
Painting a Threat Detection Landscape
The MITRE ATT&CK Evaluations is a small-scale demonstration that shows how a tool or (Endpoint Detection and Response) EDR product would detect and prevent adversary behavior. On their own, the evaluations paint an intriguing picture, but they have some issues and require a security program that understands itself to fully benefit from the findings. We can expand this output to answer a set of questions that have been asked of (security operations center) SOCs for years.
- How do you measure the threat detection efficacy and overall coverage of a SOC or Incident Responder (IR) program?
- How can we tell when coverage of a technique is sufficient?
- Are there security products that are not pulling their weight?
- How can we best prioritize our security dollars and man-hours?
- How do you determine a meaningful operational direction that avoids the Sisyphean task of chasing the malware of the week?
- How do I conceptualize the engagement area that a SOC is meant to operate in i.e., how do I paint a reliable picture of my threat detection landscape?
From here, we will cover the promise of the MITRE ATT&CK methodology and its shortcomings. We will also discuss the philosophy of threat detection and identify gaps within the MITRE ATT&CK Framework to help answer these questions in a data-driven manner.
MITRE ATT&CK Evaluations: A Model to Start With
This year is the fourth time MITRE has run the evaluations. In a nutshell, the evaluations are a combination of a purple team exercise and a science experiment. They place many security products in identical environments and then execute the same procedures against all of them.
The goal of the MITRE ATT&CK Evaluations is to determine if the activity from the procedure was observed or detected. From those data points, MITRE assembles a list of visible tactics and techniques.
Unfortunately, the output of this test paints a low-resolution picture that is easy to manipulate and misinterpret. For example, look at how vendors interpret the results from the evaluations: many declaring victory, 100% coverage, 100% prevention, top tier finish, etc.
When you investigate the data, it is obvious that some of this pomp resulted from the limited number of techniques chosen for the MITRE ATT&CK Evaluations. Despite this, the fact that some vendors got 100% coverage of the chosen techniques is still impressive, right? Doesn’t that imply that a consumer would not have to worry about those techniques?
Couldn’t one just find another vendor that covers the other techniques and brick-by-brick assembles 100% MITRE ATT&CK coverage? GG everyone, security is solved. Everyone go home.
So, what’s the problem? The picture painted by the evaluations is not completely accurate because they are extrapolating coverage of a single procedure to mean complete coverage of an entire tactic or technique. Just as there are often many techniques to a tactic, there are also often many procedures to a technique.
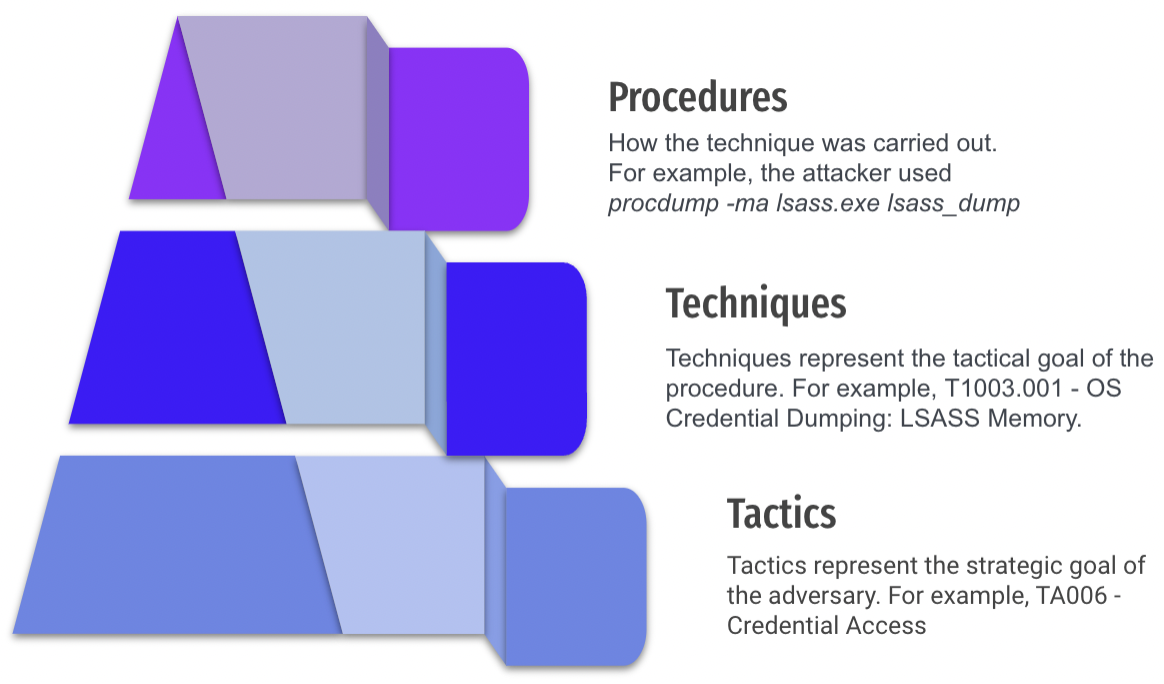
If we look at the MITRE ATT&CK Framework and the methodology of the evaluations, we can understand this result. The evaluations first create an adversary emulation plan and the chosen procedures against a security product and then records what was observed using the objects of the MITRE ATT&CK Framework. It is a small-scale snapshot of what is possible, not an overall evaluation of product effectiveness. Additionally, the results are limited by the MITRE ATT&CK Framework’s structure, which MITRE has recently taken steps to fix by adding detection objects.
