
Ethereum Virtual Machine Internals – Part 1
The Ethereum Virtual Machine (EVM) functions as the sandboxed compatibility layer used by the thousands of nodes that constitute the Ethereum distributed state machine, ensuring that smart contracts are executed deterministically in a platform-independent environment.
The EVM operates on the execution layer of the Ethereum protocol, and all operations performed within the virtual machine are recorded on the blockchain and can be verified by any node in the network. This allows for full transparency and immutability of the data processed by the EVM, ensuring the integrity of the network. In this post, we will look at the inner workings of the EVM in detail.
In this three-part series, we will first provide an overview of volatile memory management, function selection, and potential vulnerabilities that may arise from insecure bytecode execution within the EVM. In Part 2, we will dive deeper into persistent EVM storage, exploring how data is stored and retrieved by smart contracts. Finally, Part 3 will focus on message calls in Solidity and the EVM, and vulnerabilities that stem from insecure message calls and storage mismanagement.
Ethereum Network & Smart Contract Recap
Upon receiving incoming transactions, Ethereum network validators first validate and verify them to ensure they are valid and properly signed. Validators then execute the smart contract code contained in transactions to verify the correctness and consistency of the results. If the output is valid, validators propagate the transaction output to additional validators to reach consensus.
Pending transactions are stored in lists called mempools, where they sit until they are added to a block. Once consensus is reached, valid transactions from the mempools are added to the next block to be added to the blockchain. Once the block is added to the blockchain, the transactions it contains are considered final and other nodes in the network can rely on the state of the blockchain to perform further transactions or execute smart contracts1.
Smart contract execution occurs in the EVM implementations running on Ethereum network validators. The EVM is not an actual virtual machine that you would launch via VMware or similar. It is more akin to the Java Virtual Machine in that it primarily functions to translate high-level smart contract code into bytecode for the purposes of portable execution. Common EVM implementations include the Golang-based geth2 client and the Python-based py-evm client3. EVM smart contracts are usually written in high-level domain-specific languages such as Solidity and Vyper4.
Below is a Solidity smart contract representing a short CTF challenge that we will follow through its execution in the EVM. It has at least two significant vulnerabilities, so please do not use this contract for anything other than educational purposes. The goal of this challenge is to take ownership of the contract via exploiting the two issues:
DodgyProxy.sol
pragma solidity >=0.7.0 <0.9.0;
contract DodgyProxy {
address public owner;
constructor() {
owner = msg.sender;
}
modifier onlyOwner {
require(msg.sender == owner, "not owner!");
_;
}
function deleg() private onlyOwner {
address(msg.sender).delegatecall("");
}
struct Pointer { function () internal fwd; }
function hitMe(uint offset) public {
Pointer memory p;
p.fwd = deleg;
assembly { mstore(p, add(mload(p), offset)) }
p.fwd();
}
function inc(uint _num) public pure returns (uint) {
return _num++;
}
}
These issues have been introduced because they are a great way of getting to grips with EVM memory quirks. The rest of this article will center around this contract as it is executed through the EVM. While one of the issues is well-documented, the original inspiration for the second issue can be traced back to a CTF challenge deployed to the Ropsten testnet in June 20185 by Reddit user u/wadeAlexC6.
Bytecode
At its core, the EVM is a stack-based virtual machine that operates on bytecode derived from higher level languages used to write EVM-compatible smart contracts. Below is the bytecode for the example contract, compiled with version 0.8.17 of the Solc Solidity compiler with default optimizations7:
608060405234801561001057600080fd5b50600080546001600160a01b031916331790556101e4806100326000396000f3fe608060405234801561001057600080fd5b50600436106100415760003560e01c806373c768d714610046578063812600df1461005b5780638da5cb5b14610081575b600080fd5b61005961005436600461016e565b6100ac565b005b61006e61006936600461016e565b6100cf565b6040519081526020015b60405180910390f35b600054610094906001600160a01b031681565b6040516001600160a01b039091168152602001610078565b60408051602081019091526100e282018082526100cb9063ffffffff16565b5050565b6000816100db81610187565b5092915050565b6000546001600160a01b0316331461012d5760405162461bcd60e51b815260206004820152600a6024820152696e6f74206f776e65722160b01b604482015260640160405180910390fd5b60405133906000818181855af49150503d8060008114610169576040519150601f19603f3d011682016040523d82523d6000602084013e505050565b505050565b60006020828403121561018057600080fd5b5035919050565b6000600182016101a757634e487b7160e01b600052601160045260246000fd5b506001019056fea26469706673582212202e788aebe90e09dbd8b71fced8e6c375f7d2d2989dc683afe753f805e0aa823864736f6c63430008110033
Let’s see how this bytecode ends up looking as it starts moving through EVM’s architecture, by first looking at some key EVM data structures.
EVM Architecture
Smart contract execution occurs inside the EVM instances of Ethereum network validators. When a smart contract starts execution, the EVM creates an execution context that includes various data structures and state variables that are described below. After execution has finished, the execution context is discarded, ready for the next contract. Here is a high-level overview of an EVM execution context:
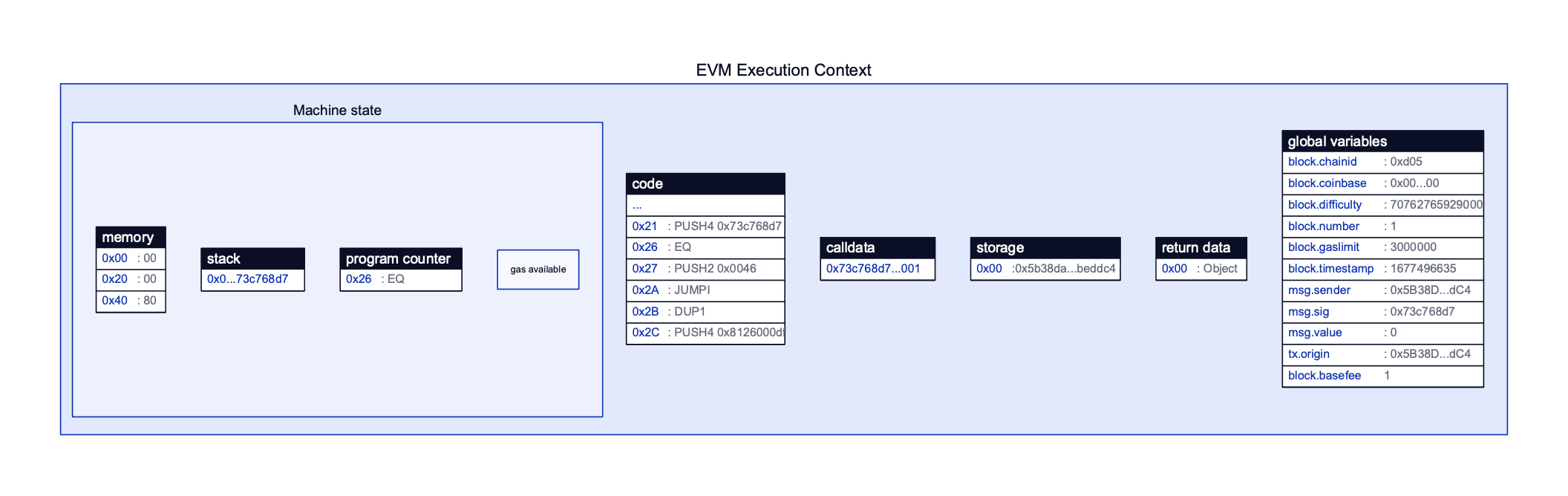
Stack
The EVM’s stack serves as Last-In-First-Out (LIFO) data structure for storing temporary values during the execution of a smart contract. As of writing, the stack operates with a maximum of 1024 32-byte elements8. These elements may include control flow information, storage addresses, and the results and parameters for smart contract instructions.
