Mike Doyle is a Principal Consultant at NetSPI. He has over a decade of experience in the information security field with FleetCor, a global business payments company, and Cigital/Snopsys, where he focused on software security. Mike has a wide array of skills and knowledge in penetration testing, code review, threat modeling, IoT security, red teaming, mobile security assessments, and application security. Prior to his security career, he worked as a software developer. He has spoken at BSidesATL, LASCON, and the ISC2 congress.
For those engaged in the timely production of high-quality software, threat modeling is an invaluable method to minimize rework. Design defects can include useless code, or “cruft” and can be costly to fix. But the manual process of threat modeling doesn’t always fit well into ever-tightening iterative development methodologies.
Fortunately, our industry is making big strides in the direction of automating threat modeling. I’ve explored as many of these tools as I can while looking for something that works best for us here at NetSPI. While I’m quite optimistic about the very near future of threat modeling automation, I’ve got my reservations. These reservations can be generalized as conjectures.
If you are buying or building threat modeling automation, here are three conjectures to take into consideration.
Conjecture 1: The Only Automation is Semi-Automation
Don’t expect to run a threat modeling process entirely free of human care and attention. No matter your methodology, threat modeling operates on ideas about software – and the outputs of threat modeling are other, better ideas about software. Completely automating the improvement of these ideas requires expressing them in a useful format and yielding the resulting better ideas in a format suitable for implementation by another automated system.
You see where this is going.
It also requires producing genuine improvements which would unquestionably result in a better system overall: error free output.
So, let’s consider how semi-automation is a more realistic expectation than full automation by looking at this input-process-output (IPO) model in more detail, from bottom to top.
Automating the Outputs
The results of a threat modeling assessment do not need to be consumable as non-functional requirements (NFRs). They can inform coding standards, product roadmaps, build procedures, test plans, monitoring activities, and more.
For example: let’s say the consumer-grade IoT device your team is building requires customizations to the kernel level containerization system for OTA updates. Your product manager sees this as an indicator of how cutting edge this device is compared to the market, while your architect sees this as a necessary annoyance. But what the threat modeler sees is an unmanaged attack surface, accessible from the network, written in C, executing in Ring 0.
What can your team do with this information, besides draft security requirements? Adjust your static analysis strategy? Amend your vendor management boilerplate to mandate relevant training? Whip up a fuzzing protocol? How many of these represent automatable opportunities?
Threat modeling is a decision support process. You can automate aspects of it, but you’ll be limited by the amount of decision-making that is automated.
Now, you may have scripts available to automate the creation of backlog items—Jira tickets and the like. Keep in mind that 90 percent of all security tooling outputs are false positives. Threat modeling automation systems make no promises of being any different. So, you can either devote human care and attention to triaging the results, or you can let the implementation team do the triage work themselves. Either way, there’s still work to be done.
Many organizations are beginning to approach their going software concerns by finding an optimal balance considering known limitations. It isn’t security versus usability. It’s making sure our products are suitably usable, secure, performant, testable, resilient, scalable, marketable, et cetera.
So, your turnkey end-to-end threat modeling automation has to be able to recognize and accommodate other requirements in terms of the product’s usability, reliability, marketability, scalability, et ceterability. If it doesn’t, it will fall to you to strike the right balance. And if you’re the one striking a balance, you don’t have a fully automated system.
Automating the Inputs
What tools do your security architects use? The ones I work with mostly use whiteboards. Many use team collaboration / CMS software like Confluence. Some use drawing tools like Visio. Does anyone still use Rational Rose?
If your threat modeling automation can meaningfully parse this information, great. If not, and you have to reproduce the architect’s design, then you won’t achieve full automation.
Otherwise, what inputs can be automatically fed into your threat modeling tool?
Automatic scanning of Infrastructure-as-Code files can bring to light threats to the infrastructure. They may not have much to say about the actual software, though. And automatic code scanners tend to ignore those values of quality that I enumerated above.
Finally, threat modeling tools that scan implementation artifacts often lack efficiency. You’ve already built to your design. Any findings produced by a scanner are opportunities for rework, and as I said at the beginning, threat modeling is supposed to minimize rework.
