Prioritizing the Remediation of Mitre ATT&CK Framework Gaps

As Adversarial Simulation continues to gain momentum, more companies are performing full evaluations of their technical detective control capabilities using tools like the Mitre ATT&CK Framework. While this is a great way for internal security teams to start developing a detective control baseline, even mature organizations find themselves with dozens of detective capability gaps to follow up on. So, the natural question we hear from clients is “What is the best way to prioritize and streamline our remediation efforts?”. In this blog I’ll provide a few tips based on my experiences.
Before I go down that road, I wanted to take a moment to touch on how I’m qualifying adversarial simulation in this context. Feel free to SKIP AHEAD to the actual tips.
Adversarial Simulation
To better answer the questions, “What are attackers doing?” and “What should we be looking for?”, internal security teams started to document what techniques were being used by malware, red teams, and penetration testers at each phase of the Cyber Kill Chain. This inventory of techniques could then be used to baseline detection capabilities. As time went on, projects like the Mitre ATT&CK Framework started to gain more favor with both the red and the blue teams.
Out of this shared adoption of an established and public framework, Adversarial Simulation began to grow in popularity. Similar to the term “red team”, “Adversarial Simulation” can mean different things to different people. In this context, I’m defining it as “Measuring the effectiveness of existing technical detective controls using a predefined collection of security unit tests”. The goal of this type of testing is to measure the company’s ability to identify known Tools Techniques and Procedures (TTPs) related to the behavior of attackers that have already obtained access to the environment in an effort to build/maintain a detective control baseline.
After conducting multiple Adversarial Simulation exercises with small, medium, and large organizations, one thing became very apparent. If your company hasn’t performed adversarial simulation testing before, then you’re likely to have a quite a few gaps at each phase of the cyber kill chain. At first this can seem overwhelming, but it is something that you can triage, prioritize, and manage.
The rest of this blog covers some triage options for those companies going through that now.
Using MITRE ATT&CK as a Measuring Stick
The MITRE ATT&CK framework defines categories and techniques that focus on post-exploitation behavior. Since the goal is to detect that type of behavior it offers a nice starting point.
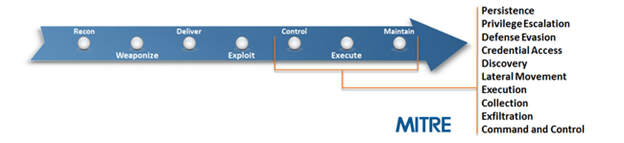
Source: https://attack.mitre.org/
While this is a good place to start measuring your detective and preventative controls, it’s just a starting point. ATT&CK doesn’t cover a lot of technologies commonly found in enterprise environments, and not all the techniques covered will be applicable to your environment.
Many of the internal security teams we work with have started adopting the ATT&CK framework to some degree. The most common process we see them using has been outlined below:
- Start with the entire framework
- Remove techniques that are not applicable to your environment
- Add techniques that are specific to technologies in your environment
- Add techniques that are not covered, but are well known
- Work through one category at a time
- Test one technique at a time
- Assess the SOC team’s ability to detect the technique
- Identify artifacts, identify data sources used for TTP discovery, and create SIEM rules
- Document technique coverage
- Rinse, lather, and repeat.
While there are some commercial products and services available to support this process we have also seen some great open source projects. The Threat Hunter Playbook created by Roberto Rodriguez is at the top of my recommended reading list. It includes lots of useful tools to help internal teams get rolling. You can find it on github: https://github.com/Cyb3rWard0g/ThreatHunter-Playbook
When we work with clients, we typically measure the applicable techniques in all phases to provide insight into their ability to detect them within each of the post-exploitation attack phases defined in the ATT&CK framework. However, sometimes that can be information overload so starting with a few key categories of techniques can be a nice way to kick things off. Clients usually prefer to prioritize around execution, defense evasion, and exfiltration, because they essentially represent the beginning and end of a basic attack workflow. Also, when evaluating exfiltration techniques, you implicitly cover some the more common controls channels.
Below is a sample of the summary data that can shake loose when looking at the whole picture.