The main instructions that operate on the stack are the PUSH opcode variants, the POP opcode, as well as the DUP and SWAP opcode variants. These allow elements to be added, removed, duplicated, and swapped on the stack respectively.
Code
The code region stores a contract’s bytecode in its entirety. This region is read-only.
Storage
The Storage region is a persistent key-value store. Keys and values are both 32-byte slots where permanent but mutable data that forms part of the contract’s state is stored. Data in Storage is persistent in that it is retained between calls. This includes state variables, structs and local variables of structs. Possible uses for the Storage area include storing and providing access to public data such as token balances, and giving libraries access to storage variables. However, contracts cannot arbitrarily access each other’s Storage locations. The relevant opcodes for operating on Storage are the SSTORE and SLOAD opcodes, which allow writing and reading 32 bytes to and from Storage respectively.
Memory
The Memory region is a volatile, dynamically sized byte array used for storing intermediate data during the execution of a contract’s functions. It is akin to allocated virtual memory in classic execution contexts. More specifically, the Memory section holds temporary yet mutable data necessary for the execution of logic within a Solidity function. At a low-level, the MLOAD and MSTORE opcode variants are responsible for reading and writing to Memory respectively. Like Storage, data in the Memory section can be stored and read in 32-byte chunks. However, the MSTORE8 opcode can be used to write the least significant byte of a 32-byte word9.
Calldata
The Calldata region is like the Memory region in that it is also a volatile data store, however it instead stores immutable data. It is intended to hold data sent as part of a smart contract transaction10. Therefore, data stored here can include function arguments and the constructor code when creating new contracts within existing contracts. The CALLDATALOAD, CALLDATASIZE and CALLDATACOPY opcodes can be used to read Calldata at various offsets. Calldata is formatted in a specific way so that specific function arguments can be isolated from the calldata. We will go into this format in more detail later.
As data stored here is immutable, function arguments that are of simple data types such as unsigned integers are automatically copied over to Memory within a function, so that they can be modified. This does not apply to strings, arrays and maps, which need to explicitly be marked with memory or storage in function arguments, depending on whether they are to be modified during a function’s execution11.
Program Counter
The Program Counter (PC) is similar to the RIP register in x86 assembly, in that it points to the next instruction to be executed by the EVM. The PC will usually increase by one byte after an instruction has been executed. Exceptions to this include the JUMP opcode variants, which relocate the PC to positions specified by data at the top of the stack.
Global Variables
The EVM also keeps track of special variables in the global namespace. These are used to provide information about the blockchain and current contract context. There are quite a few global variables12, but you might recognize some of the following global variables from our smart contract example:
msg.sender– the address of the sender of the current call.msg.value– the value in Wei sent with the current call.msg.data– the current calldata.tx.origin– the original external account that started a transaction chain.
Return Data
The Return Data section stores the return value of a smart contract call. It is read and written to by the RETURNDATASIZE/RETURNDADACOPY and RETURN/REVERT opcodes respectively.
Gas & Beating the Solidity Compiler
Every opcode in the EVM has an opportunity cost associated with its execution. This is measured in “gas”. It is important to note that gas is not the same as Ether, in that it cannot be directly bought and sold as a native cryptocurrency. However, it is paid in Gwei (1 Gwei = 10-9 Ether). It is simply a unit of measurement for the work the EVM must do to execute a particular instruction.
Gas also exists to incentivize efficient smart contract code. To save on gas, Solidity developers sometimes write EVM assembly themselves mid-contract, by dropping into an intermediate language called Yul13. Yul is similar to literal EVM assembly; however, it allows for additional control flow (loops, conditional statements, etc.) so developers do not have to PUSH and POP their way up and down the stack. This is quite common, because Solidity is not yet a very well-established language and therefore Solidity compiler implementations are not as efficient as they could be.
The EVM execution context takes into account gas limits set for the current transaction and the gas costs for executing each opcode. Gas and gas management are complex topics in EVM development, as smart contract end users are the ones who bear the brunt of gas costs during execution. Cheaper gas costs tend to incentivize users to choose one contract over another.
For further information on gas, Section 5 of the Ethereum Yellowpaper14 is highly recommended.
In any case, while it is often necessary to drop into assembly/Yul for the sake of gas efficiency, it comes as no surprise that doing so the wrong way can have some interesting security implications. Specifically, writing contract logic in Yul/assembly can bypass some significant access control mechanisms only implemented in the higher-level Solidity, which we will demonstrate toward the end of this article.
Application Binary Interfaces
To map high-level Solidity to bytecode, the Solidity compiler generates an intermediate data structure known as an Application Binary Interface (ABI) from the contract. ABIs serve a similar role as APIs do for exposing methods and structures necessary to interact with back-end application services. Below is the ABI for our example contract:
[
{
"inputs": [
{
"internalType": "uint256",
"name": "offset",
"type": "uint256"
}
],
"name": "hitMe",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [],
"stateMutability": "nonpayable",
"type": "constructor"
},
{
"inputs": [
{
"internalType": "uint256",
"name": "_num",
"type": "uint256"
}
],
"name": "inc",
"outputs": [
{
"internalType": "uint256",
"name": "",
"type": "uint256"
}
],
"stateMutability": "pure",
"type": "function"
},
{
"inputs": [],
"name": "owner",
"outputs": [
{
"internalType": "address",
"name": "",
"type": "address"
}
],
"stateMutability": "view",
"type": "function"
}
]
ABIs are comprised of the following elements:
name: defines function names.type: defines the type of function. This is necessary to differentiate between regular functions, constructors, and specialized function types such asreceiveandfallback.inputs: an array of objects that themselves define argument names and types.- Note that both types and
internalTypesare defined. This is because there are subtle differences in the way that certain data types are referenced in Solidity versus ABIs. For example, an input of type struct in Solidity would have aninternalTypeas tuple15.
- Note that both types and
outputs: similar to inputs, the Output array includes objects that denote function return value names and types.stateMutability: denotes any function mutability attributes such aspureandview. These are needed to ascertain whether the function is intended to modify on-chain data, or is simply a getter function that returns existing values.payableandnonpayablemodifiers are also denoted here.
Data derived from an ABI is necessary to encode function calls in a low-level way that can be parsed by the EVM, which is referenced in the Calldata region in a contract’s execution context.
EVM Function Selection & Calldata
Let’s say we have compiled and deployed our bytecode to a testnet, and now we want to call a function exposed by the contract’s ABI. To do this, the EVM formats function arguments into calldata. Calldata is a standard way of representing function calls, and it is referenced in a transaction via the msg.data global variable.
Calldata is comprised of the following:
- A function selector
- Optional function arguments
Contracts expose and identify public functions by means of function selectors. Function selectors are (mostly) unique 4-byte identifiers that allow the EVM to locate and call function logic as it is represented in bytecode.
