
Ryan Wakeham
- It’s a gold mine for sensitive data, including social security numbers, payment information, birth certificates, addresses, and more. While monetizing such data may require additional effort on the part of cybercriminals, breaches of such data is a major HIPAA compliance violation that can result in heavy fines and could also potentially have a negative impact to patients if their data is leaked.
- The criticality of the business is as high-risk as it gets. In other words, hospitals cannot afford downtime. Add a public health pandemic to the mix and the criticality increases drastically.
This sense of urgency to get systems back up and running quickly is a central reason why Ryuk is targeting the industry now. Hospitals are more likely to pay a ransom due to the potential consequence downtime can have on the organization and its patients.
Ransomware, Ryuk, and TrickBot:
To understand Ryuk, it is important to first understand ransomware attacks at a fundamental level. Ransomware gains access to a system only after a trojan or ‘botnet’ finds a vulnerable target and gains access first. Trojans gain access often through phishing attempts (spam emails) with malicious links or attachments (the payload). If successful, the trojan installs malware onto the target’s network by sending a beacon signal to a command and control server controlled by the attacker, which then sends the ransomware package to the Trojan.
In Ryuk’s case, the trojan is TrickBot. In this case, a user clicks on a link or attachment in an email, which downloads the TrickBot Trojan to the user’s computer. TrickBot then sends a beacon signal to a command and control (C2) server the attacker controls, which then sends the Ryuk ransomware package to the victim’s computer.
Trojans can also gain access through other types of malware, unresolved vulnerabilities, and weak configuration, though, phishing is the most common attack vector. Further, TrickBot is a banking Trojan, so in addition to potentially locking up the network and holding it for ransom, it may also steal information before it installs the ransomware.
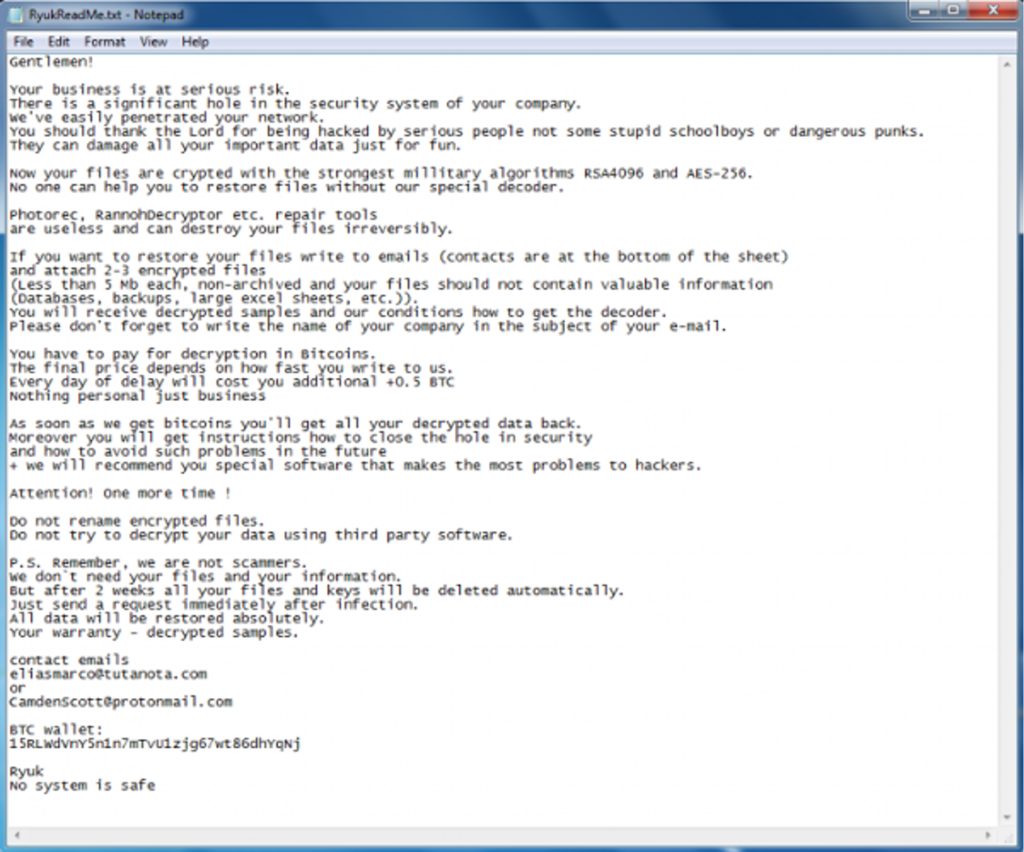
How does an organization know if they have fallen victim to ransomware, more specifically Ryuk? It will be obvious if Ryuk has successfully infiltrated a system. It will take over a desktop screen and a ransom note will appear with details on how to pay the ransom via bitcoin:
An early warning sign of a ransomware attack is that at the technical level, your detective controls, if effective, should alert to Indicators of Compromise (IoC). Within CISA’s alert, you can find TrickBot IoCs listed along with a table of Ryuk’s MITRE ATT&K techniques.
A threat to the increasing remote workforce: In order to move laterally throughout the network undetected, Ryuk relies heavily on native tools, such as Windows Remote Management and Remote Desktop Protocol (RDP). Read: COVID-19: Evaluating Security Implications of the Decisions Made to Enable a Remote Workforce
Implementing Proactive Cyber Security Strategies to Thwart Ransomware Attacks
We mentioned at the start of this post that one of the things organizations can do preemptively to protect themselves is to put in place proactive security strategies. While important, security awareness only goes so far, as humans continue to be the greatest cyber security vulnerability. Consider this: In past NetSPI engagements with employee phishing simulations, our click-rates, or fail-rates, were down to 8 percent. This is considered a success, but still leaves open opportunity for bad actors. It only takes one person to interact with a malicious attachment or link for a ransomware attack to be successful.