Conjecture 2: Your Tool’s Diagrams and Your Team’s Diagrams Should Be Compatible
Whether your tool consumes or emits them, diagrams of the subject system must be recognizable by the implementation team as being a genuine, faithful reflection of the values of that system. Tools that invite you to re-invent or re-think the system’s architecture in a new schema tend to miss the mark.
This is not to say that re-diagramming is always problematic. Architecture diagrams must reflect the values of the organization, such as structure, redundancy, symmetry, priority, urgency, or flow. This helps them present the system—especially its attack surfaces—naturally. Automatically generated diagrams tend to disregard these values.
Conjecture 3: Your Tool’s Guidance Should Be Delivered with Humility
As mentioned earlier, threat modeling operates on ideas about software and its outputs include better ideas about software. The best tools and techniques will lead the threat modeler to the best ideas, faster.
But architecture works with abstractions about systems. Lacking a complete architecture description, any threat modeling tool is working on incomplete input. And who has time to produce complete architecture documents?
Have you seen a 300-page architecture document? Probably. But have you ever seen a 300-page architecture document that was up to date?
The problem arises when a threat modeling tool can’t adjust to the subtleties of your software. If a tool mistakes design elements for threats, you’ll be required to spend time adjusting its output.
Sometimes your tool will just be wrong through no fault of its own and it is easier to ignore the tool than to correct it.
Your Threat Modeling System Shouldn’t Be Repudiating Raisins
Some design intricacies are difficult to articulate. Consider the ‘R’ in STRIDE: Repudiation.
The Orange Book lists accountability as a fundamental requirement of computer security:
“Audit information must be selectively kept and protected so that actions affecting security can be traced to the responsible party. A trusted system must be able to record the occurrences of security-relevant events in an audit log. The capability to select the audit events to be recorded is necessary to minimize the expense of auditing and to allow efficient analysis. Audit data must be protected from modification and unauthorized destruction to permit detection and after-the-fact investigations of security violations.”
Clearly, the non-repudiation of audit logs is an important aspect of a system, and conventions around logging should be designed to be of adequate depth and granularity, and resilient against forging and deletion.
But what’s true for audit logs isn’t true for every single aspect of every single software product.
Suppose you were threat modeling a smart appliance, like a smart toaster. We want to make a simple change with little security impact, perhaps extending its capabilities to allow it to handle raisin bread. What are our repudiation concerns? What does that mean? Someone fakes a raisin? The question is trivial, and pondering it is not a great use of time.
A little time spent deciding what actions really warrant logging is time well spent. Applying a blanket repudiation standard to every system element, on the other hand, is tedious. By extension, tools that alert to every form of threat every time you make an adjustment to your architecture are tedious. A tool should be able to measure the threat at the proper scale. Tool output should be non-punitive.
Threats Can Be Features
Moreover, sometimes repudiation is not an attack but a feature. Consider repudiation in the following system contexts: ballot secrecy, civil-rights-related anonymity, digital cash, drive encryption.
For these systems, the implementation of some non-repudiation controls is antithetical to the business goal of the system.
Similarly, many systems offer user-impersonation features for support purposes, basically spoofing-as-a-service. Such functionality needs to thread a tight needle of security attention. Uniformly treating all forms of spoofing as threats is incorrect.
Should tooling let users treat threats as security features? Maybe. These are edge cases. Perhaps this is a nice-to-have. It would suffice to have a tool treat its recommendations as suggestions for consideration.
Final Thoughts
Threat modeling is a time-consuming process and deserving of as much automation as we can throw at it. The teams making the current generation of tooling are right to be proud of their products. But these tools have limitations to be kept in mind, whether you are building or buying them.
[post_title] => Three Threat Modeling Automation Conjectures
[post_excerpt] => If you are buying or building threat modeling automation, here are three conjectures to take into consideration.