At first glance this can seem alarming, but the sky is not falling. Keep in mind that the technologies and processes to identify the TTPs for post exploitation are still trying to catch up to attackers. The first step to getting better is being honest about what you can and can’t do. That way you’ll have the information you need to create a prioritized roadmap that can give you more coverage in a shorter period of time for less money (hopefully).
Remediation Prioritization Tips
The goal of these tips is to reduce the time/dollar investment required to improve the effectiveness of the current controls and your overall ability to detect known and potential TTPs. To start us off I wanted to note that you can’t alert on the information you don’t have. As a result, missing data sources often map directly to missing alerts in specific categories.
Prioritizing Data Sources
As I mentioned before, data sources are what fuel your detective capabilities. When choosing to build out a new data source or detective capability, consider prioritizing around those that have the potential to cover the highest number of techniques across all ATT&CK framework categories.
For example, netflow data can be used identify:
- Generic scanning activity
- Authenticated scanning
- ICMP and DNS tunnels
- Large file downloads and uploads
- Long login sessions
- Reverse shell patterns
- Failed egress attempts
I’m sure there are more use cases, but you get the idea. Naturally, you should inventory and track your known data sources and be conscious of what your data source gaps are. One way to help make sure that gap list is fleshed out is to identify potential data sources based on what techniques don’t generate any alerts.
Below is a basic pie chart showing how that type of data can be represented. It summarizes the level of visibility for techniques that did not generate a security alert. The identified detection gaps fall into 1 of 5 detection levels. Unknown, Undetected, Partially Logged, Logged, and Partially Detected.
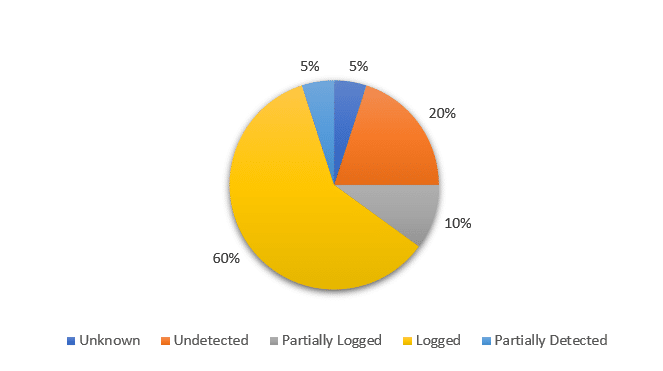
Existing Data Sources
From this we can see that 60% of the techniques that didn’t generate an alert still left traces in logs. By pulling in that log data we can almost immediately start working on correlations and alerts for many of the associated attack techniques. That by itself should have some influence on what you start with when building out new detections.
Missing Data Sources
The other 40% represent missing or misconfigured data sources. Using the list of associated techniques and information from Mitre we can determine potential data sources, and which ones would provide coverage for the largest number of techniques. If you’re not sure what data sources are associated with which techniques, you can find it on Mitre website. Below is an example that illustrates some of the information available for the Accessibility Features in Windows.

Source: https://attack.mitre.org/wiki/Technique/T1015
To streamline your lookups, consider using invoke-ATTACKAPI, by Roberto Rodriguez. It can be downloaded from https://github.com/Cyb3rWard0g/Invoke-ATTACKAPI.
Below is a sample PowerShell script the uses Invoke-ATTACKAPI to get a list of the data sources that can be used to identify multiple attack techniques. To increase its usefulness, you could easily modify it to only include the attack techniques that you know your blind to. Note: All of your data sources may not be covered by the framework, or they may use different language to describe them.