Therefore, we support defense-in-depth as the most comprehensive strategy to prevent or contain a malware outbreak. Here are four realistic defense-in-depth tactics to implement in the near- and long-term to prevent and mitigate ransomware threats, such as Ryuk:
- Revisit your disaster recovery and business continuity plan. Ensure you have routine and complete backups of all business-critical data at all times and that you have stand-by, or ‘hot,’ business-critical systems and applications (this is usually done via virtual computing). Perform table-top or live disaster recovery drills and validate that ransomware wouldn’t impact the integrity of backups.
- Separate critical data from desktops, avoid siloes: Ryuk, like many ransomware strands, attempts to delete backup files. Critical patient care data and systems should be on an entirely separate network from the desktop. This way, if ransomware targets the desktop network (the most likely scenario) it cannot spread to critical hospital systems. This is a long-term, and challenging, strategy, yet well worth the time and budgetary investment as the risk of critical data loss will always exist.
- Take inventory of the controls you have readily available – optimize endpoint controls: Assess your existing controls, notably email filtering and endpoint controls. Boost email filtering processes to ensure spam emails never make it to employee inboxes, mark incoming emails with a banner that notifies the user if the email comes from an external source, and give people the capability to easily report suspected emails. Endpoint controls are essential in identifying and preventing malware. Here are six recommendations for optimizing endpoint controls:
- Confirm Local Administrator accounts are strictly locked down and the passwords are complex. Ensure Domain Administrator and other privileged accounts are not used for routine work, but only for those tasks that require admin access.
- Enable endpoint detection and response (EDR) capabilities on all laptops and desktops.
- Ensure that every asset that can accommodate anti-malware has it installed, including servers.
- Apply all security patches for all software on all devices. Disable all RDP protocol access from the Internet to any perimeter or internal network asset (no exceptions).
- Test your detective controls, network, and workstations:
- Detective control testing with adversarial simulation: Engage in a purple team exercise to determine if your detective controls are working as designed. Are you able to detect and respond to malicious activity on your network?
- Host-based penetration testing: Audit the build of your workstations to validate that the user does have least privilege and can only perform business tasks that are appropriate for that individual’s position.
- Internal network penetration testing: Identify high impact vulnerabilities found in systems, web applications, Active Directory configurations, network protocol configurations, and password management policies. Internal network penetration tests also often include network segmentation testing to determine if the controls isolating your crown jewels are sufficient.

Finally, organizations that end up a victim to ransomware have three options to regain control of their systems and data.
- Best option: Put disaster recovery and business continuity plans in motion to restore systems. Also, perform an analysis to determine the successful attack vector and remediate associated vulnerabilities.
- Not advised: Pay the ransom. A quick way to get your systems back up and running, but not advised. There is no guarantee that your business will be unlocked (in fact, the offer may also be ransomware), so in effect you are funding adversarial activities and it’s likely they will target your organization again.
- Rare cases: Cracking the encryption key, while possible with immature ransomware groups, is often unlikely to be successful. Encryption keys have become more advanced and require valuable time to find a solution.
For those that have yet to experience a ransomware attack, we encourage you to use the recent Ryuk news as a jumping point to future-proof your security processes and prepare for the inevitability of a breach. And for those that have, now is the time to reevaluate your security protocols.
[post_title] => Healthcare’s Guide to Ryuk Ransomware: Advice for Prevention and Remediation [post_excerpt] => Making its debut in 2018, the Ryuk ransomware strand has wreaked havoc on hundreds of businesses and is responsible for one-third of all ransomware attacks that took place in 2020. [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => healthcares-guide-to-ryuk-ransomware-advice-for-prevention-and-remediation [to_ping] => [pinged] => [post_modified] => 2021-05-04 17:06:19 [post_modified_gmt] => 2021-05-04 17:06:19 [post_content_filtered] => [post_parent] => 0 [guid] => https://www.netspi.com/?p=20466 [menu_order] => 454 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [1] => WP_Post Object ( [ID] => 1145 [post_author] => 16 [post_date] => 2013-09-22 07:00:17 [post_date_gmt] => 2013-09-22 07:00:17 [post_content] =>For as long as I can remember, security professionals have spent the majority of their time focusing on preventative controls. Things like patching processes, configuration management, and vulnerability testing all fall into this category. The attention is sensible, of course; what better way to mitigate risk than to prevent successful attacks in the first place?
However, this attention has been somewhat to the detriment of detective controls (I’m intentionally overlooking corrective controls). With budget and effort being concentrated on the preventative, there is little left over for the detective. However, in recent years, we have seen a bit of a paradigm shift; as organizations have begun to accept that they cannot prevent every threat agent, they have also begun to realize the value of detective controls.
Some may argue that most organizations have had detective controls implemented for years and, technically speaking, this is probably true. Intrusion detection and prevention systems (IDS/IPS), log aggregation and review, and managed security services responsible for monitoring and correlating events are nothing new. However, in my experience, these processes and technologies are rarely as effective as advertised (IDS/IPS can easily be made ineffective by the noise of today’s networks, logs are only worth reviewing if you’re collecting the right data points, and correlation and alerting only works if it’s properly configured) and far too many companies expect plug-and-play ease of use.
Detective controls should be designed and implemented to identify malicious activity on both the network and endpoints. Just like preventative controls, detective controls should be layered to the extent possible. A good way to design detective controls is to look at the steps in a typical attack and then implement controls in such a way that the key steps are identified and trigger alerts.