By “public functions,” we mean functions that are denoted with the public function visibility keyword in Solidity. To recap, below are the available visibility keywords for functions and state variables:
public: function is visible to contract itself, derived contracts, external contracts, and external addresses.private: function is only visible to contract itself.internal: function is visible to contract itself and derived contracts.external: function is visible to external contracts and external addresses. Not available for state variables.
Function arguments are similarly encoded along with the function selector so complete call data can be encoded. Most data types are encoded in discrete 32-byte chunks. Note that 32 bytes is the minimum; simple types like uint and bool arguments will result in 32 bytes each, whereas string, byte and array types are encoded according to their length and whether they are fixed or dynamically sized.
Consider the following function definition, called like foo(16,7):
function foo(uint64 a, uint32 b) public view returns (bool) {}
To derive calldata, the EVM does the following:
- Take the first 4 bytes of the Keccak256 hash of ASCII representation of a function, ignoring the argument variable names. This representation of a function is called a function signature.
- e.g.
keccak256(“foo(uint64,uint32)”)→0xb9821716
- For the call data, function arguments are added to the hash of the function signature, after being padded by 32 bytes. E.g.
uint64 16→0x00…..10uint32 7→0x00…..07
- Altogether, the foo function selector and calldata would be:
0xb982171600000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000000007
We can confirm this with the following short contract, which uses the abi.encodeWithSignature method to produce the function selector given the foo() function signature and its arguments. It will then emit the result (enc) in an event called Encoded. Events are a means to include additional details in transaction logs, and are useful for granularly committing specific occurrences on-chain:
pragma solidity >=0.7.0 <0.9.0;
contract AbiEncodeTest {
event Encoded(bytes);
function GetCallData() public {
bytes memory enc = abi.encodeWithSignature("foo(uint64,
uint32)", 16, 7);
emit Encoded(enc);
}
}
We will compile and deploy this contract, and then call the GetCallData method with the Brownie development environment16:
Events In This Transaction
--------------------------
└── AbiEncodeTest (0x9E4c14403d7d9A8A782044E86a93CAE09D7B2ac9)
└── Encoded
└── : 0xb982171600000000000000000000000000000000000000
00000000000000000000000010000000000000000000000000000000000000
0000000000000000000000000007
It should also be noted that public state variables are also given their own selectors and are treated as getters by the compiler17. For instance, a public state variable named owner will have a selector exposed as keccak256(“owner()”) = 0x8da5cb5b. It can be accessed from other contracts that import DodgyProxy as DodgyProxy.owner().
If the bytecode of the AbiEncodeTest and DodgyProxy contracts were compared, a common section of bytecode will be present, shown below in green. The 4-byte function selectors for the GetCallData() and hitMe() functions immediately follow this common section of bytecode:
AbiEncodeTest: …60003560e01c806301cc20f114602d57…
DodgyProxy: …60003560e01c806373c768d71461004657…
This bytecode represents the function selection logic that the EVM uses to identify public functions. The following opcodes are responsible for function selection in DodgyProxy:
026→ 60→ PUSH1 0x00
028→ 35→ CALLDATALOAD
029→ 60→ PUSH1 0xe0
031→ 1C→ SHR
032→ 80→ DUP1
033→ 63→ PUSH4 0x73c768d7 // hitMe(uint256) public function selector
038→ 14→ EQ
039→ 61→ PUSH2 0x0046
042→ 57→ *JUMPI
043→ 80→ DUP1
044→ 63→ PUSH4 0x812600df // inc(uint256) public function selector
049→ 14→ EQ
050→ 61→ PUSH2 0x005b
053→ 57→ *JUMPI
054→ 80→ DUP1
055→ 63→ PUSH4 0x8da5cb5b // owner getter function selector
060→ 14→ EQ
061→ 61→ PUSH2 0x0081
064→ 57→ *JUMPI
Let’s follow execution of this bytecode snippet, given calldata for the following function call. Below is the call we will make to inc() with an argument of uint256 of 1:
inc(1);
Running this function call through the GetCallData function in the AbiEncodeTest contract will result in the following calldata. This can also be derived manually following the same method we went through earlier:
812600df0000000000000000000000000000000000000000000000000000000000000001
If you want to follow along, smlXL18 has a brilliant EVM playground, where bytecode execution can be modeled for learning and debugging purposes. You may follow along with the function selection logic bytecode here, given calldata for a call to inc(uint256) with an argument of 1.
First, the PUSH1 opcode pushes a value of 0x00 to the stack. This value functions as an offset for the next opcode, CALLDATALOAD:

CALLDATALOAD loads the first 32 bytes of the msg.data global variable to the stack. Here we can see that the function selector for inc(uint256) is included in these first 32 bytes:

However, the EVM now needs to parse out the 4-byte function selector from the rest of the calldata chunk. The EVM currently carries this out by bitshifting the calldata chunk to the right by some amount to be left with only the 4-byte function selector. Since the calldata chunk is 256 bits (32 bytes), it needs to be shifted right by 224 bits (0xE0 in hex).
This is done by first pushing 0xE0 to the stack with PUSH1, and shifting right by SHR. After the shift, the offset will be popped, leaving the clean function selector as the sole element in the stack:

Selecting a Function
To understand the significance of the next few bytecodes, it is helpful to know that the EVM compares function selectors as a kind of switch statement, where function selectors are piled on top of each other on the stack before being compared to the function selector below it. In doing so, the EVM is attempting to discover if incoming calldata is targeting a valid function by parsing them sequentially looking for a match.
This is why the DUP1 opcode is used to duplicate the function selector on the stack before the next function selector is pushed to the stack with the PUSH4 opcode. Note that this function selector is not derived from any calldata; it is the first function selector to be placed on the stack by the EVM itself. Here, the function selector for the hitMe(uint256) (0x73c768d7) function will eventually be pushed:

The EQ opcode is then used to compare the last two items on the stack. If a match is found, the last two items are popped off the stack and a value of 1 replaces them as a positive comparison result. If not, then a value of 0 replaces them instead.
Here, a value of 0 will be pushed to the stack as 0x812600df and 0x73c768d7 do not match. Note that the original function selector derived from our calldata still remains below the comparison result, ready to eventually be compared to the next function selector:


Now that a result has been found, a decision needs to be made as to whether to execute the function represented by the function selector. In this case, function execution will not occur yet because the calldata’s function selector does not match the first one encountered by the EVM.

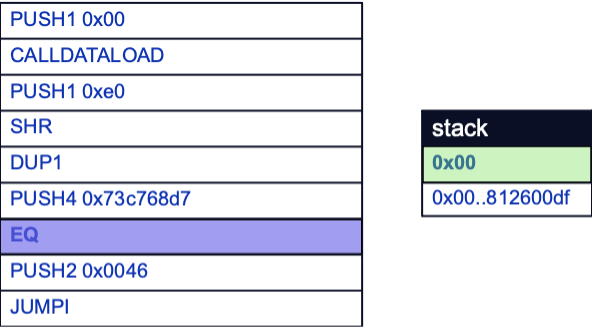
However, the EVM presently still needs to make another comparison to decide whether to jump to the function selector’s corresponding function logic before it can start comparing the next function selector. This comparison is done by first pushing an offset to the start of function logic to the stack with the PUSH2 opcode.