# Load script from github and sync
iex(New-Object net.webclient).DownloadString("https://raw.githubusercontent.com/Cyb3rWard0g/Invoke-ATTACKAPI/master/Invoke-ATTACKAPI.ps1")
# Group data sources
$AllTechniques = Invoke-ATTACKAPI -All
$AllTechniques | Where-Object platform -like "Windows" | Select "Data Source",TechniqueName -Unique |
ForEach-Object {
$TechniqueName = $_.TechniqueName
$_."Data Source" | ForEach-Object {
$Object = New-Object PSObject
$Object | add-member Noteproperty TechniqueName $Technique
$Object | add-member Noteproperty DataSource $_
$Object
}
} | Select TechniqueName,DataSource | Group-Object DataSource | Sort-Object count -Descending
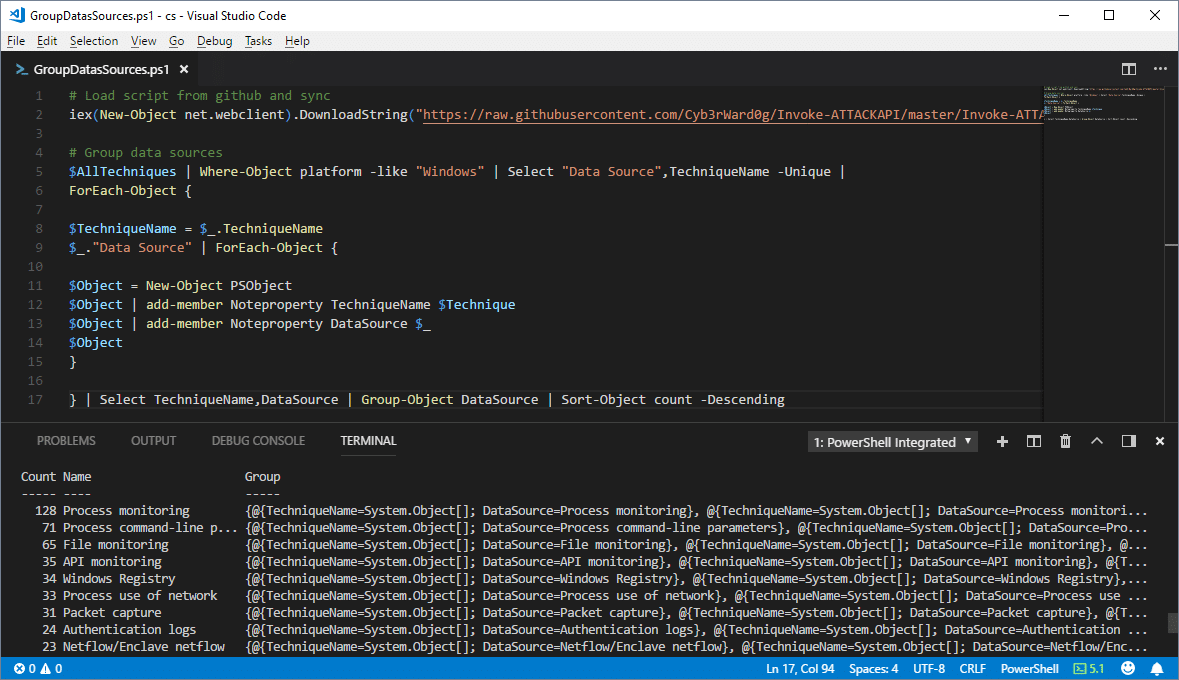
From the command results, you can quickly see that “Process Monitoring” and a few others can be incredibility powerful data sources for detecting the techniques in the Mitre ATT&CK Framework.
Prioritizing Techniques by Tactic
Command execution and defense evasion techniques occur at the beginning, and throughout the kill chain. As such, having deeper visibility into these techniques can help mitigate risk associated with some of the visibility gaps in later attack phases; such as persistence, lateral movement, and credentials gathering by detecting potentially malicious behavior sooner.
Below I reorganized the ATT&CK categories from our previous example test results to illustrate the point.