Below is a simplified example of such an approach:
| Attack Step | Key Detective Control |
|---|---|
| Gain access to restricted network (bypass network access control) | Network access control alerts for unauthorized devices |
| Discover active systems and services | IDS / IPS / WAF / HIPS; activity on canary systems that should never be accessed or logged into |
| Enumerate vulnerabilities | IDS / IPS / WAF / HIPS; activity on canary systems that should never be accessed or logged into |
| Test for common and weak passwords | Correlation of endpoint logs (e.g., failed login attempts, account lockouts); login activity on canary accounts that should never be used |
| Execute local system exploit | Anti-malware; monitoring of anti-malware service state; FIM monitoring security-related GPO and similar |
| Create accounts in sensitive groups | Audit and alert on changes to membership in local administrator group, domain admin group, and other sensitive local and domain groups |
| Access sensitive data | Logging all access to sensitive data such as SharePoint, databases, and other data repositories |
| Exfiltrate sensitive data | Data leakage prevention solution; monitor network traffic for anomalies including failed outbound TCP and UDP connections |
This example is not intended to be exhaustive but, rather, in meant to illustrate the diversity of detective controls and the various levels and points at which they can be applied.
While every environment is slightly different, the general rules remain the same: implementing controls to detect attacks at common points will greatly increase the efficacy of detective controls while still sticking within a reasonable budget. The one big caveat in all of this is that, in order to be truly effective, detective controls need to be tuned to the environment; no solution will perform optimally right out of the box. At the end of the day, proper application of detective controls will still cost money and require resources. However, the impact of an attack will be reduced substantially through strong detective controls.
[post_title] => The Value of Detective Controls [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => the-value-of-detective-controls [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:05:21 [post_modified_gmt] => 2021-04-13 00:05:21 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1145 [menu_order] => 739 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [2] => WP_Post Object ( [ID] => 1181 [post_author] => 16 [post_date] => 2012-12-12 07:00:26 [post_date_gmt] => 2012-12-12 07:00:26 [post_content] => The Georgia Tech Information Security Center and Georgia Tech Research Institute recently released their 2013 report on emerging cyber threats. Some of these threats are fairly predictable, such as cloud-based botnets, vulnerabilities in mobile browsers and mobile wallets, and obfuscation of malware in order to avoid detection. However, some areas of focus were a bit more surprising, less in a revelatory sense and more simply because the report specifically called them out. One of these areas is supply chain insecurity. It is hardly news that counterfeit equipment can make its way into corporate and even government supply chains but, in an effort to combat the threat, the United States has redoubled efforts to warn of foreign-produced technology hardware (in particular, Chinese-made networking equipment). However, the report notes that detecting counterfeit and compromised hardware is a difficult undertaking, particularly for companies that are already under the gun to minimize costs in a down economy. Despite the expense, though, the danger of compromise of intellectual property or even critical infrastructure is very real and should not be ignored. Another interesting focus of the report is healthcare security. The HITECH Act, which was enacted in 2009, provided large incentives for healthcare organizations to move to electronic systems of medical records management. While the intent of this push was to improve interoperability and the level of patient care across the industry, a side effect is a risk to patient data. The report notes what anyone who has dealt with information security in the healthcare world already knows: that healthcare is a challenging industry to secure. The fact that the report calls out threats to health care data emphasizes the significance of the challenges in implementing strong controls without impacting efficiency. Addressing the threats of information manipulation, insecurity of the supply chain, mobile security, cloud security, malware, and healthcare security, the report is a recommended read for anyone in the information security field. The full report can be found at: https://www.gtsecuritysummit.com/pdf/2013ThreatsReport.pdf [post_title] => 2013 Cyber Threat Forecast Released [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => 2013-cyber-threat-forecast-released [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:05:59 [post_modified_gmt] => 2021-04-13 00:05:59 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1181 [menu_order] => 778 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [3] => WP_Post Object ( [ID] => 1189 [post_author] => 16 [post_date] => 2012-10-15 07:00:26 [post_date_gmt] => 2012-10-15 07:00:26 [post_content] => I recently attended a talk given by an engineer from a top security product company and, while the talk was quite interesting, something that the engineer said has been bugging me a bit. He basically stated that, as a control, deploying a web application firewall was preferable to actually fixing vulnerable code. Web application firewalls (WAFs) are great in that they provide an additional layer of defense at the application layer. By filtering requests sent to applications, they are able to block certain types of malicious traffic such as cross-site scripting and SQL injection. WAFs rarely produce false positives, meaning that they won’t accidently block legitimate traffic. And WAFs can be tuned fairly precisely to particular applications. Additionally, WAFs can filter outbound traffic to act as a sort of data leak prevention solution. But is installing a WAF preferable to writing secure code? Or, put differently, is having a WAF in place reason enough to disregard secure coding standards and remediation processes? I don’t think so. WAFs, like other security controls, are imperfect and can be bypassed. They require tuning to work properly. They fall victim to the same issues that any other software does: poor design and poor implementation. While a WAF may catch the majority of injection attacks, for example, a skilled attacker can usually craft a request that can bypass application filters (particularly in the common situation that the WAF hasn’t been completely tuned for the application, which can be an extremely time-consuming activity). We have seen this occur quite often in our penetration tests; the WAF filters automated SQL injection attempts executed by our tools but fails to block manually crafted injections. I’m not saying that organizations shouldn’t deploy web application firewalls. However, rather than using a WAF in place of good application secure application development and testing practices, they should consider WAFs as an additional layer in their strategy of defense-in-depth and continue to address application security flaws with code changes and security validation testing. [post_title] => Thoughts on Web Application Firewalls [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => thoughts-on-web-application-firewalls [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:06:28 [post_modified_gmt] => 2021-04-13 00:06:28 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1189 [menu_order] => 787 [post_type] => post [post_mime_type] => [comment_count] => 1 [filter] => raw ) [4] => WP_Post Object ( [ID] => 1203 [post_author] => 16 [post_date] => 2012-06-22 07:00:26 [post_date_gmt] => 2012-06-22 07:00:26 [post_content] => It is becoming more common these days (though still not common enough) for organizations to have regular vulnerability scans conducted against Internet-facing, and sometimes internal, systems and devices. This is certainly a step in the right direction, as monthly scans against the network and service layer are an important control that can be used to detect missing patches or weak configurations, thereby prompting vulnerability remediation. Perhaps unsurprisingly, some application security vendors are applying this same principle to web application testing, insisting that scanning a single application numerous times throughout the year is the best way to ensure the security of the application and