgery, your face won’t either. This basically means one big problem: You can’t change a compromised biometric. Do you have any publicly accessible pictures on Facebook? What about videos? Could those be used to hack facial recognition, even with liveness detection? The way your biometric features are set in stone mean there is a much greater responsibility to protect them, and unfortunately you aren’t the only one who bears that responsibility.
Cloud services that leverage biometrics aren’t super common yet, but assuming biometrics catch on, it’s only a matter of time before the marketing types make it happen. How is that data stored? Can you really trust your service provider to take better care of your fingerprint than your password? Millions of passwords get exposed by hacks like the LinkedIn hack every year. Most services require users to register at least two fingerprints to use fingerprint-based auth; that gives users at MAX 10 password resets for an entire lifetime. After that, the data used for authentication starts repeating: which fingers you use for authentication may change, but if an attacker has compromised a fingerprint, they can use that fingerprint to bruteforce any authentication schema that relies on the compromised finger’s data – a kind of known-plaintext attack. That isn’t the only issue with immutability, either. There is a reason best practices recommend using separate passwords for separate services.
If you use biometric authentication for multiple services, the security of your access to those services is linked (just like with a normal password). Basically, you’re trusting every service provider with the password to your other accounts. Maybe that’s okay with you; you’re fine if some social network knows your bank account password. Unfortunately for you, it isn’t that simple. If that social network ever gets compromised, within hours your bank account password will be on Pastebin, and I’ll eat my hat if some enterprising script kiddie doesn’t have a bot testing out username/fingerprint combinations to every bank service they can find. This only gets worse once you run out of fingers to authenticate with. If anyone ever associates all ten fingerprints with your identity, no account you ever create will be safe with biometric authentication again.
Maybe I’m being a little histrionic. That would be totally fair. There are a bunch of practices that could (maybe not totally) mitigate these issues. And, after all, biometrics are supposed to be part of a dual-factor authentication scheme, right? So we’ll at least have a password in addition to our fingerprints. And any serious company who deploys biometric authentication will surely encrypt the data, and keep it somewhere safe, away from the key. Then again, take a look at biometric authentication right now. My coworker Karl wrote a blog about consumer grade fingerprint readers in Lenovo laptops. His conclusion was that the software was pretty lax about storing sensitive data. What happens when practices like that move into realms like banking and health care?
Truth be told, I don’t think this problem is unsolvable. It’s always possible to simply not use biometrics! For anyone who still wants to use biometric authentication, just take this warning and exercise real caution in the storage of your users’ data, and keep in mind that the technology needs some serious refinement before consumer-grade biometric scanners provide any real protection.
CA SiteMinder is a secure Single Sign-On (SSO) and Web access management product that is used to authenticate users and control access to web applications and portals. Your company may be considering purchasing SiteMinder or a similar product, or may have already deployed a solution like SiteMinder in your environment.
Out of the box, CA SiteMinder can prevent some of the typical OWASP Top 10 vulnerabilities. These include SQL Injection and Cross-site scripting (XSS). I worked with it a few years ago in my previous job and it worked well,. That is until the developers got involved. Their business requirements had them pass full SQL statements from the browser to their application. Additionally, many of them think they needed to also pass in the “” to the Web application. We had to tweak CA SiteMinder to allow these types of requests. As you may have guessed, their application was now potentially vulnerable to SQL Injection and XSS.
These dangerous configurations also make some of CA SiteMinder’s standard web pages vulnerable to XSS. CA SiteMinder comes with some standard web pages and executables that you can use in your Web application. These include loginandregister-dms.fcc, loginandregisterwithforgottenpassword-dms.fcc, login.fcc and smpwservicescgi.exe. By not allowing CA SiteMinder to stop the XSS attacks, these Web pages also become vulnerable.
NetSPI has performed application penetration tests in the last few months where the applications were using CA SiteMinder. The applications we were testing were vulnerable to XSS; both the application itself and the CA SiteMinder files. SiteMinder is intended to reduce risk, not expand it.