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => threat-modeling-automation-conjectures
[to_ping] =>
[pinged] =>
[post_modified] => 2022-12-16 10:51:49
[post_modified_gmt] => 2022-12-16 16:51:49
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://www.netspi.com/?p=26541
[menu_order] => 359
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[1] => WP_Post Object
(
[ID] => 26497
[post_author] => 72
[post_date] => 2021-09-28 07:00:00
[post_date_gmt] => 2021-09-28 12:00:00
[post_content] =>
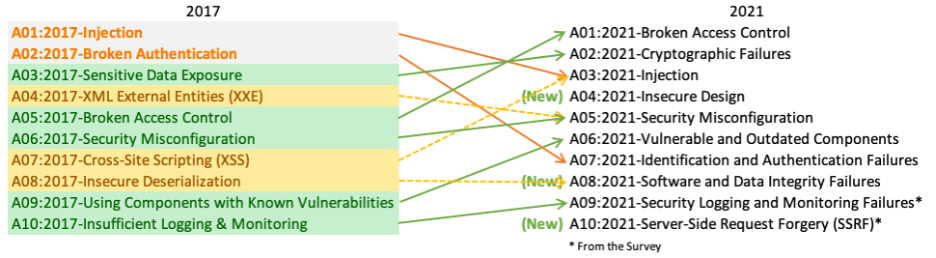
The Open Web Application Security Project (OWASP) celebrated its 20th anniversary on Friday, September 24. On the same day, it released updates to the OWASP Top 10 – for the first time since 2017. Big steps toward application security maturity!
I attended OWASP Executive Director Andrew van der Stock’s warmup presentation where he spoke about the updates. He mentioned that many of the changes stem from improvements in the methodology brought in by a new OWASP co-lead, Brian Glas. Notably, this version of the OWASP Top 10 is “more data-driven than ever.”
It sourced its data from pentesting vendors, bug bounty vendors, and organizations that contribute internal testing data. This year, the authors gathered data from the testing of over 500,000 applications. There are also two risks on the list that were sourced from a community survey of front-line application security and development experts. You can read more about the OWASP Top 10 methodology online here and below is an overview of the changes, 2017 versus 2021.
Speaking of front-line application security and development experts, I wanted to dig a little deeper into the OWASP Top 10 2021 and hear from folks who are influenced by the update. So, I reached out to a few of my NetSPI colleagues who specialize in application security and application penetration testing – Managing Director Nabil Hannan and Practice Director Antti Rantasaari – well as a bench of noteworthy AppSec experts – Diana Kelley (Security Curve), Jeff Williams (Contrast Security), and Peter Lukas (Code42) – to get their take on the most critical changes and how it will impact the security community.
TL;DR – 5 key themes observed across the responses
A04: Insecure Design receives a warm welcome.
Broken Access Control moving to the top of the list is timely, and an indicator of a shift in AppSec strategy.
Cloud adoption is driving the prevalence of Server-Side Request Forgery (SSRF).
A strong focus on security within the SDLC; Approaching security challenges at the root.
The list moves past specific individual vulnerabilities and focuses on categories of risk.
What surprises or interests you most about the OWASP Top 10 2021?
I’ll start! For me, the fall of Injection was the most surprising change. Injection has been the highest-ranked risk since 2007. The 2021 version of the Top 10 sees Injection fall to third place, even with XSS (which was A02 in 2010) getting rolled into it. While there are several factors related to this change, the efficacy of the OWASP Top 10 as an awareness-raising tool, and the growing use of secure-by-default frameworks which implement protections against many forms of injection are most prominent.
Here’s what our expert panel found most shocking or interesting about the updated Top 10:
Peter Lukas, Security Architect, Code42:
“The updates to the OWASP Top 10 are out, and there are some noteworthy conclusions that can be drawn from them. Most interestingly, Broken Authentication has fallen from position A02 to position A07, while Broken Access Control has surged to the very top of the list! This tells me that we’re getting better at locking the front door, and we really need to shift our focus on where users are entitled to go once inside our application environment.”
Antti Rantasaari, Practice Director, NetSPI
“The OWASP Top 10 2021 moves a bit further from vulnerabilities and more towards design and the SDLC. The Top 10 list has been more vulnerability-focused in the past, and now we are seeing very broad categories, like Insecure Design. Broken Access Control moving to A01 makes a lot of sense – that is the most common high-severity vulnerability that we identify during our penetration testing.”
Diana Kelley, CTO and Founding Partner, Security Curve:
“Not exactly surprised, but it was really interesting and timely to see Broken Access Control move to the top of the list. I am a little disappointed to see Cryptographic Failures up at number two because we have a lot of great tools – many that are built into the most commonly used development frameworks – to help us implement crypto and crypto key management securely.”