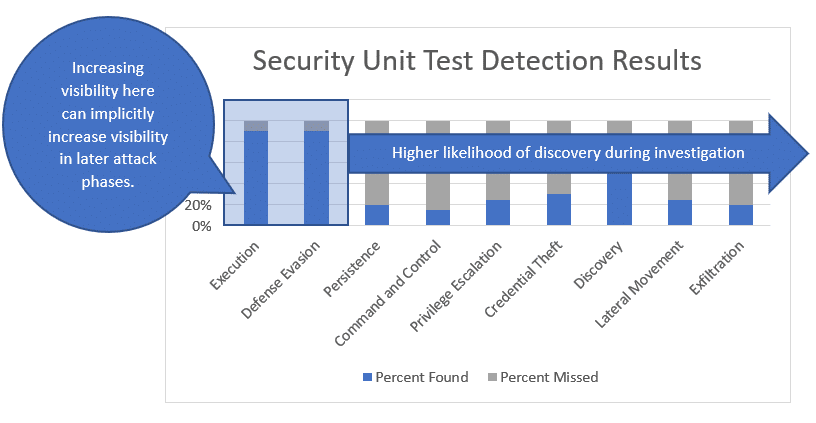
Command Execution
Attackers often employ non-standard command execution techniques that leverage native applications to avoid application white list controls. Many of those techniques are not commonly used by legitimate users, so the commands themselves can be used as reliable indicators of malicious behavior.
For example, most users don’t use regsvr32.exe, regsvcs.exe, or msbuild.exe at all. When they are used legitimately, it’s rare that they use the same command options as attackers. For some practical examples check out the atomic-red-team repo on github: https://github.com/redcanaryco/atomic-red-team/blob/master/atomics/windows-index.md
Defense Evasion
Similar to command execution, attackers often employ defense evasion techniques that do not represent common user behavior. As a result, they can be used as reliable indicators of malicious behavior.
Lateral Movement
Not every attacker performs scanning, but a lot of them do. If you can accurately identify generic scanning and authenticated scanning behavior through netflow data and Windows authentication logs you have a pretty good chance of detecting them. If you have the data sources, but alerts aren’t configured, it’s worth the effort to close the gap. Sean Metcalf shared a presentation that covers some information on the topic (among other things) that can be found here.
Ideally it will help you identify potentially malicious movement before the attackers reach their target and start exfiltration.
Exfiltration
If you missed the attacker executing commands on the endpoints, looking for common malicious behaviors and anomalies in outbound traffic and internet facing systems can yield some valuable results (assuming you have the right data sources). Most people are familiar with the common controls channels, but for those who are not, below is a short list:
- ICMP, SMTP, SSH, and DNS tunnels
- TCP/UDP reverse shells (over various ports/protocols)
- TCP/UDP beacons (over various ports/protocols)
- Web shells
Prioritizing Techniques by Utility
Developing detections for techniques that are used in multiple attack phases can give you a better return on your time/dollar investments. For example, scheduled tasks can be used for execution, persistence, privilege escalation, and lateral movement. So, when you have the ability to identify high risk tasks that are being created, you can kill three birds with one stone. (Note: No birds were actually killed in the making of this blog.)
Below is a sample PowerShell script the uses Invoke-ATTACKAPI to get a list of the techniques used in multiple attack categories. To increase its usefulness, you could easily modify it to only include the attack techniques that your blind to.