These vulnerabilities could have been prevented by not configuring CA SiteMinder so it does not block XSS. Do not allow the developers to dictate that the security be weakened; work with them and reduce their requests to the most basic requirements and figure out how to securely deliver what they need. Remember, security and development should be partners, not bitter rivals. You want multiple layers of prevention, so if your application is vulnerable, CA SiteMinder will prevent the vulnerability from being exploited.
As penetration testers, we are frequently engaged to do penetration tests for PCI compliance. As a part of these penetration tests, we look for cardholder data (Card Numbers, CVV, etc.) in files, network traffic, databases, and anywhere else we might be able to catch it. Often times, we will find hashes of credit card numbers along with the first six and/or last four numbers of the credit card number. Given that credit card numbers are a fixed length, this limits the keyspace that we need to use to brute force the hashes.
The language in the PCI DSS is a little vague about how cardholder data needs to be hashed, but there is information in requirement 3.4 that helps.
“Render PAN unreadable anywhere it is stored (including on portable digital media, backup media, and in logs) by using any of the following approaches:
One-way hashes based on strong cryptography (hash must be of the entire PAN)
Truncation (hashing cannot be used to replace the truncated segment of PAN)
Index tokens and pads (pads must be securely stored)
Strong cryptography with associated key-management processes and procedure”
While this information is good, it does not ensure that the implementer of the hashing function is doing things correctly. “Strong cryptography” can be interpreted a number of different ways. One could argue that SHA256 is a strong hashing algorithm, therefore meeting the requirements. It does not take a significant amount of effort for us to try and brute force SHA256 hashes, so the strength of the algorithm is a moot point.
This type of attack is actually called out as a footnote in the requirement.
“Note: It is a relatively trivial effort for a malicious individual to reconstruct original PAN data if they have access to both the truncated and hashed version of a PAN. Where hashed and truncated versions of the same PAN are present in an entity‘s environment, additional controls should be in place to ensure that the hashed and truncated versions cannot be correlated to reconstruct the original PAN.”
These “additional controls” could include salts for the hashes (frequently stored with the hash) or encrypting the truncated versions. There are a number of other potential controls that we could talk about, but that would be enough info for another post. Even with proper additional controls on the PAN data (truncated and hashed), the root of the issue is still the length of the card number and the limited keyspace that is needed for guessing the number.
Given a (potentially) sixteen digit card number, the first six digits, and the last four digits, we are able to easily iterate through the remaining six digits in a matter of minutes. There are only a fixed number of IIN or BIN prefixes for cards (think the first 4-6 numbers of a card). These numbers are available online and pretty easy to find. Given a list of these numbers, we are able to reduce our cracking efforts for situations where hashes are only stored with the last four digits of the card number. Factoring in that credit card numbers are Luhn valid, this reduces the amount of effort that we have to go through to hash the credit card number guesses.
Example Card Format:
For this example, we will use the TCF Debit Card BIN. With a million potential card numbers (000000 to 999999 for the middle digits) with a last four digits of 1234, there are 100,000 potential Luhn valid card numbers in this space. So as you can see in this case, the Luhn check cuts the cracking space down by ninety percent. As it turns out, this will be the case with any of the credit card numbers that you are brute forcing. Since the last (or check) digit can only be one of ten numbers (0-9), you are limiting the number of valid Luhn check numbers to one of the ten numbers. Simply put, this works because you are not brute forcing the check digit.
Time wise, it takes about 30 minutes to get through this keyspace (for the example number above) on a 2.80 Ghz Intel Core i7 processor. I also ran this test with several other programs open, so your results may vary. In general practice, I’ve seen most hashes crack within two minutes.
Code
The code for cracking these hashes is actually quite simple. Read in the input file, iterate through the numbers that need guessing, and hash the Luhn valid numbers. If the guess hash matches your input hash, it will write out your results to your output file. There’s also a small block in here to read in a list of IIN/BINS to use when you need to do guessing on the first 4-6 card numbers. You will have to provide your own list of these.