Nabil Hannan, Managing Director, NetSPI:
“The most surprising change – in a good way – is the fact that the list now includes Insecure Design. Having worked in the AppSec space for the last 15 years, from empirical data I’ve seen that the split between design flaws and security bugs is 50/50. The challenge with design flaws is that it usually requires a human to identify the vulnerability, usually through some type of secure design review or threat modeling activity that focuses on breaking the software. This indicates that organizations are going beyond just identifying security bugs and are starting to look for design-level flaws more proactively.
Additionally, it is important to note that organizations need to maintain a living list of the most common types of vulnerabilities that they want to eliminate in their organization’s software. Usually, this needs to be a list of top 3-4 vulnerabilities to ensure there’s a proper focus on the vulnerabilities. Usually, this can be done with real data from various types of security assessments that are being performed to identify and fix vulnerabilities. These types of lists should be used to drive change, simply publishing a list won’t drive change, but using the list to fix –or if possible, eradicate – certain vulnerabilities is necessary.”
Jeff Williams, Co-Founder and CTO, Contrast Security:
“I was most glad to see that the scope of the Top 10 has expanded to include the entire software supply chain and the entire software lifecycle. In particular, I welcome the new Insecure Design item which will encourage practices like threat modeling and security architecture. I also think it’s great that, in the wake of the SolarWinds and Kasaya breaches, the team included the Software Integrity category. This will help to ensure that the software we create is actually the software that gets delivered into production and doesn’t contain malware.
The data science behind the OWASP Top 10 is phenomenal. Data from over 500 thousand real-world applications and APIs. I really wish they had included data about real-world attacks as this would have greatly expanded our understanding about which of these vulnerabilities are being attacked, how prevalent are the attacks, and which attacks actually reach their targeted vulnerability.”
There are three new vulnerabilities on the list: Server-Side Request Forgery (SSRF), Software and Data Integrity Failures, and Insecure Design. Why do you think these vulnerabilities have become more prevalent?
It is important to note that these three new categories are the result of an important change in the data gathering methodology. In previous versions of the OWASP Top 10, data contributors were asked to report statistics on defect discovery findings that mapped to 70 specific CWEs (weakness categories, as defined by MITRE’s Common Weakness Enumeration project). Data for any findings that did not map to those CWEs were not previously gathered. This resulted in a huge selection bias. How huge? For the first time, the 2021 Top 10 instead asked data contributors to submit statistics for all CWEs, resulting in responses with findings data for almost 700 CWEs! Considering this 90% increase in CWEs evaluated, it’s not surprising to see the emergence of these three new categories: SSRF, Software and Data Integrity Failures, and Insecure Design.
More thoughts on the three new categories from our AppSec experts:
Diana Kelley, CTO and Founding Partner, Security Curve:
“I am absolutely thrilled that Insecure Design was added as a new category. Past Top 10s have focused on the technical implementation, which occurs after the design phase. However, a lot of mistakes are introduced through a problematic design... as you might imagine from it being reflected in this list, this happens a lot. The earlier a problem can be identified and addressed, the better. Better, more security-aware design processes should result in stronger, more resilient software.
I’m also very happy to see Software and Data Integrity because, as described by OWASP, this is getting into the area of software supply chain assurance. As we saw with SolarWinds, even patches and updates can be an infection vector. Highlighting the importance of checking code updates before applying them is welcome and should contribute to overall software security at organizations.
SSRF is an interesting addition. This has always been an issue to watch for, but one of the reasons it might be becoming more prevalent now is the ubiquity of application designs built around REST – service-based architecture and microservices, particularly those delivered via the cloud. As REST becomes a more prevalent mode of application design and delivery, the more we would expect misconfigured services to add to this problem. The fact that we're seeing it on the list reflects the reality of how modern applications are built, so I'm glad to see it there.”
Peter Lukas, Security Architect, Code42:
“The inclusion of Insecure Design (A04:2021), Software and Data Integrity Failures (A07:2021) and Server-Side Request Forgery (A09:2021) reflect trends we’ve been observing in our own penetration testing and bug bounty programs. The prevalence of containerized services, reverse-proxies, and other cloned-from-the-repo microservices are making it easy for our developers to get code out the door while giving attackers the opportunity to inconspicuously take advantage of the trust we’ve placed in common automation and orchestration components. Today, our developers are not only tasked with securing the application but, thanks to those components, the application environment as well. I can see this added responsibility reflected in these updates for 2021.”