The JUMPI opcode is then used. Note that JUMPI represents a conditional jump, whereas the JUMP instruction only requires an offset to jump to and is used when an unconditional jump is necessary. The JUMPI instruction first pops the offset and result of the EQ comparison off the stack. If the comparison result is 1, then the program counter will be changed to the offset, which denotes the start of the function logic to be executed. Here, the comparison result is 0, so execution will continue without changing the program counter.
The previous bytecode is then more or less repeated from the DUP1 opcode: duplicating the calldata-derived function selector, pushing the next function selector to be compared on the stack, comparing the two function selectors, placing an offset to the next section of function logic, and then deciding whether to jump to said function logic depending on the outcome of the comparison.
This is shown below. This time, the inc(uint256) function selector is compared, so execution will continue at offset 0x5B (91) in the bytecode.
Jumpdests
If we follow execution past the function selection logic, the first opcode we land on will be the JUMPDEST opcode, found at position 91 in the bytecode.
091→ 5B→ JUMPDEST
092→ 61→ PUSH2 0x006e
095→ 61→ PUSH2 0x0069
098→ 36→ CALLDATASIZE
099→ 60→ PUSH1 0x04
101→ 61→ PUSH2 0x0178
104→ 56→ JUMP
105→ 5B→ JUMPDEST
Think of JUMP and JUMPDEST opcodes are opposite ends of a wormhole from one area in the bytecode to another. Every JUMP opcode must have a corresponding “landing” JUMPDEST for the jump to be valid. JUMPDESTs remove the need to dynamically assess starting points for function logic after a jump has been taken.
It should also be noted that JUMPDESTs do not only denote the start of function logic. In fact, there seems to be little bearing over the placement of function logic in low-level bytecode versus high level Solidity.
Aside – Function Signature Clashing
Note: OpenZeppelin has a great post on this rare but interesting EVM quirk.
Earlier, we referred to function selectors as “mostly” unique because it is not too uncommon to have two or more distinct functions with the same first four bytes of the keccak256 hash of the function name. The Ethereum Signature Database is a great example of this. The selector for the owner state variable getter function is actually the same as the function selector for ideal_warn_timed(uint256,uint128), 0x8da5cb5b19.
The Solidity compiler is sophisticated enough to notice function signature clashes, so long as the relevant functions are in a single contract. In theory however, function signature clashes are possible between distinct contracts, such as between an implementation contract and a well-known pattern known as a proxy contract20. Potential security risks associated with proxy contract usage will be covered in a subsequent post.
Private/Internal Functions
Only public and external functions will have function signatures created for them. Private and internal functions do not receive function selectors. For example, a function selector for deleg() is not present in the bytecode. In fact, attempting to execute a private or internal function via Web3.py or similar will not result in any sort of access error. Rather explicitly, an exception will be raised as the function selector does not exist21:
import web3
from solcx import compile_source
# make sure you have a network provider, Ganache is good for this
w3 = web3.Web3(web3.HTTPProvider('https://127.0.0.1:8545'))
compiled_sol = compile_source(
'''
pragma solidity >=0.7.0 <0.9.0;
contract DodgyProxy {
address public owner;
constructor() {
owner = msg.sender;
}
modifier onlyOwner {
require(msg.sender == owner, "not owner!");
_;
}
function deleg() private onlyOwner {
address(msg.sender).delegatecall("");
}
struct Pointer { function () internal fwd; }
function hitMe(uint offset) public {
Pointer memory p;
p.fwd = deleg;
assembly { mstore(p, add(mload(p), offset)) }
p.fwd();
}
function inc(uint _num) public pure returns (uint) {
return _num++;
}
}''', output_values=['abi', 'bin'])
contract_id, contract_interface = compiled_sol.popitem()
w3.eth.default_account = w3.eth.accounts[0]
Proxy = w3.eth.contract(abi=contract_interface['abi'],
bytecode=contract_interface['bin'])
# will succeed, as hitMe is public
pub = Proxy.get_function_by_name("hitMe")
print(pub)
try:
# will fail, as cannot find deleg
priv = Proxy.get_function_by_name("deleg")
except ValueError as v:
print("%s: deleg" %v)
Running the above script will result in:
❯ python3 web3_check.py
<Function hitMe(uint256)>
Could not find any function with matching name: deleg
However, a lack of function selectors for private/internal functions does not mean that private function logic is inaccessible internally, as private function logic still needs to be executable by the contract.
At present, the following contract is valid Solidity, if somewhat redundant. A public function can make calls to private functions within the same contract and handle any results without issue:
pragma solidity >=0.7.0 <0.9.0;
contract Pubpriv {
function priv() private returns (uint) {
return 1;
}
function pub() public returns (uint) {
return priv();
}
}
Going back to our DodgyProxy, a similar pattern might be clear now, starting from hitMe():
function deleg() private onlyOwner {
address(msg.sender).delegatecall("");
}
struct Pointer { function () internal fwd; }
function hitMe(uint offset) public {
Pointer memory p;
p.fwd = deleg;
assembly { mstore(p, add(mload(p), offset)) }
p.fwd();
}
When executing the hitMe() function as any account other than the contract owner, it is not possible to directly call the private deleg() function from hitMe() due to the custom onlyOwner modifier, which prevents the private function logic from being executed if the owner state variable is not set to the caller’s address (msg.sender).
However, a not-so subtle memory corruption vulnerability of sorts has been introduced in the assembly block. If the hitMe() function is given the right input, it is possible to end up in the middle of the deleg() function and resume execution, despite the deleg() function being inaccessible due to the onlyOwner modifier, and restricted from being called externally due to the private function visibility.
This is because function visibility, and indeed modifiers in general, only function as definitive access control in high-level Solidity. Meaning that if execution is somehow redirected to the middle of a private function, there is no kind of DEP/NX-like mechanism for preventing execution by unauthorized contexts.
The conditions necessary for this kind of flaw to be exploitable are unlikely to present themselves in the most cases. Such occurrences are not outside the realm of possibility however, especially considering how often Yul is used to write low-level EVM opcodes directly into contracts to encode operations in such a way as to save on gas fees versus the compiler’s own bytecode.
With that in mind, the general idea behind this flaw is that the Pointer struct essentially functions as a “base” of sorts in memory, from which an offset can be added to. By specifying specific offsets, the struct’s fwd() function can be used as a jump pad to various JUMPDESTs, some of which would belong to function logic that would otherwise be prevented from being executed via conventional control flow in high-level Solidity. To understand more about how memory is referenced during bytecode execution, the Memory section of the EVM call context needs to be revisited in more detail.
More About Memory
As a dynamically sized byte array, the Memory area of the EVM call context can be read and written to in discrete 32-byte chunks. There is also the concept of “touched” and “untouched” memory, where newly written chunks of memory accrue increasing gas and storage costs22. Before new memory can be utilized, the EVM needs to retain a section of utility memory that is used to keep track of subsequent memory writes.
This utility memory is comprised of four main sections, starting from the beginning of the Memory array23:
- bytes
0x00-0x3f: scratch space mainly used to store intermediate outputs from hashing operations such askeccak256(). Note that this section is allocated as two 32-byte slots. - bytes
0x40-0x5f: space reserved for the 32-byte “free memory pointer.” This is used as a pointer to unallocated memory for use during contract execution. - bytes
0x60-0x7f: the 32-byte “zero slot,” which is used as a volatile storage space for dynamic memory arrays which should not be written to.
Initially, the free memory pointer points to position 0x80 in memory, after which point additional memory can be assigned without overwriting memory that has already been allocated to other data. As such, the free memory pointer also functions as the currently allocated memory size.