related components. Does this approach make sense? In a handful of cases, where ongoing development is taking place and the production version of the application codebase is updated on a frequent basis, it may make sense to scan the application prior to releasing changes (i.e. as part of a pre-deployment security check). Additionally, if an organization is constantly deploying simple websites, such as marketing “brochureware” sites, a simple scan for vulnerabilities may hit the sweet spot in the budget without negatively impacting the enterprise’s risk profile. However, in most cases, repeated scanning of complex applications is a waste of time and money that offers little value beyond identifying the more basic of application weaknesses. Large modern web applications are intricate pieces of software. Such applications are typically updated based on a defined release cycle rather than on a continual basis and, when they are updated, functionality changes can be substantial. Even in the cases where updates are relatively small, the impact of these changes to the application’s security posture can still be significant. Due to these facts, repeated scans for low-level vulnerabilities simply do not make sense. Rather, comprehensive testing to identify application-specific weaknesses, such as errors related to business logic, is necessary to truly protect against the real threats in the modern world. Your doctor might tell you to check your blood pressure every few weeks but he would never lead you to believe that doing so is a sufficient way to monitor your health. Rather, less frequent but still regular comprehensive checkups are recommended. So why would you trust an application security vendor that tells you that quantity can make up for a lack in quality? There may be a place in the world for these types of vendors but you shouldn’t be entrusting the security of your critical applications to mere testing for low-hanging fruit. A comprehensive approach that combines multiple automated tools with expert manual testing is the best way to ensure that your web applications are truly secure. [post_title] => Web Application Testing: What is the right amount? [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => web-application-testing-what-is-the-right-amount [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:06:28 [post_modified_gmt] => 2021-04-13 00:06:28 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1203 [menu_order] => 801 [post_type] => post [post_mime_type] => [comment_count] => 1 [filter] => raw ) [5] => WP_Post Object ( [ID] => 1206 [post_author] => 16 [post_date] => 2012-05-24 07:00:26 [post_date_gmt] => 2012-05-24 07:00:26 [post_content] => Earlier this month, at the Secure360 conference in St. Paul, Seth Peter (NetSPI’s CTO) and I gave a presentation on enterprise vulnerability management. This talk came out of a number of discussions about formal vulnerability management programs that we have had both internally at NetSPI and with outside individuals and organizations. While many companies have large and relatively mature security programs, it would not be an exaggeration to say that very few have formalized the process of actively managing the vulnerabilities in their environments. To accompany our presentation, I created a short white paper addressing the subject. In it, I briefly address the need for such a formal program, summarize a four phase approach, and offer some tips and suggestions on making vulnerability management work in your organization. When reading it, keep in mind that the approach that I outline is by no means the only way of successfully taking on the challenge of managing your security weaknesses. However, due to our unique vantage point as both technical testers and trusted program advisors for many organizations across various industries, we have been able to pull together an approach that incorporates the key elements that will allow this sort of program to be successful. Download Ryan's white paper: An Approach to Enterprise Vulnerability Management [post_title] => Enterprise Vulnerability Management [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => enterprise-vulnerability-management [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:06:04 [post_modified_gmt] => 2021-04-13 00:06:04 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1206 [menu_order] => 804 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [6] => WP_Post Object ( [ID] => 1213 [post_author] => 16 [post_date] => 2012-03-19 07:00:26 [post_date_gmt] => 2012-03-19 07:00:26 [post_content] => Several months ago, I attended an industry conference where there was much buzz about “The Cloud.” A couple of the talks purportedly addressed penetration testing in the Cloud and the difficulties that could be encountered in this unique environment; I attended enthusiastically, hoping to glean some insight that I could bring back to NetSPI and help to improve our pentesting services. As it turns out, I was sorely disappointed. In these talks, most time was spent noting that Cloud environments are shared and, in executing a pentest against such an environment, there was a substantially higher risk of impacting other (non-target) environments. For example, if testing a web application hosted by a software-as-a-service (SaaS) provider, one could run the risk of knocking over the application and/or the shared infrastructure and causing a denial of service condition for other customers of the provider in addition to the target application instance. This is certainly a fair concern but it is hardly a revelation. In fact, if your pentesting company doesn’t have a comprehensive risk management plan in place that aims to minimize this sort of event, I recommend looking elsewhere. Also, the speakers noted that getting permission from the Cloud provider to execute such a test can be extremely difficult. This is no doubt due to the previously mentioned risks, as well as the fact that service providers are typically rather hesitant to reveal their true security posture to their customers. (It should be noted that some Cloud providers, such as Amazon, have very reasonable policies on the use of security assessment tools and services.) In any case, what I really wanted to know was this: is there anything fundamentally different about testing against a Cloud-based environment as compared with testing against a more traditional environment? After much discussion with others in the industry, I have concluded that there really isn’t. Regardless of the scope of testing (e.g., application, system, network), the underlying technology is basically the same in either situation. In a Cloud environment, some of the components may be virtualized or shared but, from a security standpoint, the same controls still apply. A set of servers and networking devices virtualized and hosted in the Cloud can be tested in the same manner as a physical infrastructure. Sure, there may be a desire to also test the underlying virtualization technology but, with regard to the assets (e.g., databases, web servers, domain controllers), there is no difference. Testing the virtualization and infrastructure platforms (e.g., Amazon Web Services, vBlock, OpenStack) is also no different; these are simply servers, devices, and applications with network-facing services and interfaces. All of these systems and devices, whether virtual or not, require patching, strong configuration, and secure code. In the end, it seems that penetration testing against Cloud environments is not fundamentally different from testing more conventional environments. The same controls need to exist and these controls can be omitted or misapplied, thereby creating vulnerabilities. Without a doubt, there are additional components that may need to be considered and tested. Yet, at the end of the day, the same tried and true application, system, and network testing methodologies can be used to test in the Cloud. [post_title] => Pentesting the Cloud [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => pentesting-the-cloud [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:05:27 [post_modified_gmt] => 2021-04-13 00:05:27 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1213 [menu_order] => 811 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [7] => WP_Post Object ( [ID] => 1218 [post_author] => 16 [post_date] => 2012-02-07 07:00:26 [post_date_gmt] => 2012-02-07 07:00:26 [post_content] => In my experience, one of the security management processes that causes the most confusion among security stakeholders is the periodic risk assessment. Most major information security frameworks such as ISO/IEC 27002:2005, the PCI Data Security