Antti Rantasaari, Practice Director, NetSPI
“Like OWASP states, the Top 10 list is intended to bring awareness to application security risks, and two of the new categories, Software and Data Integrity Failures and Insecure Design, are certainly important for secure software development. These issues may not be more prevalent than before; rather, their addition reflects OWASP's move away from top 10 vulnerabilities to the top 10 application security categories.
SSRF is the only individually listed vulnerability while the other items on the Top 10 list are broad categories. Access to REST APIs and cloud provider metadata services via SSRF, most commonly restricted to GET requests, have increased the impact and raised the profile of the attack.”
Jeff Williams, Co-Founder and CTO, Contrast Security:
“SSRF is a great addition. Even though the backward-looking data science doesn’t support it, I think it’s smart to include a few forward-looking items in the list. This is a practice I started when I ran the OWASP Top 10 project many years ago. SSRF in particular is a serious problem for modern API-driven applications and is clearly where the puck is going. Both Software Integrity and Insecure Design are interesting items that dramatically expand the scope of the OWASP Top 10. I think it’s great that the team is moving past specific individual vulnerabilities and focusing on whole categories of problem, as well as expanding to covering parts of the software development lifecycle that are the root cause of problems.”
Nabil Hannan, Managing Director, NetSPI:
“The three new vulnerabilities in the list are indicative of how the industry is shifting its focus on security from being a check-the-box activity to proactively identifying and fixing vulnerabilities. Regarding SSRF with more and more organizations migrating to the cloud and adopting an API based design paradigm, SSRF is becoming more prevalent. Regarding Data Integrity Failures and Insecure Design, there is more focus these days on making sure software systems are being designed properly and whether the design is secure or not – which is a step in the right direction to proactively building secure software.”
Final Thoughts on the OWASP Top 10 2021
The 2017 OWASP Top 10 had data from 50,000 assessments of web applications. This year’s version has ten times that amount. In addition, this year the data-gathering process required contributors to differentiate between initial test data and retest data. Previous versions of the Top 10 treated initial-test and retest data identically, which is problematic for defect discovery methods that let developers quickly and inexpensively rescan their code. Such behavior can cause ballooning of defects easily discovered through certain automated methods. I’m glad to see this problem solved in this year’s methodology.
Injection findings moving down on the list is a testament to the effectiveness of the OWASP Top 10. Collaborating to create awareness for the most common web application security risks is critical. Along those same lines, for years people have been incorporating the OWASP Top 10 into their standards, for instance, PCI. OWASP had been averse to this, considering it is a volunteer organization. However, they’ve had a change of heart and the 2021 release includes guidance on how to use it as a standard and how to begin to develop an application security program with it.
However you choose to leverage the OWASP Top 10, it’s evident that – queue Bob Dylan – the times they are a-changin'. I applaud the OWASP authors and contributors for making the necessary updates to the list and its methodology. It’s a significant step towards improving the maturity of the world’s application security programs and practices.
[post_title] => AppSec Experts React to the OWASP Top 10 2021
[post_excerpt] => Read web application security experts’ thoughts on the updated OWASP Top 10 2021. Get their take on the most critical changes and how it will impact the cybersecurity community.
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => appsec-experts-react-owasp-top-10-2021
[to_ping] =>
[pinged] =>
[post_modified] => 2022-12-16 10:51:51
[post_modified_gmt] => 2022-12-16 16:51:51
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://www.netspi.com/?p=26497
[menu_order] => 364
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[2] => WP_Post Object
(
[ID] => 20850
[post_author] => 72
[post_date] => 2021-01-19 07:00:12
[post_date_gmt] => 2021-01-19 07:00:12
[post_content] =>
A semi-criticalvulnerabilitywas uncovered in the popularcontainer orchestration platform Kubernetes lastmonth: CVE 2020 8554.
I say “semi-critical” because it scores a paltry 6.3 on the Common Vulnerability Scoring System (CVSS). But two things make this vulnerability interesting and worth studying: first, it affects all versions of Kubernetes. Second, it cannot be patched. Whether you have Kubernetes in your wheelhouse or not, you do notwant vulnerabilities that cannotbe patched,particularly ones that affect all versions of an application.