Exploiting the first vulnerability in the smart contract is contingent on manipulating the value of the free memory pointer to redirect control flow and eventually end up in the middle of the protected deleg() function. It is useful to follow along with the execution of the DodgyProxy contract in the Remix IDE to understand the next sections.
First, compile the contract with an optimization value of 200 and a compiler version of 0.8.17. Changing optimization settings and compiler versions may increase or decrease the offsets slightly, but the general bytecode logic should remain consistent regardless of optimization. Optimization was chosen as the standalone Solc compiler enabled optimization by default24, whereas Remix does not enable optimization by default.
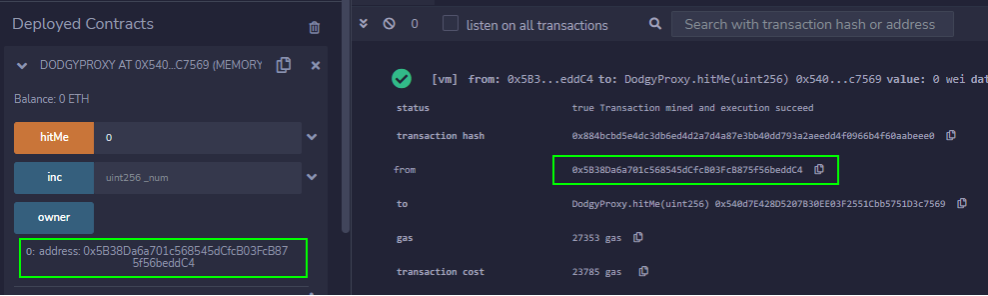
Deploy the contract using any account. Then, attempt to call the hitMe() function with an argument of 0, using the same account that was used to deploy the contract (0x5B38Da6a701c568545dCfcB03FcB875f56beddC4). This will result in a successful function call:
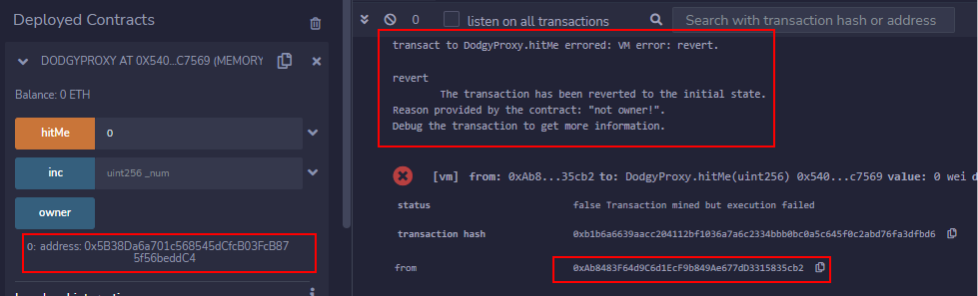
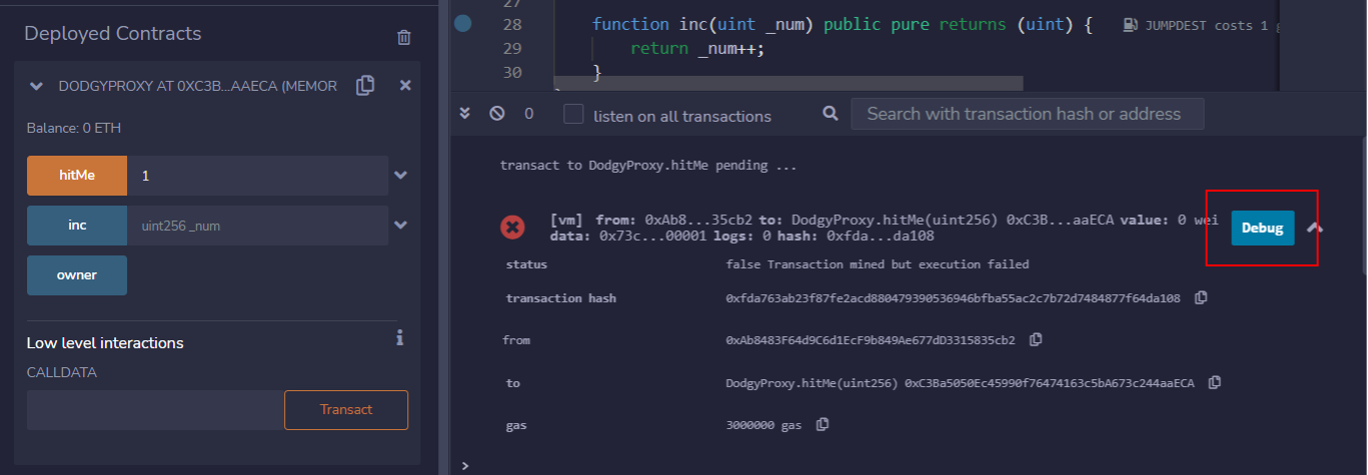
Then attempt to do the same as any account other than the contract owner. Here, account 0xAb8483F64d9C6d1EcF9b849Ae677dD3315835cb2 was used, representing the address of a malicious actor. The transaction will revert:
From the attacker’s account, make call to the hitMe() function with an argument of 1 uint and debug the failed transaction:
Execution starts with the values 0x80 and 0x40 being pushed to the stack:
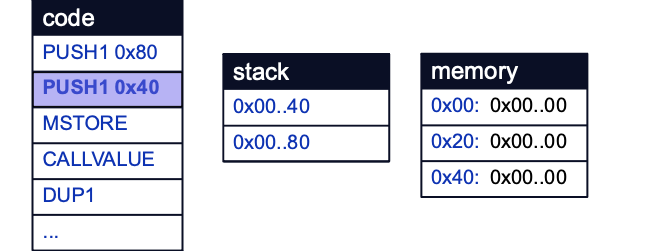
The free memory pointer is then initialized by the MSTORE operation, which stores the value 0x80 at memory location 0x40.