The MITRE ATT&CK Framework has been revolutionary for cybersecurity, as it gives defenders a common lexicon and acts as a knowledge base of Tactics, Techniques, and Procedures (TTP) used by threat actors. The MITRE ATT&CK Model shows how the different objects in the ATT&CK Framework relate to each other. However, the reader will notice that within the model there is no object for procedures.
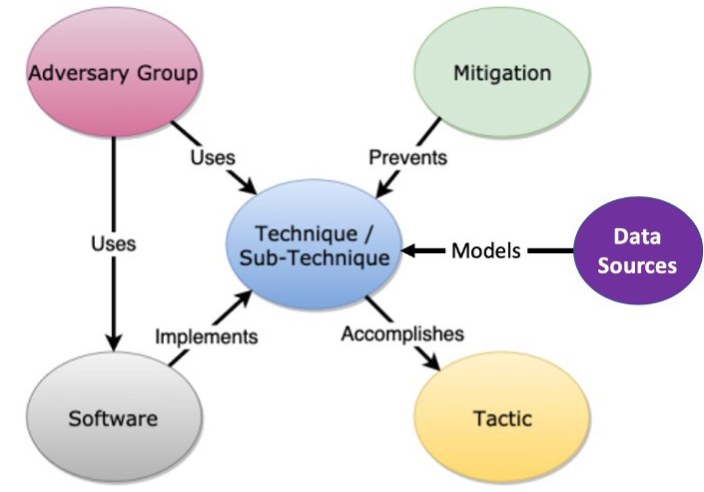
The Complex Role of Procedures in the MITRE ATT&CK Framework
Logically, procedures can be seen as a component piece of technique/sub-technique and, as we will see, they are crucial for helping us to measure and understand threat detection. While tactics and techniques are important, they should not be the individual strokes of our painting. Coverage of a single procedure is usually not analogous to complete coverage of a technique. Making this assumption will lead us to paint a low-resolution landscape.
Procedures from the perspective of the MITRE ATT&CK Framework are double-edged. While they are the raw methods used to implement the techniques, they also frequently change and are manifold. The MITRE ATT&CK Framework currently consists of 188 techniques and 379 sub-techniques. Within a majority of those techniques and sub-techniques exist multiple procedures.
To complicate things, those procedures themselves may exist in a many-to-many relationship to the techniques. Comprehensive tracking of procedures would be a herculean effort, especially without a solid argument as to why they should be tracked or how they are individually relevant.

Using an example from MITRE’s Cyber Analytic Repository, we can see how a single procedure, the registry addition below, exists in two techniques and three tactics:
reg add “HKEY_LOCAL_MACHINESystemCurrentControlSetControl Session Manager” /v SafeDllSearchMode /d 0
| Technique | Subtechnique(s) | Tactic(s) |
| Hijack Execution Flow | DLL Search Order Hijacking | Persistence, Privilege Escalation, Defense Evasion |
| Modify Registry | N/A | Defense Evasion |
Without considering the importance of procedures, general misunderstandings about visibility and detection coverage occur. This directly affects the decisions made at the different layers of a security organization. We begin to recognize this problem at the tactical level and can see how the misunderstanding propagates through the other levels and affect decisions.