Standard, and HIPAA, include annual or periodic risk assessments and yet a surprising number of organizations struggle with putting together a risk assessment process. Fundamentally, the concept of a risk assessment is straightforward: identify the risks to your organization (within some defined scope) and determine how to treat those risks. The devil, of course, is in the details. There are a number of formal risk assessment methodologies that can be followed, such as NIST SP 800-30, OCTAVE, and the risk management framework defined in ISO/IEC 27005 and it makes sense for mature organizations to implement one of these methodologies. Additionally, risk assessments at larger companies will often feed into an Audit Plan. If you’re responsible for conducting a risk assessment for a smaller or less mature company, though, the thought of performing and documenting a risk assessment may leave you scratching your head. The first step in any risk assessment is to identify the scope of the assessment, be they departments, business process, systems and applications, or devices. For example, a risk assessment at a financial services company may focus on a particular business unit and the regulated data and systems used by that group. Next, the threats to these workflows, systems, or assets should be identified; threats can include both intentional and unintentional acts and may be electronic or physical. Hackers, power outages, and hurricanes are all possible threats to consider. In some cases, controls for addressing the vulnerabilities associated with these threats may already exist so they should be taken into account. Quantifying the impact to the organization should one of these threats be realized is the next step in the risk assessment process. In many cases, impact is measured in financial terms because dollars are pretty tangible to most people but financial impact is not always the only concern. Finally, this potential impact should be combined with the likelihood that such an event will occur in order to quantify the overall risk. Some organizations will be satisfied with quantifying risk as high, medium, or low, but a more granular approach can certainly be taken. When it comes to treating risks, the options are fairly well understood. An organization can apply appropriate controls to reduce the risk, avoid the risk by altering business processes or technology such that the risk no longer applies, share the risk with a third party through contracts (including insurance), or knowingly and objectively determine to accept the risk. At the conclusion of all of the risk assessment and treatment activities, some sort of documentation needs to be created. This doesn’t need to be a lengthy formal report but, whatever the form, it should summarize the scope of the assessment, the identified threats and risks, and the risk treatment decisions. Results from the Audit Plans can also assist in this documentation process. Most organizations already assess and treat risks operationally and wrapping a formal process around the analysis and decision-making involved should not be overwhelming. Of course, different organizations may need more rigor in their risk assessment process based on internal or external requirements and this is not meant to be a one-size-fits-all guide to risk assessment. Rather, the approach outlined above should provide some guidance, and hopefully inspire some confidence to security stakeholders who are just starting down the road of formal risk management. [post_title] => The Annual Struggle with Assessing Risk [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => the-annual-struggle-with-assessing-risk [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:06:15 [post_modified_gmt] => 2021-04-13 00:06:15 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1218 [menu_order] => 816 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [8] => WP_Post Object ( [ID] => 1225 [post_author] => 16 [post_date] => 2011-10-26 07:00:26 [post_date_gmt] => 2011-10-26 07:00:26 [post_content] => The Cloud is one of the "new big things" in IT and security and I hate it. To be clear, I don't actually hate the concept of The Cloud (I'll get to that in a minute) but, rather, I hate the term. According to Wikipedia, cloud computing is "the delivery of computing as a service rather than a product, whereby shared resources, software, and information are provided to computers and other devices as a utility (like the electricity grid) over a network (typically the Internet)." What this pretty much amounts to is outsourcing. There are a lot of reasons that people "move to The Cloud" and I'm not really going to dive into them all; suffice it to say that it comes down to cost and the efficiencies that Cloud providers are able to leverage typically allow them to operate at lower cost than most organizations would spend accomplishing the same task. Who doesn't like better efficiency and cost savings? But what is cloud computing really? Some people use the term to refer to infrastructure as a service (IaaS), or an environment that is sitting on someone else's servers; typically, the environment is virtualized and dynamically scalable (remember that whole efficiency / cost savings thing). A good example of an IaaS provider is Amazon Web Services. Software as a service (SaaS) is also a common and not particularly new concept that leverages the concept of The Cloud. There are literally thousands of SaaS providers but some of the better known ones are Salesforce.com and Google Apps. Platform as a Service (PaaS) is less well-known term but the concept is familiar: PaaS providers the building blocks for hosted custom applications. Often, PaaS and IaaS solutions are integrated. An example of a PaaS provider is Force.com. The Private Cloud is also generating some buzz with packages such as Vblock, and OpenStack; really, these are just virtualized infrastructures. I'm currently at the Hacker Halted 2011 conference in Miami (a fledgling but well-organized event) and one of the presentation tracks is dedicated to The Cloud. There have been some good presentations but both presenters and audience members have struggled a bit with defining what they mean by The Cloud. One presenter stated that "if virtualization is involved, it is usually considered to be a cloud." If we're already calling it virtualization, why do we also need to call it The Cloud? To be fair, The Cloud is an appropriate term in some ways because it represents the nebulous boundaries of modern IT environments. No longer is an organization's IT infrastructure bound by company-owned walls; it is an amalgamation of company and third party managed party services, networks, and applications. Even so, The Cloud is too much of a vague marketing term for my taste. Rather than lumping every Internet-based service together in a generic bucket, we should say what we really mean. Achieving good security and compliance is already difficult within traditional corporate environments. Let's at least all agree to speak the same language. [post_title] => Why I Hate The Cloud [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => why-i-hate-the-cloud [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:05:28 [post_modified_gmt] => 2021-04-13 00:05:28 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1225 [menu_order] => 824 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [9] => WP_Post Object ( [ID] => 1226 [post_author] => 16 [post_date] => 2011-10-12 07:00:25 [post_date_gmt] => 2011-10-12 07:00:25 [post_content] => Mobile computing technology is hardly a recent phenomenon but, with the influx of mobile devices such as smartphones and tablet computers into the workplace, the specter of malicious activity being initiated by or through these devices looms large. However, generally speaking, an information security toolkit that includes appropriate controls for addressing threats presented by corporate laptops should also be able to deal with company-owned smartphones. My recommendations for mitigating the risk of mobile devices in your environment include the following:- Establish a Strong Policy
- Educate Users
- Implement Local Access Controls
- Minimize the Mobile Footprint
- Restrict Connectivity
- Restrict Web Application Functionality
- Assess Mobile Applications
- Encrypt, Encrypt, Encrypt
- Enable Remote Wipe Functionality
- Implement a Mobile Device Management System
- Provide Support for Employee-Owned Devices
After a number of questions on the topic, I have decided to follow up on my earlier security metrics blog with a bit more information regarding metrics development. The diagram below outlines the metrics development process.