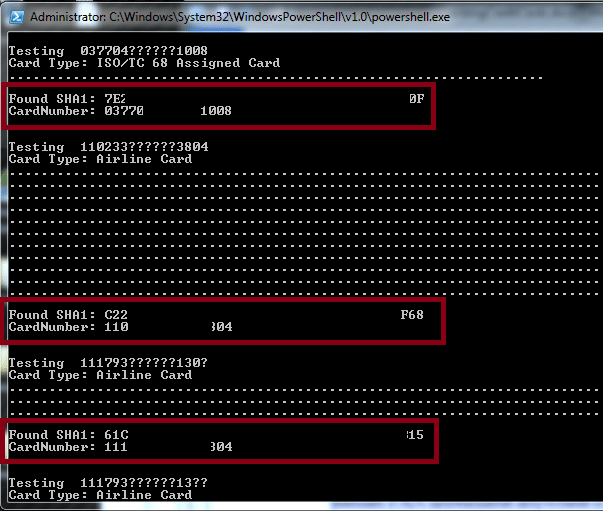
Below is some sample output with the full card numbers and hashes redacted. Each period represents a Luhn valid card number and is used to show the cracking status.
The PCI DSS allows merchants to store partial card numbers, but not the full number. While the card number may not be stored in full, storing the hash of the card along with some of the digits allows an attacker to make educated guesses about the card number. This basically renders the hashing useless. While this is directly called out in requirement 3.4 of the DSS, we have found instances of hashes being stored with the truncated PAN data. Even without the truncated PAN data, the cracking effort for a card number hash is still reduced by the static IIN/BIN numbers associated with the card issuer.
Microsoft SQL Server allows links to be created to external data sources such as other SQL servers, Oracle databases, excel spreadsheets, and so on. Due to common misconfigurations the links, or “Linked Servers”, can often be exploited to traverse database link networks, gain unauthorized access to data, and deploy shells…
Introduction to SQL Server Links
Creating a SQL Server link is pretty trivial. Depending on your preference, it can be done with the “sp_addlinkedserver” stored procedure or SQL Server Management Studio (SSMS). For more information about creating database links visit https://technet.microsoft.com/en-us/library/ms190479.aspx. Typically attackers don’t create links. However, they do view and exploit them.
Existing links can be viewed from the “Server Objects->Link Servers” menu in SSMS. Alternatively, they can be listed with the “sp_linkedservers” stored procedure, or by issuing the query “select * from master..sysservers”. Selecting directly from the “sysservers” table is the preferred method as it discloses a little more information about the links.
For existing links, there are a few key settings to pay attention to. Obviously the link destination (srvname), type of data source (providername), and whether the link is accessible (dataaccess), are important for exploiting the links. Additionally, outgoing RPC connections (rpcout) need to be enabled on links in order to enable xp_cmdshell on remote linked servers.
There are two major configurations that attackers focus on when hacking database links. Those include the data source (providername) and the way that links are configured to authenticate. In this blog I’ll only be focusing on SQL Server data sources for links that connect to other SQL Servers.
Each of those SQL Server links can be configured to authenticate in a number of different ways. It is possible to disable the links by not providing any connection credentials, it’s possible to use the current security context, or it’s possible to preset a SQL account and password that will be used for all connections that use the link. Our experience during penetration testing is that after crawling all of the links there is always one or more configured with sysadmin permissions; this allows for privilege escalation from the initial public access to sysadmin access without ever leaving the database layer.
Selecting Data From SQL Server links
Although only sysadmins can create links, any database user can attempt to access them. However, there are two very important things to understand regarding the usage of links:
If a link is enabled (dataaccess set to 1), every user on the database server can use the link regardless of the user’s permissions (public, sysadmin, doesn’t matter)
If the link is configured to use a SQL account, every connection is made with the privileges of that account (privileges on the link destination). In other words, public user on server A can potentially execute SQL queries on server B as sysadmin.
SQL Server links are very easy to use. Openquery()can be used in T-SQL to select data from database links. For example, the following query enumerates the server version on the remote server:
select version from openquery(“linkedserver”, ‘select @@version as version’);
It is also possible to use openquery to execute SQL queries over multiple nested links; this makes link chaining possible and thus allows the exploitation of link trees:
select version from openquery(“link1”,’select version from openquery(“link2”,’’select @@version as version’’)’)
The same way it’s possible to nest as many openquery statements as necessary to access all the linked servers. The only “problem” is that every nested query has to use twice as many single quotes as the outer query; writing queries gets quite cumbersome when you have to use 32 single quotes around every string.