Then, place a breakpoint at the initialization of the Pointer struct on line 22 and continue execution:
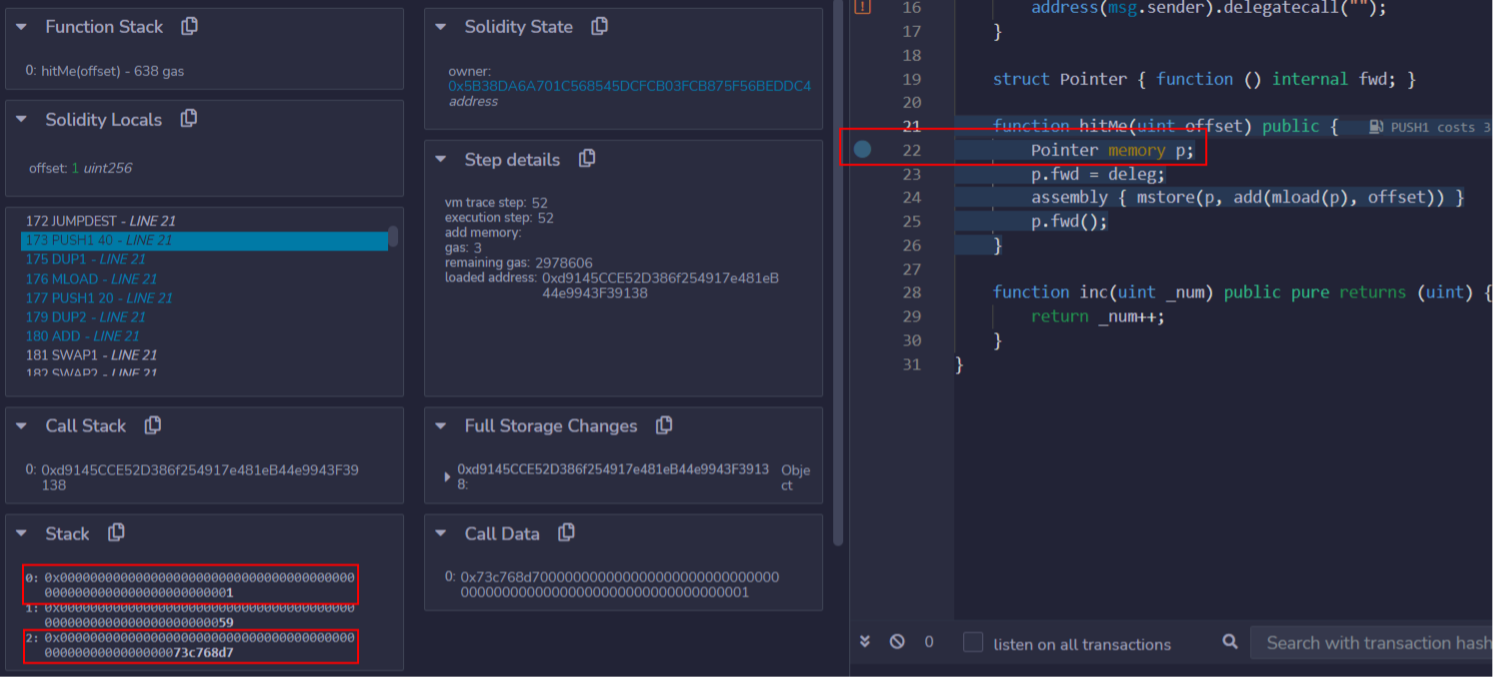
Execution until this breakpoint will involve many operations, including the function selection logic described earlier. Once the breakpoint is reached, the stack is seen to contain some familiar values, namely the function selector for hitMe(uint256), and an argument of 1:
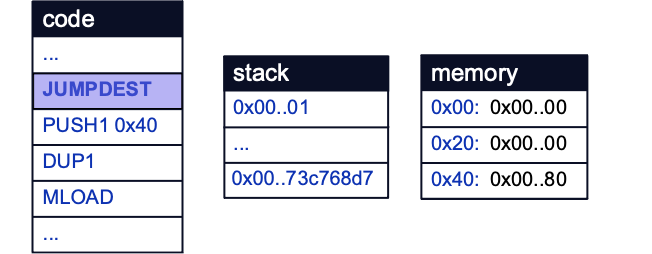
Place a second breakpoint at the start of the assembly block on line 24 and continue execution. A value of 0xE2 is eventually pushed to the stack:
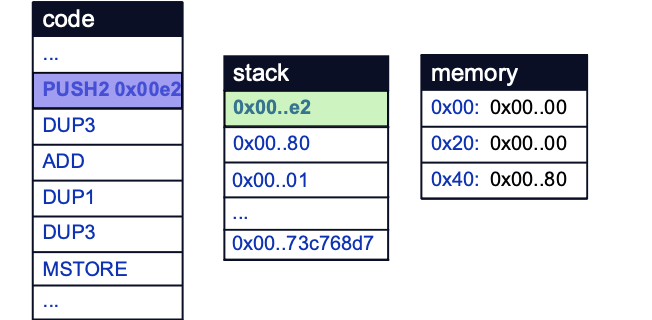
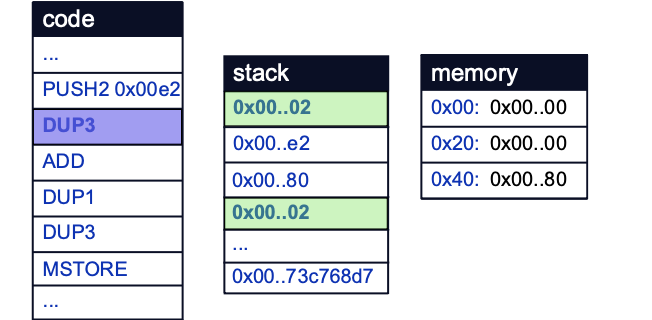
The third value on the stack, 0x01, is then duplicated to the top of the stack by the DUP3 opcode.
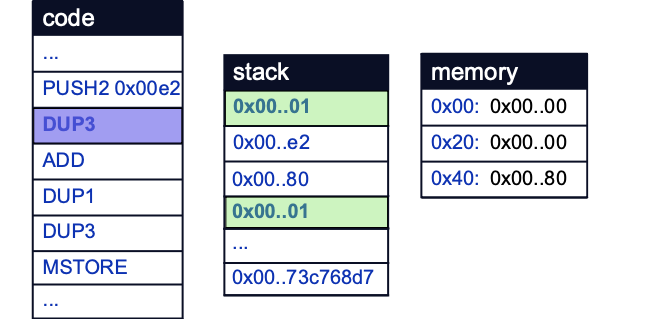
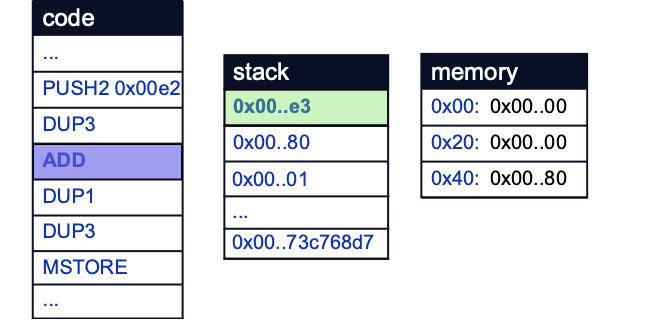
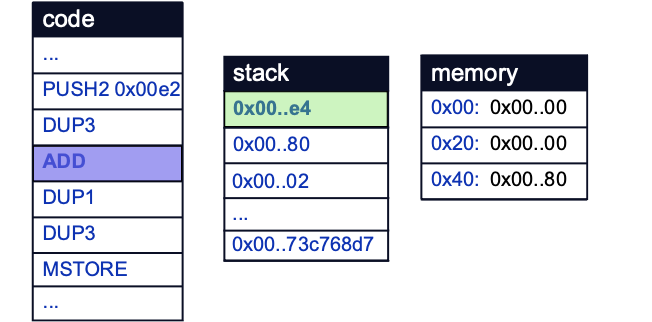
The ADD opcode then adds 0x01 to 0xE2 and stores 0xE3 on the stack. Note that the bytecode generated from the compiler will differ slightly from the exact assembly due to compiler optimizations and translations from Yul:
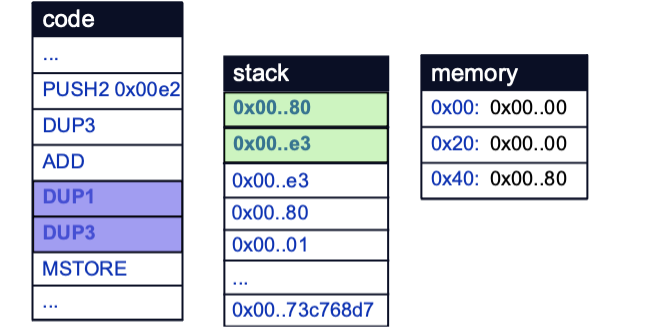
The last two arguments on the stack are then duplicated by the DUP1 and DUP3 opcodes, in preparation for the MSTORE opcode to store value 0xE3 at memory location 0x80:
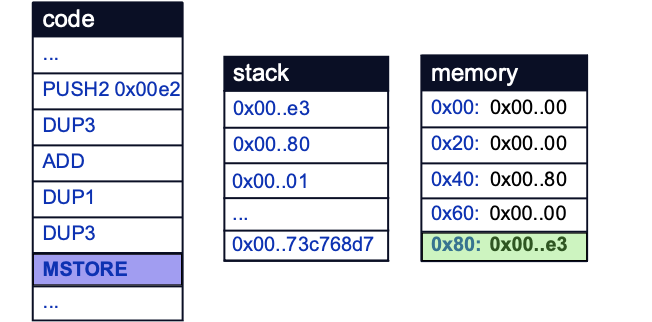
This follows the logic of the assembly block on line 24. Therefore, the value that was just stored at the free memory pointer is most likely the location in memory of the Pointer struct first instantiated on line 26.