Risk at the Three Levels of Threat Intelligence
At a tactical level, a detection engineer may realize that for a specific technique identified by the MITRE ATT&CK Framework, coverage is inconsistent, or that complete coverage is impossible within an environment.
Due to visibility, techniques may be complicated to cover or may need multiple detections to cover completely. Scale this problem by 188 techniques and 379 sub-techniques and it becomes obvious that a landscape assembled by one procedure per technique is at best incomplete. Moreover, it becomes difficult to trust that vendors completely cover the techniques they claim to cover.
Consider that many of these techniques require specialized knowledge to understand all possible procedures. You need to do further research to orchestrate detections in a way that offers comprehensive coverage.
Given these complications and the scope of the problem, we can extrapolate how the different layers of a security organization may use a threat detection landscape and see how one based solely on tactics and techniques may lead to less favorable outcomes.
| Strategic Level | A Chief Information Security Officer (CISO) may ask for a coverage map overlaid against the MITRE ATT&CK Framework. This might be used in an attempt to plan product changes and acquisitions or add additional headcount to various operations groups. RISKS: The CISO may end up purchasing products that do not increase detection coverage or, conversely, provide duplicate coverage. They may end up asking for initiatives that are unlikely to pan out or assign staff to less effective groups. |
| Operational Level | A Security Operations Center (SOC) Manager may try to use MITRE ATT&CK Framework coverage to plan red/purple/hunt operations or help direct the focus of their detection engineering or triage teams. RISKS: An incomplete picture at this level causes ineffective and inefficient operations and research. At this level, it can cause leaders to drive their analysts and engineers to focus on low-return operations or ignore areas with gaps. |
| Tactical Level | Analysts and engineers may try to use the MITRE ATT&CK Framework to look for other sources of rule logic or coverage and relevant and unknown procedures from the internet. RISKS: A low-resolution understanding or policy of procedure coverage equating technique coverage may cause an analyst to be blind to gaps or overestimate coverage. The assumptions may also cause them to ignore areas that could be improved or otherwise have misplaced faith in their systems. This can also occur during investigation or triage leading to false negatives during response. |
Tests like the MITRE ATT&CK Evaluations exacerbate this problem if marketing is allowed to drive the conversation. Security vendors are required to focus on high-fidelity alerting. If they implement default rules that are not high fidelity, they run into issues with preventing the legitimate business activity of their clients.
I have heard many anecdotes that follow this pattern: a researcher is attempting to do something that is blocked by a well-known security control only to attempt the same activity a week later and the activity is not blocked.
This is not to say that the MITRE ATT&CK Evaluations do not hold promises. The evaluations are enticing and the scientific method they follow is sound. The larger promise behind the evaluations is the ability to accurately measure coverage and paint a full threat detection landscape. Like any painting, it is a composition of individual strokes on a canvas, and the quality of the painting depends on each stroke.
Enhancing the Model
Enter the idea of capability abstraction. Jared Atkinson, a researcher who is consistently advancing the philosophy of detection engineering, wrote a fantastic blog on this. In short, we need to identify the root artifacts that are generated when a technique is executed, ideally via any procedure. The artifacts identified here can be considered a “base condition” for detection. If we then focus our detections around that identified “base condition”, we will create efficient detections that have maximum visibility on the target behavior.
Unfortunately, this is not possible in all cases and is even less possible in a real environment where visibility is limited. To help visualize and work around this problem, Jared has expanded the idea to trace all possible execution paths and artifacts for a single technique.
