Collecting Contacts from zoominfo.com
For our client engagements, we are constantly searching for new methods of open source intelligence (OSINT) gathering. This post will specifically focus on targeting client contact collection from a site we have found to be very useful (zoominfo.com) and will describe some of the hurdles we needed to overcome to write automation around site scraping. We will also be demoing and publishing a simple script to hopefully help the community add to their OSINT arsenal.
Reasons for Gathering Employee Names
The benefits of employee name collection via OSINT are well-known within the security community. Several awesome automated scrapers already exist for popular sources (*cough* LinkedIn *cough*). A scraper is a common term used to describe a script or program that parses specific information from a webpage, often from an unauthenticated perspective. The employee names scraped (collected/parsed) from OSINT sources can trivially be converted into email addresses and/or usernames if one already knows the target organization’s formats. Common formats are pretty intuitive, but below are a few examples.
Name example: Jack B. Nibble

On the offensive side, a few of the most popular use cases for these collections of employee names, emails, and usernames are:
- Credential stuffing
- Email phishing
- Password spraying
Credential stuffing utilizes breach data sources in an attempt to log into a target organization’s employees’ accounts. These attacks rely on the stolen credentials being recycled by employees on the compromised platforms, e.g., Jack B. Nibble used his work email address with the password JackisGreat10! to sign up for LinkedIn before a breach and he is reusing the same credentials for his work account.
Email phishing has long been one of the easiest ways to breach an organization’s perimeter, typically needing just one user to fall victim to a malicious email.
Password spraying aims to take the employee names gathered via OSINT, convert them into emails/usernames, and attempt to use them in password guessing attacks against single factor (typically) management interfaces accessible from the internet.
During password spraying campaigns, attackers will guess very common passwords – think Password19 or Summer19. The goal of these password sprays is to yield at least one correct employee login, granting the attacker unauthorized access to the target organization’s network/resources in the context of the now compromised employee. The techniques described here are not only utilized by ethical security professionals to demonstrate risk, they are actively being exploited by state sponsored Cyber Actors.
Issues with Scraping
With the basic primer out of the way, let’s talk about scraping in general as we lead into the actual script. The concepts discussed here will be specific to our example but can also be applied to similar scenarios. At their core, all web scrapers need to craft HTTP requests and parse responses for the desired information (Burp Intruder is great for ad-hoc scraping). All of the heavy lifting in our script will be done with Python3 and a few libraries.
Some of the most common issues we’ve run into while scraping OSINT sources are:
- Throttling (temporary slow-downs based on request rate)
- Rate-limiting (temporary blocking based on request rate)
- Full-blown bans (permanent blocking based on request rate)
While implementing our scraper for zoominfo.com, our biggest hurdle was throttling and ultimately rate-limiting. The site employs a very popular DDoS protection and mitigation framework in Cloudflare’s I’m Under Attack Mode (IUAM). The goal of IUAM is to detect if a site is being actively attacked by a botnet that is attempting to take the site offline. If Cloudflare decides a person is accessing multiple different pages on a website too rapidly, IUAM will send a JavaScript challenge to that person’s browser, similar to this:
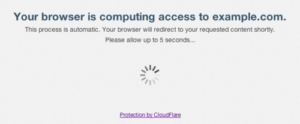
As part of normal browsing activity via web browser, this challenge would be automatically solved, a cookie would be set, and the user would go about their merry way. The issue arises when we are using an automated script that cannot process JavaScript and does not automatically set the correct cookies. At this point, IUAM would hold our script hostage and it would not be able to continue scraping. For our purposes, we will call this throttling. Another issue arises if we are able to solve the IUAM challenge but are still crossing Cloudflare’s acceptable thresholds for number of requests made within certain time frames. When we cross that threshold, we are hit with a 429 response from the application, which is the HTTP status code for Too Many Requests. We will refer to this as rate-limiting. Pushing even faster may result in a full-blown ban, so we will not poke Cloudflare too hard with our scraper.
Dealing with Throttling and Rate-limiting
In our attempts to push the script forward, we needed to overcome throttling and rate-limiting to successfully scrape. During initial tests, we noticed simple delays via sleep statements within our script would prevent the IUAM from kicking in, but only for a short while. Eventually IUAM would take notice of us, so sleep statements alone would not scale well for most of our needs. Our next thought was to implement Tor, and just switch exit nodes each time we noticed a ban. The Tor Stem library was perfect for this, with built-in control for identifying and programmatically switching exit nodes via Python. Unfortunately, after implementing this idea, we realized zoominfo.com would not accept connections via Tor exit nodes. Another simple transition would have been to use other VPN services or even switching via VPS’, but again, this solution would not scale well for our purposes.
I had considered just spinning up an invisible or headless browser to interact with the site that could also interact with the JavaScript. In this way, Cloudflare (and hopefully any of our future targets) would only see a ‘normal’ browser interacting with their content, thus avoiding our throttling issues. While working to implement this idea, I was pointed instead to an awesome Python library called cloudscraper: https://pypi.org/project/cloudscraper/.
The cloudscraper library does all the heavy lifting of interacting with the JavaScript challenges and allows our scraper to continue while avoiding throttling. We are then only left with the issue of potential rate-limiting. To avoid this, our script also has built-in delays in an attempt to appease Cloudflare. We haven’t come up with an exact science behind this, but it appears that a delay of sixty seconds every ten requests is enough to avoid rate-limiting, with short random delays sprinkled in between each request for good measure.
python3 zoominfo-scraper.py -z netspi-llc/36078304 -d netspi.com
[*] Requesting page 1 [+] Found! Parsing page 1 [*] Random sleep break to appease CloudFlare [*] Requesting page 2 [+] Found! Parsing page 2 [*] Random sleep break to appease CloudFlare [*] Requesting page 3 [+] Site returned status code: 410 [+] We seem to be at the end! Yay! [+] Printing email address list adolney@netspi.com ajones@netspi.com aleybourne@netspi.com
..output truncated..
[+] Found 49 names!
Preventing Automated Scrapers
Vendors or website owners concerned about automated scraping of their content should consider placing any information they deem ‘sensitive’ behind authentication walls. The goal of Cloudflare’s IUAM is to prevent DDoS attacks (which we are vehemently not attempting), with the roadblocks it brings to automated scrapers being just an added bonus. Roadblocks such as this should not be considered a safeguard against automated scrapers that play by the rules.
Download zoominfo-scraper.py
This script is not intended to be all-encompassing for your OSINT gathering needs, but rather a minor piece that we have not had a chance to bolt on to a broader toolset. We are presenting it to the community because we have found a lot of value with it internally and hope to help further advance the security community. Feel free to integrate these concepts or even the script into your own toolsets.
The script and full instructions for use can be found here: https://github.com/NetSPI/HTTPScrapers/tree/master/Zoominfo
Explore More Blog Posts

Confidence Over Noise: Introducing Continuous AI Findings Validation
NetSPI's Continuous AI Findings Validation service applies expert human judgment to AI-generated security findings, eliminating false positives and verifying severity so security teams can trust, prioritize, and act with confidence instead of chasing noise.

Bypassing Microsoft Entra Conditional Access Policies via Nested App Authentication
Discover how attackers bypassed Microsoft Entra Conditional Access Policies using Nested App Authentication (NAA) flows in this technical vulnerability breakdown.

I’m Just Asking Questions: Social Engineering as a Reporter
Dive into this real-world social engineering assessment where a fake anonymous tip and an adversary-in-the-middle framework tested the limits of an organization's security policies.