1. Identify Controls to Measure – This is pretty self-explanatory: which controls do you want to evaluate? In very mature security programs, metrics may be gathered on numerous controls across multiple control areas. However, if you’re just starting out, you likely would not realize significant value from such detailed metrics at this time and would benefit more from monitoring key indicators of security health such as security spending, vulnerability management status, and patch compliance. In general, controls to be evaluated should be mapped from external and internal requirements. In this fashion, the impact of controls on compliance can be determined once metrics become available. Conversely, metrics can be designed to measure controls that target key compliance requirements. For this blog, I will focus on metrics related to vulnerability management.
2. Identify Available Sources of Data – This step is established in order to identify all viable sources of data which may be presented singularly or combined with others to create more comprehensive security metrics. Sources of data for metrics will vary based on what sort of controls are being measured. However, it is important that data sources be reliable and objective. Some examples of metrics that can be gathered from a single source (in this case, a vulnerability management tool) are listed in the table below.
| Name | Type |
|---|---|
| Number of systems scanned within a time period | Effort |
| Number of new vulnerabilities discovered within a time period | Effort |
| Number of new vulnerabilities remediated within a time period | Result |
| Number of new systems discovered within a time period | Environment |
| List of current vulnerabilities w/ages (days) | Result |
| List of current exploitable vulnerabilities w/ages (days) | Result |
| Number of OS vulnerabilities | Environment |
| Number of third-party vulnerabilities | Environment |
| List of configured networks | Effort |
| Total number of systems discovered / configured | Effort |
3. Define Security Metrics – Decide which metrics accurately represent a measurement of controls implemented by your organization. Begin by developing low-level metrics and then combine to create high level-metrics that provide deeper insight.
a. Low-Level Metrics
Low-level metrics are measurements of aspects of information security within a single area.Each metric may not be sufficient in conveying a complete picture but may be used in context with different metric types.Each metric should attempt to adhere to the following criteria:
- Consistently measured
- Inexpensive to gather
- Expressed as a cardinal number or a percentage
- Expressed as a unit of measure
Low-level metrics should be identified to focus on key aspects of the information security program.The goal should be to identify as many measurements as possible without concern for how comprehensive each measurement may be.The following are examples of low-level metrics:
- Hosts not patched (Result)
- Hosts fully patched (Result)
- Number of patches applied (Effort)
- Unapplied patches (Environment)
- Time to apply critical patch (Result)
- Time to apply non-critical patch (Result)
- New patches available (Environment)
- Hours spent patching (Effort)
- Hosts scanned (Effort)
b. High-Level Metrics
High-level metrics should be comprised of multiple low-level metrics in order to provide a comprehensive measure of effectiveness.The following are examples of such metrics:
- Unapplied patch ratio
- Unapplied critical patch trend
- Unapplied non-critical patch trend
- Applied / new patch ratio
- Hosts patched / not patched ratio
4. Collect Baseline Metric Data – A timeframe should be established that is sufficient for creating an initial snapshot, as well as basic trending. It is important that you allow enough time to collect a good baseline sample, as data can easily be skewed as you’re working out little bugs in the collection process.
5. Review Effectiveness of Metrics – Review the baseline data collected and determine whether it is effective in representing the success factors of specific controls. If some metrics fall short of the overall goal, another iteration of the metric development process will be necessary.
6. Publish Security Metrics – Begin publishing security metrics in accordance with pre-defined criteria.
As noted above, well-designed metrics must be objective and be based upon reliable data. However, data sources are not always fully understood when selected and, as a result, metrics may end up being less effective than when they were initially designed.
After metrics have been implemented, a suitable timeframe for collecting baseline data should be permitted. Once this has been done, metrics should be reevaluated in order to determine whether or not they provide the requisite information.Some metrics may fall short in this regard; if this is the case, another iteration of the metric development process will be necessary. Ultimately, metrics are intended to provide insight into the performance of a security program and its controls. If the chosen metrics do not do this effectively, or answer the questions that your organization is asking, then the metrics must be redesigned prior to being published and used for the purposes of decision making.