# Load script from github and sync
iex(New-Object net.webclient).DownloadString("https://raw.githubusercontent.com/Cyb3rWard0g/Invoke-ATTACKAPI/master/Invoke-ATTACKAPI.ps1")
# Grab and group the techniques
$AllTechniques = Invoke-ATTACKAPI -All
$AllTechniques | Where-Object platform -like "Windows" | Select Tactic,TechniqueName -Unique |
ForEach-Object {
$Technique = $_.TechniqueName
$_.tactic | ForEach-Object {
$Object = New-Object PSObject
$Object | add-member Noteproperty TechniqueName $Technique
$Object | add-member Noteproperty Tactic $_
$Object
}
} | Select TechniqueName,Tactic | Group-Object TechniqueName | Sort-Object count -Descending | select Count, Name -Skip 1
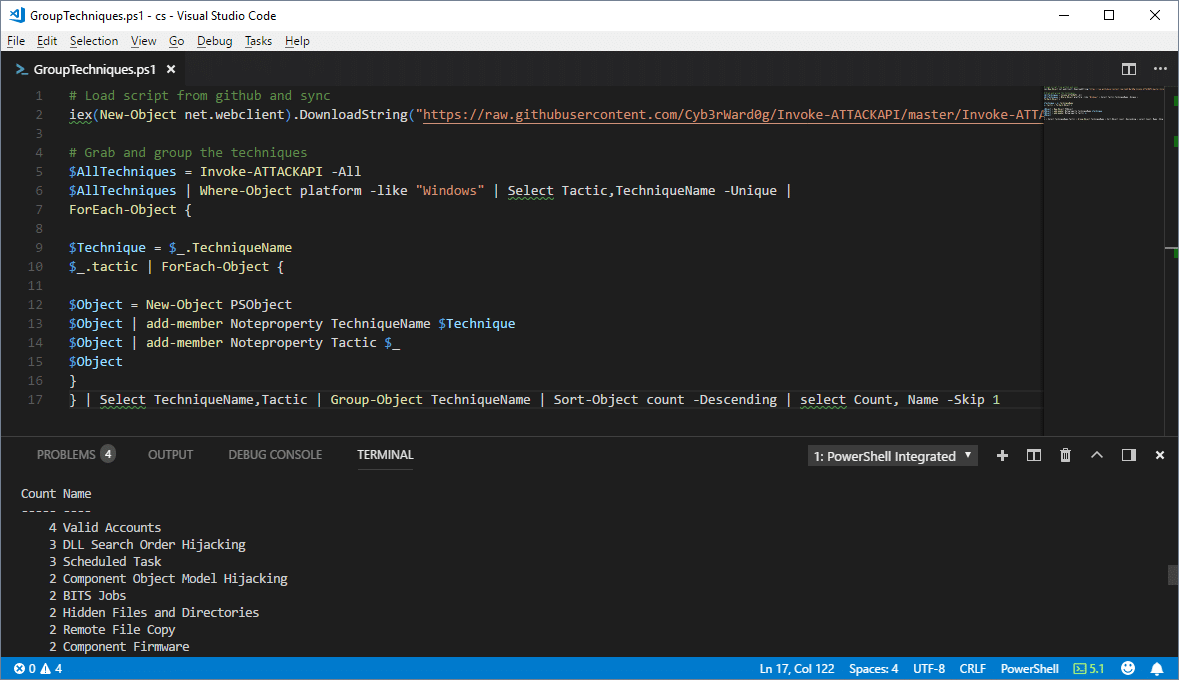
Once again you can see that some of the techniques can be used in more phases than others.
Prioritizing Techniques by (APT) Group
The ATT&CK framework also includes information related to well-known APT groups and campaigns at https://attack.mitre.org/wiki/Groups. The groups are linked to techniques that were used during campaigns. As a result, we can see what techniques are used by the largest number of (APT) groups using the Invoke-ATTACKAPI Powershell script below.
#Load script from github and sync
iex(New-Object net.webclient).DownloadString("https://raw.githubusercontent.com/Cyb3rWard0g/Invoke-ATTACKAPI/master/Invoke-ATTACKAPI.ps1
#Techniques used by largest number of APT groups
$AllTechniques = Invoke-ATTACKAPI -All
$AllTechniques | Where-Object platform -like "Windows" | Select Group,TechniqueName -Unique |
Where group -notlike "" | Group-Object TechniqueName | Sort-Object count -Descending
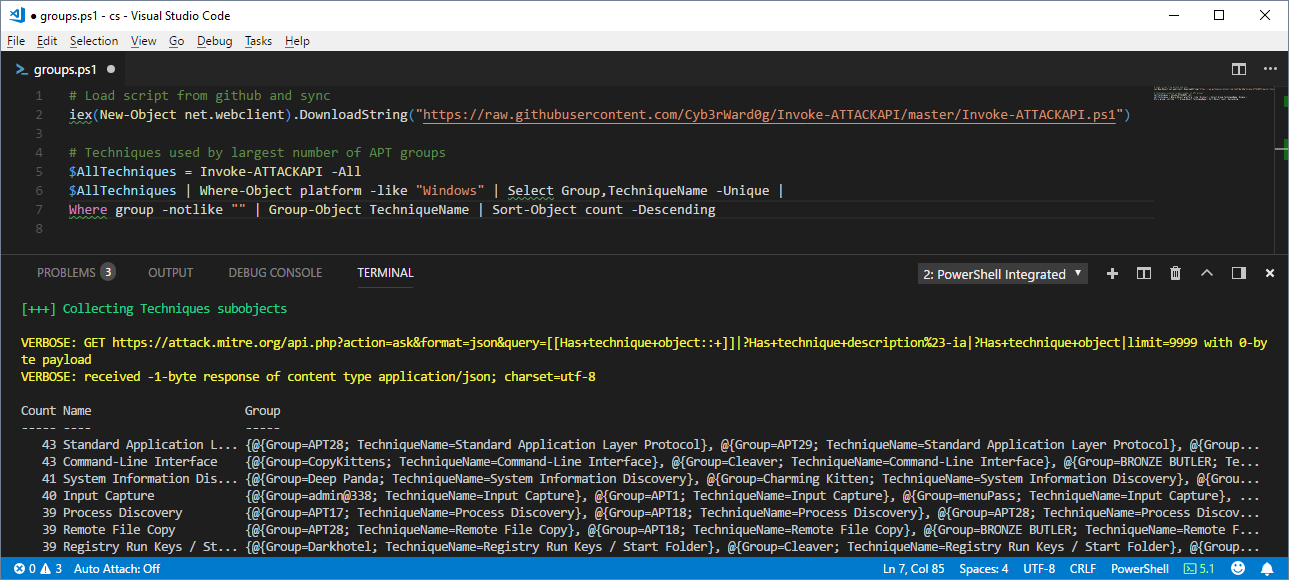
To make it more useful, filter for group names that are more relevant to your industry. At the moment I don’t think the industries or countries targeted by the groups are available as meta data in the ATT&CK framework. So for now that part may be a manual process. Either way, big thanks to Jimi for the tip!
Prioritizing Based on Internal Policies and Requirements
Understanding your company’s priorities and policies should always influence your choices. However, if you are going to follow those policies, make sure that the language is well defined and understood. For example, if you have an internal policy that states you must be able to detect all known threats, then “known threats” needs to be defined and expectations should be set as to how the list of known threats will be maintained.