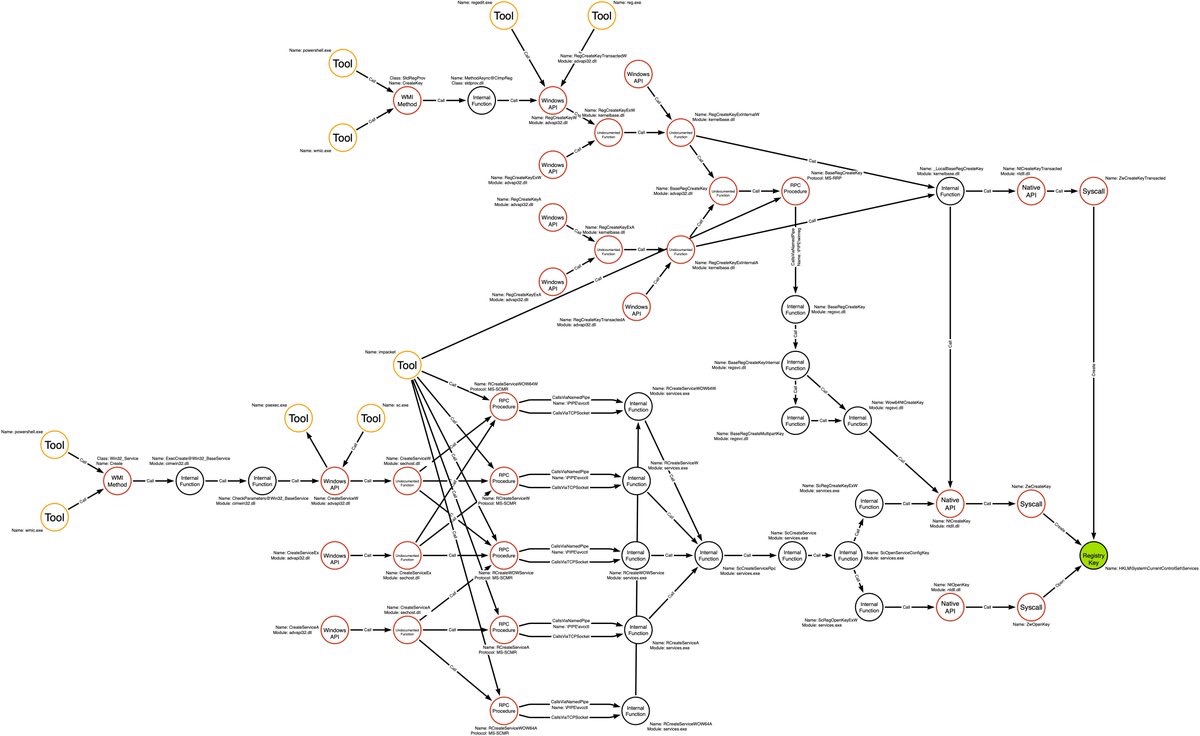
This could be used on a technique-by-technique basis to identify a set of visible base conditions that provide complete coverage. While comprehensive, this may not be entirely practical or sustainable on a large scale. So how else are we to measure our coverage?
In detection engineering, a goal is to identify an abnormality generated by attacker activity in your environment. Being able to programmatically identify this typically leads to high-fidelity detection. If we take this goal and focus on a base condition, we can begin to create comprehensive, durable detections that will be nigh impossible for an attacker to evade, much less know about in advance.
Unfortunately, without the knowledge of a graph similar to the one above and logging of a perfect base condition, how do we achieve maximal coverage? The answer to this uncertainty is that we must test many procedures and paint the picture through their aggregation. Jared compares this to the limit of a function, which I think is apt.
This method only touches on how to identify and classify one technique. With 188 techniques and 379 sub-techniques, this activity must scale for us to paint our entire threat detection landscape.
In practice, detection is not a binary, detection is a process. An organization’s coverage depends on where they are in within that process, therefore we need to measure that process to paint our detection landscape.
Measuring the Model
Detection is generally carried out in the following consecutive steps:
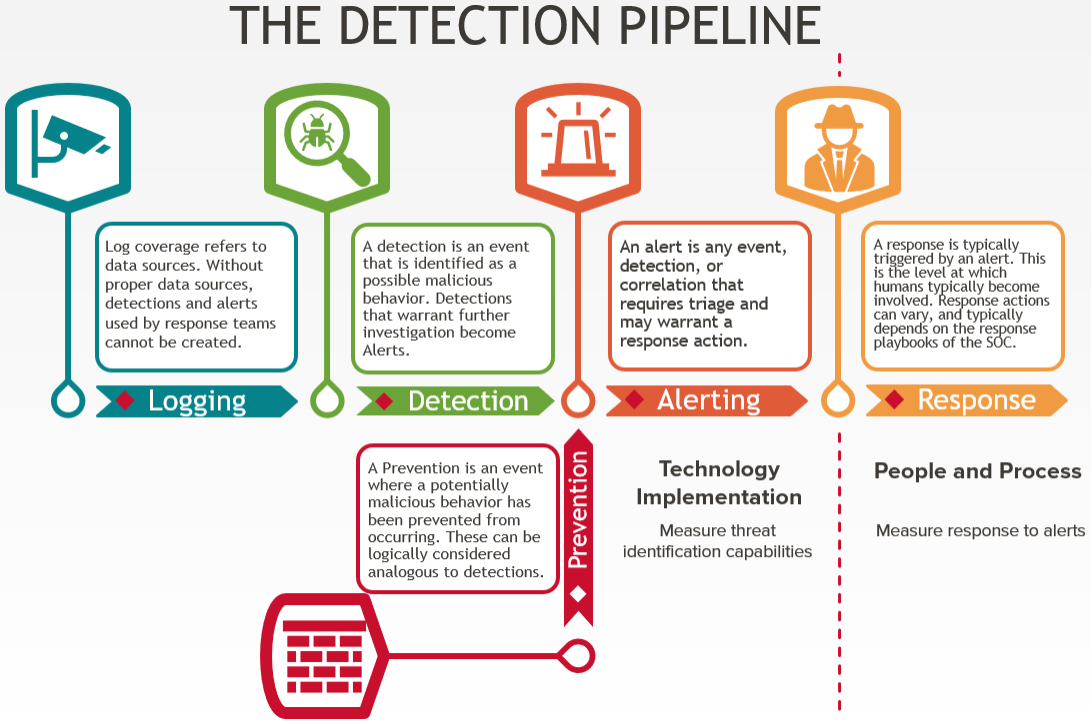
Each step in the pipeline is a piece of metadata that should be tracked alongside procedures to paint our landscape. These pieces of data tell us where we do or do not have visibility and where our technology, people, and processes (TPPs) fail or are incomplete.
| Logging | Generally, logs must be collected and aggregated to identify malicious activity. This is not only important from a forensic perspective, but also for creating, validating, and updating baselines. |
| Detection | Detection can then be derived from the log aggregations. Detections are typically separated by fidelity levels, which then feed alerts. |
| Alerting | Alerts are any event, detection, or correlation that requires triage and may warrant a more in-depth response action. Events at this level can still be somewhat voluminous but are typically deemed impactful enough to require some human triage and response. |
| Response | Response is where technology is handed off to people and processes. Triage, investigation, escalation, and eviction of the adversary occur within a response. Response is usually executed by a security operations or incident response team. The response actions vary depending on the internal playbooks of the company. |
| Prevention | This sits somewhat outside the threat detection pipeline. Activities can, and often are, prevented without further alerting or response. Prevention may occur without events being logged. Ideally, preventions should be logged to feed into the detection and alert steps of the pipeline. |