[post_title] => Metrics: Your Security Yardstick - Part 2 - Defining Metrics [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => metrics-your-security-yardstick-part-2-defining-metrics [to_ping] => [pinged] => [post_modified] => 2021-04-13 00:06:09 [post_modified_gmt] => 2021-04-13 00:06:09 [post_content_filtered] => [post_parent] => 0 [guid] => https://netspiblogdev.wpengine.com/?p=1233 [menu_order] => 831 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [13] => WP_Post Object ( [ID] => 1234 [post_author] => 16 [post_date] => 2011-08-30 07:00:25 [post_date_gmt] => 2011-08-30 07:00:25 [post_content] => Mention metrics to most anyone in the information security industries and eyes will immediately glaze over. While there are a few adventurous souls out there, most security professionals balk at the prospect of trying to measure their security program. However, the ability to do just that is an essential part of a security program at any maturity level and a way to move your program forward. Metrics allow security stakeholders to answer important questions about the performance of the security program and, ultimately, make educated decisions regarding the program. Being able to communicate the effectiveness of your program to business leaders is an important part of a program's identity and maturity within an organization. Generally speaking, metrics can be categorized into three types based on what they signify:- Effort metrics measure the amount of effort expended on security. For example:
- training hours,
- time spent patching systems, and
- number of systems scanned for vulnerabilities
- Result metrics attempt to measure the results of security efforts. Examples of result metrics include:
- the number of days since the last data breach,
- the number of unpatched vulnerabilities, and
- the number of adverse audit or assessment findings.
- Environment metrics measure the environment in which security efforts take place. These metrics provide context for the other two metrics. For example:
- the number of known vulnerabilities
- the number of systems
Making its debut in 2018, the Ryuk ransomware strand has wreaked havoc on hundreds of businesses and is responsible for one-third of all ransomware attacks that took place in 2020. Now it is seemingly on a mission to infect healthcare organizations across the country, already having hit five major healthcare providers, disabling access to electronic health records (EHR), disrupting services, and putting sensitive patient data at risk.
The healthcare industry is surely bracing for what the U.S. Cybersecurity & Infrastructure Security Agency (CISA) is warning as, “an increased and imminent cybercrime threat to U.S. hospitals and healthcare providers.” What can organizations do to preemptively protect themselves? Our recommendation:
- Analyze what makes the healthcare industry a key target for ransomware,
- Educate yourself to better understand Ryuk and TrickBot, and
- Implement proactive cyber security strategies to thwart ransomware attacks and minimize damage from an incident (we’ll get into this more later in this post).
We’ve pulled together this Guide to Ryuk as a resource to help organizations prevent future ransomware attacks and ultimately mitigate its impact on our nation’s healthcare systems.
Why are Healthcare Providers a Target for Ransomware?
Healthcare is widely known as an industry that has historically struggled to find a balance between the continuation of critical services and cyber security. To put this into perspective, doctors and physicians can’t stop everything and risk losing a life if their technology locks them out due to forgetting a recently changed password. So, security, while critically important in a healthcare environment, is more complex due to its “always on” operational structure.
We’ve seen a definite uptick in attention paid to security at healthcare organizations, but there’s much work to be done. The task of securing a healthcare systems is extremely challenging given its scale and complexity, consisting of many different systems and, with the addition of network-enabled devices, it becomes difficult for administrators to grasp the value of security relative to its costs. In addition, third parties, such as medical device manufactures also play a role. Historically, devices in hospitals, clinics, and home-healthcare environments had no security controls, but there has been more of a focus on “security features” as connectivity (network, Bluetooth, etc.) has increased. Yet most healthcare networks are still rife with these sorts of devices that have minimal, if any, built-in security capabilities.
Healthcare is by no means the only target industry: any organization can fall victim to ransomware. Though, healthcare is a prime target for two reasons:
- It’s a gold mine for sensitive data, including social security numbers, payment information, birth certificates, addresses, and more. While monetizing such data may require additional effort on the part of cybercriminals, breaches of such data is a major HIPAA compliance violation that can result in heavy fines and could also potentially have a negative impact to patients if their data is leaked.
- The criticality of the business is as high-risk as it gets. In other words, hospitals cannot afford downtime. Add a public health pandemic to the mix and the criticality increases drastically.
This sense of urgency to get systems back up and running quickly is a central reason why Ryuk is targeting the industry now. Hospitals are more likely to pay a ransom due to the potential consequence downtime can have on the organization and its patients.
Ransomware, Ryuk, and TrickBot:
To understand Ryuk, it is important to first understand ransomware attacks at a fundamental level. Ransomware gains access to a system only after a trojan or ‘botnet’ finds a vulnerable target and gains access first. Trojans gain access often through phishing attempts (spam emails) with malicious links or attachments (the payload). If successful, the trojan installs malware onto the target’s network by sending a beacon signal to a command and control server controlled by the attacker, which then sends the ransomware package to the Trojan.
In Ryuk’s case, the trojan is TrickBot. In this case, a user clicks on a link or attachment in an email, which downloads the TrickBot Trojan to the user’s computer. TrickBot then sends a beacon signal to a command and control (C2) server the attacker controls, which then sends the Ryuk ransomware package to the victim’s computer.
Trojans can also gain access through other types of malware, unresolved vulnerabilities, and weak configuration, though, phishing is the most common attack vector. Further, TrickBot is a banking Trojan, so in addition to potentially locking up the network and holding it for ransom, it may also steal information before it installs the ransomware.
How does an organization know if they have fallen victim to ransomware, more specifically Ryuk? It will be obvious if Ryuk has successfully infiltrated a system. It will take over a desktop screen and a ransom note will appear with details on how to pay the ransom via bitcoin:
An early warning sign of a ransomware attack is that at the technical level, your detective controls, if effective, should alert to Indicators of Compromise (IoC). Within CISA’s alert, you can find TrickBot IoCs listed along with a table of Ryuk’s MITRE ATT&K techniques.