Repeating these debugging steps by sending calldata of hitMe(2) will confirm this, as the free memory pointer will now store a value of 0xE4, one more than our previous value owing to the incremented offset argument to hitMe():
Continuing execution with arbitrary arguments to the hitMe() function will result in a failed transaction, as a JUMP will eventually be made to an invalid location in the bytecode. However, with granular control over the value at the free memory pointer, an offset can be calculated to bypass access control modifiers protecting the deleg() function.
To do this, the contract’s bytecode can be examined for opcodes that correspond to sections of high-level Solidity that we would want to end up in. This is simple in this case, as the correct section of bytecode will have the only DELEGATECALL opcode, since it is only called once in this contract:
301→ →
302→ →
304→ →
305→ →
306→ →
307→ →
309→ →
310→ →
311→ →
312→ →
313→ →
314→ →
However, recall from earlier that for control flow to be altered by means of a jump, a corresponding JUMPDEST opcode must be present at the target location, just as with normal function selection. This is why the challenge was set up as a struct with an internal function.
Without a means to set a function call, it would be much more difficult — if not practically impossible — to jump to another section of bytecode to break normal control flow. For this reason, this technique is also only likely to work if there are no opcodes between the JUMPDEST we land on and the target opcodes that interfere with execution.
In this case, there does not appear to be any opcodes that would prevent us from eventually executing the DELEGATECALL operation. From here, the offset to take can easily be calculated by subtracting the location in memory of the Pointer struct from the offset in the contract bytecode of the nearest preceding JUMPDEST from the DELEGATECALL opcode.
In our bytecode, the target JUMPDEST is found at offset 0x012D (301) in our bytecode. The location of the Pointer struct is at 0xE2 (226). This gives a difference of 0x4B (75). This difference is added to the Pointer struct base in subsequent bytecode, before a jump is made to the JUMPDEST at 0x12D:
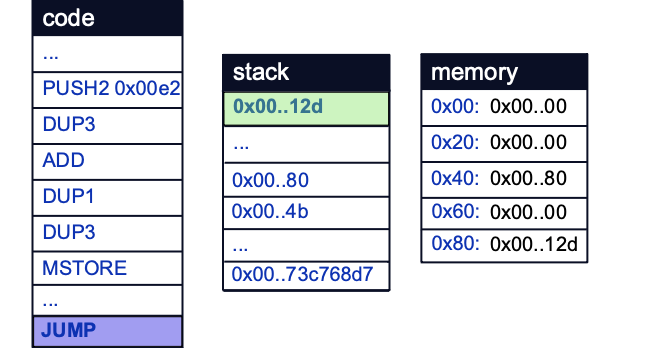
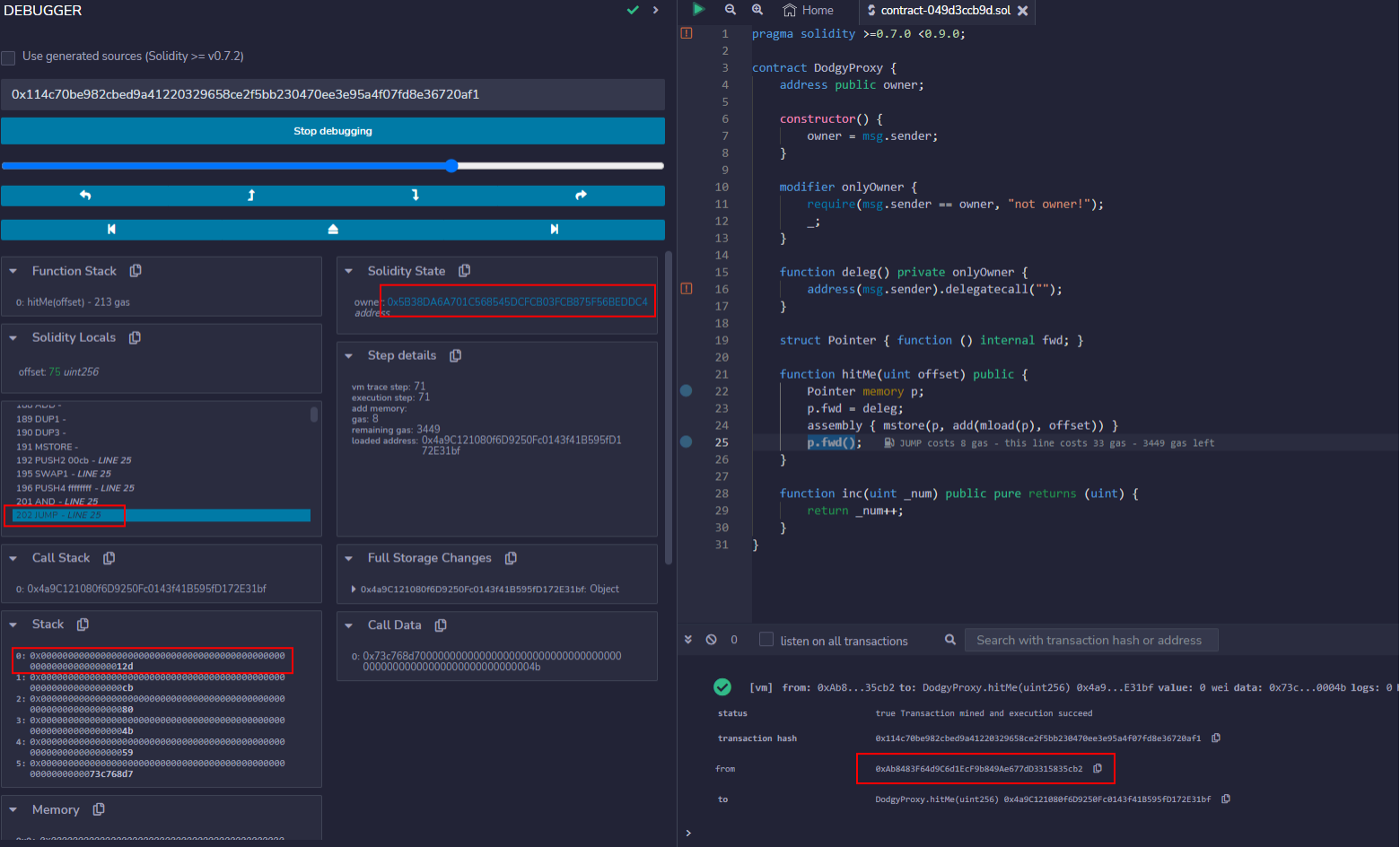
We can confirm that the delegatecall is then reached by stepping through by placing a breakpoint at the line with the delegatecall and calling the hitMe() function with an argument of 75. Execution will proceed to the delegatecall:
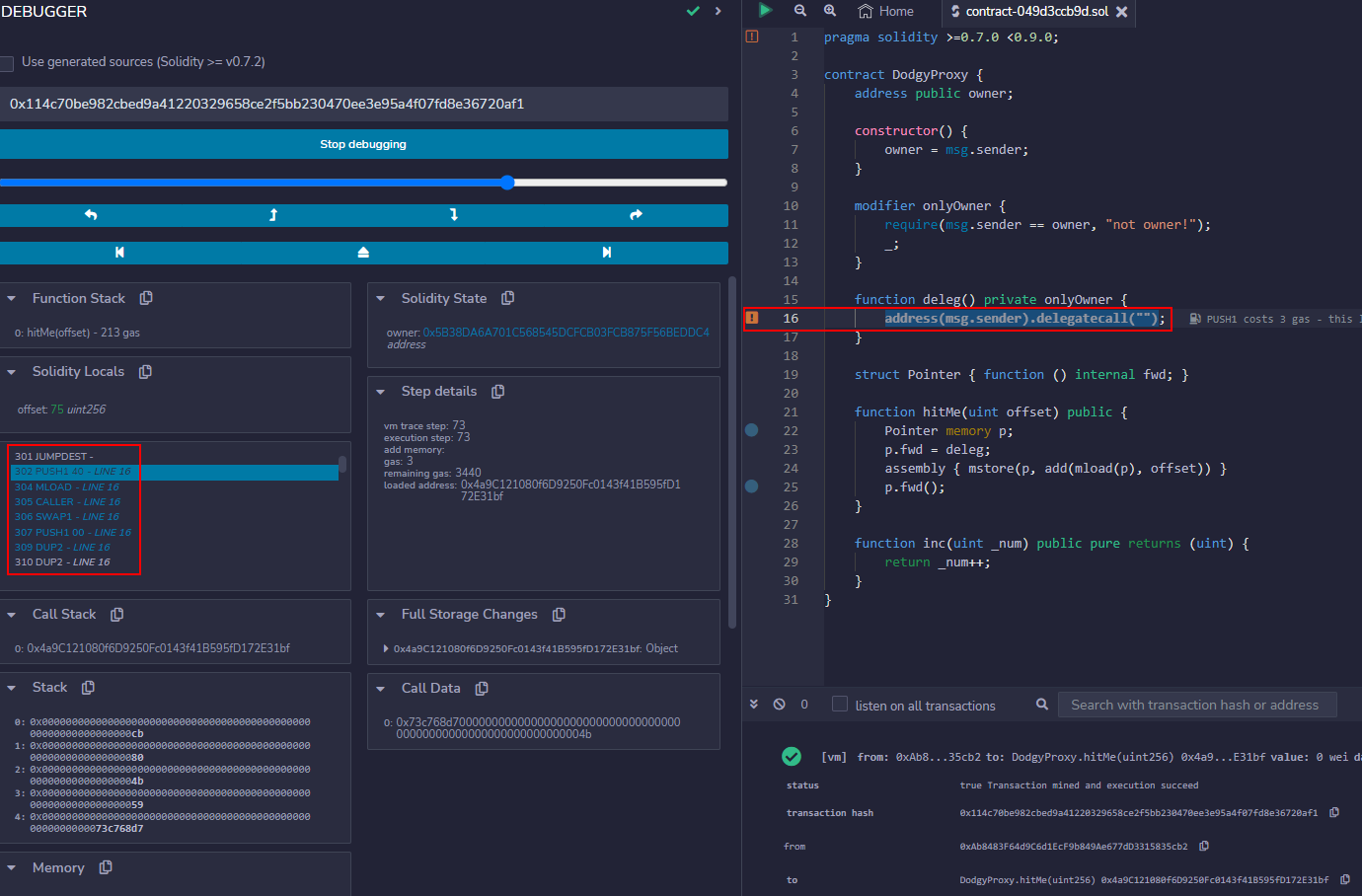