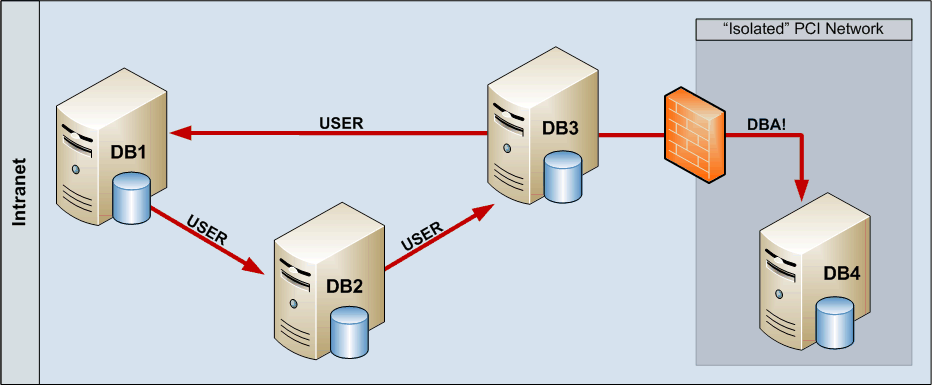
The following image shows an example of a typical linked database network. A user with public privilege access to DB1 can follow the database link to DB2 (user level permissions), and from DB2 to DB3 (user level permissions). Now, it’s possible to follow the link from DB3 back to DB1 (user level permissions) or the link to DB4. As this link is configured with elevated privileges, following the link chain from DB1 to DB2 to DB3 to DB4 gives the (originally non-privileged) user sysadmin permissions on DB4 which is located in an “Isolated” network zone.
Database links can be queried using alternative syntax as well but it doesn’t allow queries over multiple links; also, actual exploitation requires rpcout to be enabled for the links and as rpcout is disabled by default this is somewhat unlikely to work that often. An example of the alternative four part naming syntax is below.
select name FROM [linkedserver].master.sys.databases
Boring… Give Me a Shell Already!
One last think to know for the exploitation of linked servers is that even though Microsoft states “OPENQUERY cannot be used to execute extended stored procedures on a linked server” it is possible. The trick is to return some data, end SQL statement, and then execute the desired stored procedure. Below is a basic example of how to execute xp_cmdshell over a database link using openquery():
select 1 from openquery(“linkedserver”,’select 1;exec master..xp_cmdshell ’’dir c:’’’)
The query doesn’t return the results of xp_cmdshell, but if xp_cmdshell is enabled and the user has the privileges to execute it, it will execute the dir command on the operating system. During penetration tests this approach has allowed us to compromise the underlying operating system and further compromise the targeted IT infrastructure. One easy way to get a shell on the target system is to call PowerShell (if the OS has it installed), inject reverse meterpreter stager into memory, and wait for it to call back home. The general process works as follows:
Create a PowerShell script to execute your Metasploit payload using the techniques from https://www.exploit-monday.com/2011_10_16_archive.html.
Next, Unicode encode the script with the programming language of your choice.
Then, base64 encode the string with the programming language of your choice.
Finally, execute the “powershell –noexit –noprofile –EncodedCommand ” command via xp_cmdshell.
If xp_cmdshell is not enabled on a linked server, it may not be possible to enable it even if the link is configured with sysadmin privileges. Any queries executed via openquery are considered user transactions which don’t allow reconfigure to be run. Enabling xp_cmdshell using sp_configure does not change the server state without reconfigure and thus xp_cmdshell will stay disabled. If rpcout is enabled for all links on the link path, it is possible to enable xp_cmdshell using the following syntax:
EXECUTE('sp_configure ''xp_cmdshell'',1;reconfigure;') AT LinkedServer
But like I mentioned before, rpcout is disabled by default so it’s pretty unlikely to work over long link chains.