Like vulnerability severity ranking, you should also create a system for ranking detective control gaps. That system should also define how quickly the company will be required to develop a detective capability either through existing controls, new controls, or process improvements.
Bridging the Gap with Regular Hunting Exercises
Regardless of how you prioritize the development of your detective capabilities, things take time. Collecting new data sources, improving logging, improving SIEM data ingestion/rules for all of your gaps is rarely a quick process. While you’re building out that automation consider keeping an eye on known gaps via regular hunting exercises. We’ve seen a number of clients leverage well defined hunts to yield pretty solid results. There was a nice presentation by Jared Atkinson and a recent paper by Paul Ewing/Devon Kerr from Endgame that are worth checking out if you need a jump start.
Wrap Up
Just like preventative controls, there is no such thing as 100% threat detection. Tools, techniques, and procedures are constantly changing and evolving. Do the best you can with what you have. You’ll have to make choices based on perceived risks and the ROI of your security control investments in the context of your company, but hopefully this blog with help make some of the choices easier. At the end of the day, all of my recommendations and observations are limited to my experiences and the companies I’ve worked with in the past. So please understand that while I’ve worked with quite a few security teams, I still suffer from biases like everyone else. If you have other thoughts or recommendations, I would love to hear them. Feel free to reach out in the comments. Thanks and good luck!
References
Explore More Blog Posts

Phishing with Misfortune Cookies
Phishing is about creativity. The less likely your target is to think about a link being potentially malicious, the more likely you are to have success. Read how our creative Social Engineering experts ruined free cookies in the break room.

CVE-2026-9082 Drupal Core PostgreSQL SQL Injection Overview and Takeaways
A critical vulnerability in Drupal Core, tracked as CVE-2026-9082, affects Drupal deployments using a PostgreSQL database. The issue allows unauthenticated attackers to perform arbitrary SQL queries via crafted JSON:API or search queries. Successful exploitation may result in full database compromise or remote code execution.

Emulating & Exploiting UEFI: Unveiling Vulnerabilities in Firmware Security
Explore the intricacies of UEFI security with exploration into emulation, dynamic analysis, and the LogoFail vulnerability. Learn how subtle input manipulations can expose critical firmware weaknesses.