Paint the Rest of the Landscape
By assembling these individual data points for several procedures, we can confidently approximate a coverage level for an individual technique. We can also identify commonalities and create categories of detection to cover as much or as many of the base conditions as our visibility allows. Once many techniques are aggregated in this way, we can begin to confidently paint our threat detection landscape with all the nuance observed at the tactical level. A great man once said “We derive much value by putting data into buckets,” (Robert M. Lee) and it is no different here.
By looking at what data sources provide logging, detection, and prevention we can get a true sense of product efficacy. By looking at coverage over the different phases of the kill chain, we can start to prioritize choke points, detective efforts, emulation, deception, and research. By cataloging areas where prevention or detection are not carried forward to the alerting or response phases, we can better evaluate gaps, more accurately evaluate security products, and more efficiently spend budget or hours fixing those gaps with breach and attack simulation or similar tests.
The different levels (strategic, operational, tactical) drive each other. Apart from auditing, this feedback is the primary benefit of metrics, which can be problematic if the correct ones aren’t chosen. This collection bias is a vicious cycle especially if based on a low-resolution understanding of the threat detection landscape.
As teams get larger and the set of operations a security team performs gets more diverse, leadership becomes more difficult; feedback is essential to providing a unified direction and set of directives that enable a set of disparate teams to work together effectively.
The data derived here is also useful in many other ways:
- Red teams and purple teams
- Able to plan more effective tests
- Focus on known or suspected gaps
- Generate telemetry in known problem areas for hunting and detection engineering
- Threat Intelligence teams
- Able to focus collection efforts on problematic TTPs
- Easily evaluate the actionability of their intelligence
- Threat Hunting teams
- Able to focus on hunting more effectively
- Easily find coverage gaps
- Detection Engineering teams
- Able to identify low-hanging fruit
- Choke point kill chain tactics
- Work more effectively in a decentralized manner
- SOC analysts
- Will have better situational awareness
- Documentation to validate assumptions against
- New personnel to the environment
- Resource for immediate orientation
- Resource for a broad understanding of this area of operations
- SOC Managers
- Effectively direct and engage these subordinate teams
- Communicate on a shared picture
- CISOs
- Have confidence in their detection coverage
- Understand the effect of and plan for product/resource changes more effectively
- Orchestrate cross-team efforts more effectively
The pipeline that turns an activity on a system into an event that is responded to by the security team can be long and complicated.