Exploiting SQL Server Links Externally
While database links can be a way to escalate privileges after getting authenticated access to a database internally, a more serious risk is introduced when linked servers are available externally. SQL injection vulnerabilities are still very common and successful injection attack allows arbitrary SQL query execution on the database server. If the web application ‘s database connection is configured with least privilege (pretty common) it is not trivial to escalate permissions to the internal network where the database server is likely located. However, like mentioned before, any user regardless of their privilege level is allowed to use the preconfigured database links. We have found during penetration tests that links configured with sysadmin privileges typically lead to a complete compromise of the internal network environment.
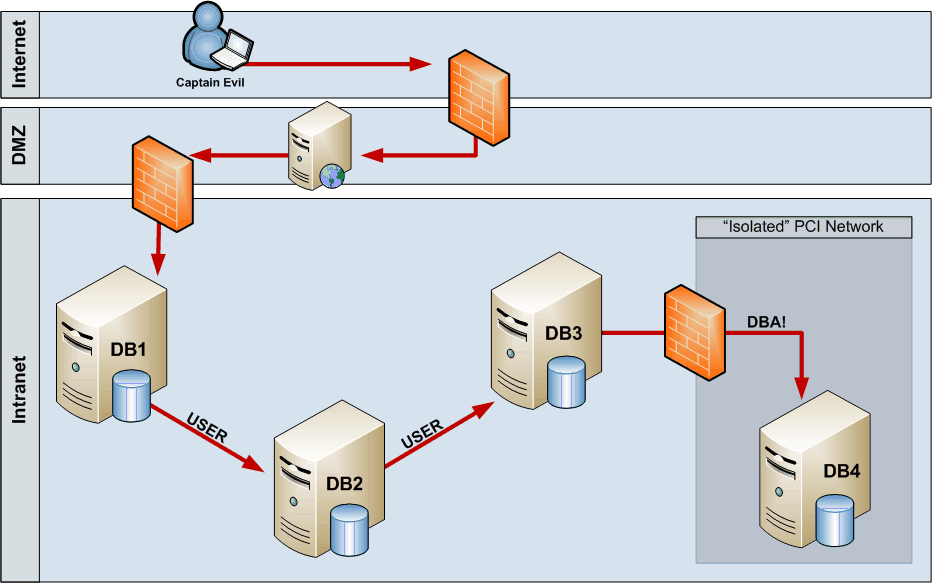
The following image shows an attack path for an external compromise. After identifying a SQL injection on the DMZ web application server, Captain Evil can start following the links from DB1 to DB2 to DB3 to DB4. And after getting sysadmin permissions on DB4, Captain Evil can execute xp_cmdshell to execute Powershell and shoot back a reverse shell. So by compromising the web application it’s possible to gain access to a secure network without any “hacking” within the Intranet. Just by following database links using legitimate (i.e. not blocked by internal ACL etc.) database connections Captain Evil got access to the most critical system (and maybe more).
Automating the Whole Thing
Scott Sutherland and I wrote two Metasploit exploits to automate the whole process described in this blog: one for direct database connections (and this one could be used for legitimate link auditing as well) and one for SQL injection using error, union, or time based blind injections. The modules crawl all the database links between SQL Servers, identify sysadmin connections, and if xp_cmdshell is enabled, deploy a chosen Metasploit payload (has be a reverse payload as the attacker won’t know where the vulnerable database server actually is). The direct exploit (mssql_linkcrawler) has been merged into Metasploit and the other one is waiting for approval (currently available at https://github.com/nullbind/Metasploit-Modules/blob/master/mssql_linkcrawler_sqli.rb).
Prevention
If you do not need database links, remove them all. It’s pretty common to see links going from production environment to development environment. This shouldn’t be done in the first place, but even worse is the “who cares about the dev databases, we don’t care if the links have sysadmin privileges” attitude. You should care as escalating an attack in the dev environment will eventually give full access to prod environment too. So keep in mind, all the database links should be configured with the least privilege; restrict access to those databases / tables that are really needed.
In this blog, we will simply go over common ways to get hashes along with methods and strategies for cracking the hashes. We will touch on most of these topics at a high level, and add links to help you get more information on each topic. Again, this is a pretty basic intro, but hopefully it will serve as a starter’s guide for those looking into password cracking.
Common Ways to Get Hashes
We could write an entire post on ways to capture these, but we will just touch on some high level common methods for getting the hashes.