At this point, we have successfully bypassed the onlyOwner modifier. To complete the challenge however, we need to take ownership of the contract by abusing the delegatecall to overwrite the owner state variable. If you have a bit of experience with Solidity, this should be relatively simple.
That’s all for this article. In Part 2 of this installment, we will go into more detail on storage layout in the EVM. Part 3 will contain a detailed look at low-level contract calls, proxy contracts, and a few more examples of how DELEGATECALL can be abused to subvert control flow and take ownership of contracts.

References
- https://ethereum.org/en/developers/docs/evm/
- https://noxx.substack.com/p/evm-deep-dives-the-path-to-shadowy
- https://medium.com/authio/solidity-ctf-part-2-safe-execution-ad6ded20e042
- https://www.evm.codes/
- https://cypherpunks-core.github.io/ethereumbook/13evm.html
Citations
- https://ethereum.org/en/developers/docs/transactions/
- https://github.com/ethereum/go-ethereum
- https://github.com/ethereum/py-evm
- https://docs.vyperlang.org/en/stable/
- https://web.archive.org/web/20220802005328/https://ropsten.etherscan.io/address/
0x727c1c8d4b190d208f3701f106f7301cb1a32f27#contracts - https://us.reddit.com/r/ethdev/comments/8td9xn/challenge_empty_the_contract_of_funds/
- https://docs.soliditylang.org/en/v0.8.17/using-the-compiler.html#optimizer-options
- https://docs.soliditylang.org/en/v0.8.17/introduction-to-smart-contracts.html#storage-memory-and-the-stack
- https://www.evm.codes/#53
- https://docs.soliditylang.org/en/v0.8.17/internals/layout_in_calldata.html#layout-of-call-data
- https://docs.soliditylang.org/en/v0.8.17/types.html#value-types
- https://docs.soliditylang.org/en/v0.8.17/cheatsheet.html#global-variables
- https://docs.soliditylang.org/en/latest/yul.html
- https://ethereum.github.io/yellowpaper/paper.pdf
- https://docs.soliditylang.org/en/latest/abi-spec.html#mapping-solidity-to-abi-types
- https://github.com/eth-brownie/brownie
- https://docs.soliditylang.org/en/latest/contracts.html#state-variable-visibility
- https://blog.smlxl.io/
- https://www.4byte.directory/signatures/?bytes4_signature=0x8da5cb5b
- https://eips.ethereum.org/EIPS/eip-1167
- You will need a local Ethereum test net provider, along with the
web3.pyandsolcxpackages. - https://eips.ethereum.org/EIPS/eip-3336#changes-to-memory-expansion-gas-cost
- https://docs.soliditylang.org/en/v0.8.17/internals/layout_in_memory.html
- https://docs.soliditylang.org/en/latest/internals/optimizer.html




