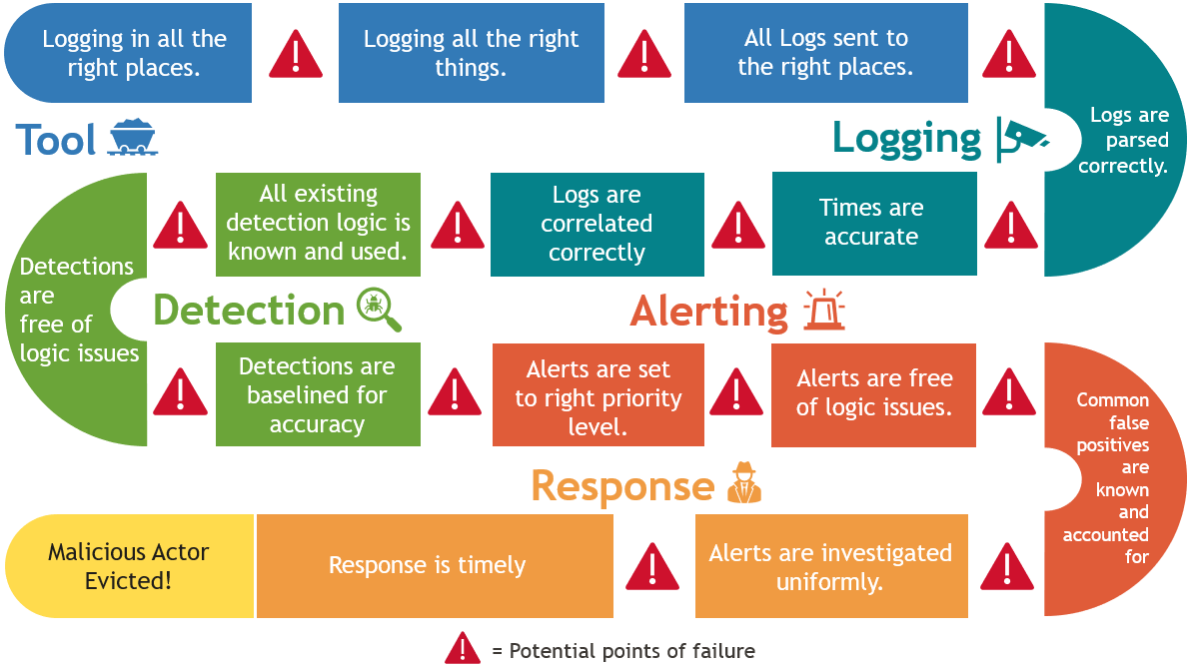
There are many steps in threat detection and each one must be followed for most techniques. Technique coverage can often only be approximated after attempting and cataloging the differences among many procedures. Knowledge of your coverage is your map of the battlefield, and influences your decisions and directives and thus the activity that occurs at the strategic, operational, and tactical levels.
If you are relying on vendor coverage without further extension or customization then you are susceptible to anyone who can defeat that vendor’s security product. By having a map, doing analysis, and designing behavior-based threat detections you are creating a delta that will make sure you’re not the slowest man running from the bear.
Currently, NetSPI offers this under the Breach and Attack Simulation Services. Collaboratively as a purple team, we will develop capability abstracts and identify base conditions for threat detection, visibility gaps, and areas in the detection pipeline where an earlier stage is present but not carried forward by executing many procedures across the MITRE ATT&CK Framework.
Explore More Blog Posts

Extracting Sensitive Information from Azure Load Testing
Learn how Azure Load Testing's JMeter JMX and Locust support enables code execution, metadata queries, reverse shells, and Key Vault secret extraction vulnerabilities.

3 Key Takeaways from Continuous Threat Exposure Management (CTEM) For Dummies, NetSPI Special Edition
Discover continuous threat exposure management (CTEM) to learn how to bring a proactive approach to cybersecurity and prioritize the most important risks to your business.
How Often Should Organizations Conduct Penetration Tests?
Learn how often organizations should conduct penetration tests. Discover industry best practices, key factors influencing testing frequency, and why regular pentesting is essential for business security.