A threat to the increasing remote workforce: In order to move laterally throughout the network undetected, Ryuk relies heavily on native tools, such as Windows Remote Management and Remote Desktop Protocol (RDP). Read: COVID-19: Evaluating Security Implications of the Decisions Made to Enable a Remote Workforce
Implementing Proactive Cyber Security Strategies to Thwart Ransomware Attacks
We mentioned at the start of this post that one of the things organizations can do preemptively to protect themselves is to put in place proactive security strategies. While important, security awareness only goes so far, as humans continue to be the greatest cyber security vulnerability. Consider this: In past NetSPI engagements with employee phishing simulations, our click-rates, or fail-rates, were down to 8 percent. This is considered a success, but still leaves open opportunity for bad actors. It only takes one person to interact with a malicious attachment or link for a ransomware attack to be successful.
Therefore, we support defense-in-depth as the most comprehensive strategy to prevent or contain a malware outbreak. Here are four realistic defense-in-depth tactics to implement in the near- and long-term to prevent and mitigate ransomware threats, such as Ryuk:
- Revisit your disaster recovery and business continuity plan. Ensure you have routine and complete backups of all business-critical data at all times and that you have stand-by, or ‘hot,’ business-critical systems and applications (this is usually done via virtual computing). Perform table-top or live disaster recovery drills and validate that ransomware wouldn’t impact the integrity of backups.
- Separate critical data from desktops, avoid siloes: Ryuk, like many ransomware strands, attempts to delete backup files. Critical patient care data and systems should be on an entirely separate network from the desktop. This way, if ransomware targets the desktop network (the most likely scenario) it cannot spread to critical hospital systems. This is a long-term, and challenging, strategy, yet well worth the time and budgetary investment as the risk of critical data loss will always exist.
- Take inventory of the controls you have readily available – optimize endpoint controls: Assess your existing controls, notably email filtering and endpoint controls. Boost email filtering processes to ensure spam emails never make it to employee inboxes, mark incoming emails with a banner that notifies the user if the email comes from an external source, and give people the capability to easily report suspected emails. Endpoint controls are essential in identifying and preventing malware. Here are six recommendations for optimizing endpoint controls:
- Confirm Local Administrator accounts are strictly locked down and the passwords are complex. Ensure Domain Administrator and other privileged accounts are not used for routine work, but only for those tasks that require admin access.
- Enable endpoint detection and response (EDR) capabilities on all laptops and desktops.
- Ensure that every asset that can accommodate anti-malware has it installed, including servers.
- Apply all security patches for all software on all devices. Disable all RDP protocol access from the Internet to any perimeter or internal network asset (no exceptions).
- Test your detective controls, network, and workstations:
- Detective control testing with adversarial simulation: Engage in a purple team exercise to determine if your detective controls are working as designed. Are you able to detect and respond to malicious activity on your network?
- Host-based penetration testing: Audit the build of your workstations to validate that the user does have least privilege and can only perform business tasks that are appropriate for that individual’s position.
- Internal network penetration testing: Identify high impact vulnerabilities found in systems, web applications, Active Directory configurations, network protocol configurations, and password management policies. Internal network penetration tests also often include network segmentation testing to determine if the controls isolating your crown jewels are sufficient.
Finally, organizations that end up a victim to ransomware have three options to regain control of their systems and data.
- Best option: Put disaster recovery and business continuity plans in motion to restore systems. Also, perform an analysis to determine the successful attack vector and remediate associated vulnerabilities.
- Not advised: Pay the ransom. A quick way to get your systems back up and running, but not advised. There is no guarantee that your business will be unlocked (in fact, the offer may also be ransomware), so in effect you are funding adversarial activities and it’s likely they will target your organization again.
- Rare cases: Cracking the encryption key, while possible with immature ransomware groups, is often unlikely to be successful. Encryption keys have become more advanced and require valuable time to find a solution.
For those that have yet to experience a ransomware attack, we encourage you to use the recent Ryuk news as a jumping point to future-proof your security processes and prepare for the inevitability of a breach. And for those that have, now is the time to reevaluate your security protocols.
[post_title] => Healthcare’s Guide to Ryuk Ransomware: Advice for Prevention and Remediation [post_excerpt] => Making its debut in 2018, the Ryuk ransomware strand has wreaked havoc on hundreds of businesses and is responsible for one-third of all ransomware attacks that took place in 2020. [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => healthcares-guide-to-ryuk-ransomware-advice-for-prevention-and-remediation [to_ping] => [pinged] => [post_modified] => 2021-05-04 17:06:19 [post_modified_gmt] => 2021-05-04 17:06:19 [post_content_filtered] => [post_parent] => 0 [guid] => https://www.netspi.com/?p=20466 [menu_order] => 454 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [comment_count] => 0 [current_comment] => -1 [found_posts] => 23 [max_num_pages] => 0 [max_num_comment_pages] => 0 [is_single] => [is_preview] => [is_page] => [is_archive] => [is_date] => [is_year] => [is_month] => [is_day] => [is_time] => [is_author] => [is_category] => [is_tag] => [is_tax] => [is_search] => [is_feed] => [is_comment_feed] => [is_trackback] => [is_home] => 1 [is_privacy_policy] => [is_404] => [is_embed] => [is_paged] => [is_admin] => [is_attachment] => [is_singular] => [is_robots] => [is_favicon] => [is_posts_page] => [is_post_type_archive] => [query_vars_hash:WP_Query:private] => 8ae4b0e26fddae1f41316d7f9adc3754 [query_vars_changed:WP_Query:private] => [thumbnails_cached] => [allow_query_attachment_by_filename:protected] => [stopwords:WP_Query:private] => [compat_fields:WP_Query:private] => Array ( [0] => query_vars_hash [1] => query_vars_changed ) [compat_methods:WP_Query:private] => Array ( [0] => init_query_flags [1] => parse_tax_query ) )