LM/NTLM
One of the most common hashes that we crack are Windows LANMAN and/or NTLM hashes.
For systems where you have file read rights on the SYSTEM and SAM files (local admin rights, web directory traversal, etc.), you will want to copy them off of the host for hash extraction.
Windows XP/Vista/Server 2003 Paths:
C:WindowsSystem32configSAM
C:WindowsSystem32configSYSTEM
Windows 7 and Server 2008
C:WindowsSystem32configRegBackSAM
C:WindowsSystem32configRegBackSYSTEM
Once you have these files, there are a number of tools that you can use to extract the hashes. Personally, I just import the files into Cain and export the hashes.
If you have a meterpreter session on the system and “nt-authoritysystem” rights on the host, you can easily run the smart_hashdump module to dump out the local password hashes.
Additionally, you can get password hashes from the network with tools like responder and the smb_capture module in Metasploit. These can be captured in both LM and NTLM formats. The LM format can be cracked with a combination of rainbow tables and cracking. I’ve also automated that process with a script. The cracking of network NTLM hashes is now supported by OCLHashcat. Previously, Cain was the only tool (that I knew of) that could crack them, and Cain was doing CPU cracking, not GPU cracking.
Linux Hashes
Dumping hashes from Linux systems can be fairly straightforward for most systems. If you have root access on the host, you can use the unshadow tool to get the hashes out into a john compatible format. Often times you will have arbitrary file read access, where you will want to get the /etc/shadow and /etc/passwd files for offline cracking of the hashes.
Web App Hashes
Many web applications store their password hashes in their databases. So those hashes may end up getting compromised from SQL injection or other attacks. Web content management systems (wordpress, drupal, etc.), more specifically their plugins, are also common targets for SQL injection and other attacks that expose password hashes. These hashes can vary in format (MD5, SHA1, etc.) but most that I have seen are typically unsalted, making them easier to crack. While some web application hashes are salted, you may get lucky and find the salts in the database with the hashes. It’s not as common, but you may get lucky.
Cracking the Hashes
At this point we’re going to assume that you have taken the time to set up your hardware and software for cracking. If you want some tips, check out the links at the top of this post.
For some of your cracking needs, you will want to start with a simple dictionary attack. This will quickly catch any of the simple or commonly used passwords in your hashes. Given a robust dictionary, a good rule set, and a solid cracking box, it can be pretty easy to crack a lot of passwords with little effort.
Here’s some basic dictionaries to get you started:
Skull Security has a great list (including the Rockyou list) of dictionaries
Crackstation has a 15 GB dictionary available with pay what you want/can pricing
A uniqued copy of Wikipedia can make for an interesting dictionary
You will probably want to get some hashes for benchmarking your cards’ or CPU’s performance. There are tons of possible benchmarking hashes from the cracking requests sections on the InsidePro forums. Here you can frequently find large dumps of hashes from users requesting that someone crack their hashes for them. While the sources of these hashes are rarely disclosed, you could get a great sample of hashes to practice cracking.
As for software, the three main pieces of cracking software that we use are Cain, John the Ripper, and OCLhashcat. I won’t include commands on how to run those, as those are very well documented other places.
Conclusion
Hopefully this blog has given you some tips on getting started on gathering and cracking hashes. If you have any questions on the hardware, software, or anything else, feel free to leave us a comment.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Name
Domain
Purpose
Expiry
Type
YSC
youtube.com
YouTube session cookie.
52 years
HTTP
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Name
Domain
Purpose
Expiry
Type
VISITOR_INFO1_LIVE
youtube.com
YouTube cookie.
6 months
HTTP
Test
test.com
Testing
7 days
HTTP
Analytics cookies help website owners to understand how visitors interact with websites by collecting and reporting information anonymously.
We do not use cookies of this type.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.
We do not use cookies of this type.
Unclassified cookies are cookies that we are in the process of classifying, together with the providers of individual cookies.
We do not use cookies of this type.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies we need your permission. This site uses different types of cookies. Some cookies are placed by third party services that appear on our pages.
Cookie Settings
Discover how the NetSPI BAS solution helps organizations validate the efficacy of existing security controls and understand their Security Posture and Readiness.