In this article, I will explore CVE 2020 8554: how it happened, how it was found, and the lessons we can all learn from it.
How the Kubernetes MitM vulnerability happens:
It cannot be patched because it is not an implementation bug, meaningthere were no mistakes made in code implementation. It happened because Kubernetes allowsany tenant in a multi-tenant cluster, with certain control over their own routing,toreroute the traffic of any other tenants on that cluster.
Kubernetes provides a matryoshka nestingdoll of abstraction layers. You can have one or many “clusters,” inside of which are one or many “nodes.” Each node maps to a computer (physical or virtual) running one or many “pods” of one or many “containers.” Inside each container live the software components that comprise your application. Each layer of abstraction has its own scope of policy, or its configuration. Additionally, Kubernetes has configuration for “namespaces” which cut across layers and are useful for providing isolation for the different tenants of your application.
A traditional network will have infrastructure services likeDomain Name System (DNS), Address Resolution Protocol (ARP), or Network Address Translation (NAT) to ensure that client requests find their way to the servers it needs. With Kubernetes,client requests must find their way to the software running in the appropriate container (inside the pod, inside the node, inside the cluster).This process can be cumbersome. Kubernetes lets you manage these routes with configuration it calls “services.” You can set up load balancing services and external IP services which function as physical load balancers and the NAT translation that happens at your network’s edge.
The MitM vulnerability can exist here becausethese services are configured at the pod layer, but you can have pods with different tenants alongside one another.
No one is to blame for the vulnerability. It is a result of two decisions that unknowingly created a gap: 1) to let Kubernetes users configure services in a certain way and 2) To let clusters have multiple tenants. No one could foresee the security vulnerabilitythat these two requirements would create when taken together.
Why not put a limit on the configurations?
Why not have single-tenant clusters? Or why not prevent tenants from altering these services? Many organizations do, but there are limits to the scalability they can achieve. And for those that do, there are third party solutions to help prevent and detect exploits of this kind of vulnerability.
How the Kubernetes MitM vulnerability was found:
“The most exciting phrase to hear in science, the one that heralds new discoveries, is not ‘Eureka!’ but ‘That’s funny…’”— Isaac Asimov
Architecture flaws are notoriously hard to identify. Finding them typically requires a deep understanding of the security implications of a lengthy set of decisions. This points to the importance of manual penetration testing.Gifted penetration testers or analysts who can perform manual protocol analysis or threat modelingare essential in finding vulnerabilities that tools cannot.
In this case, it was a builder that found the vulnerability. As they write intheir blog post on the discovery, Etienne Champetierwas deploying a Kubernetes cluster for a client when something that should’ve worked failed. A workaround that also should’ve worked also failed. Finally, something that never should’ve worked was successful.Etienne identified the security implications of the problems and reported them to the Kubernetes security team.
Lessons learned from the Kubernetes MitM vulnerability:
No form of static, dynamic, or interactive scanner could have found this flaw.I can’t help but reflect on our industry’s reliance onlightning-fast scanning of applicationsto keep defects from hitting production.Lightweight security testing via scanners is a valuable tool. A vital one, in fact. But it is notthe whole toolbox.Only a skilled technologist who was willing to get elbows-deep in the technology could have discovered this flaw. Manual security testing of applications is critical to think like a real-world adversary.
[post_title] => Lessons Learned From The Kubernetes Man-in-the-Middle Vulnerability
[post_excerpt] => Two things make this vulnerability interesting: first, it affects all versions of Kubernetes. Second, it cannot be patched.
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => lessons-learned-kubernetes-man-middle-vulnerability
[to_ping] =>
[pinged] =>
[post_modified] => 2021-04-14 07:01:41
[post_modified_gmt] => 2021-04-14 07:01:41
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://www.netspi.com/?p=20850
[menu_order] => 435
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
)
[post_count] => 3
[current_post] => -1
[before_loop] => 1
[in_the_loop] =>
[post] => WP_Post Object
(
[ID] => 26541
[post_author] => 72
[post_date] => 2021-10-13 15:19:33
[post_date_gmt] => 2021-10-13 20:19:33
[post_content] =>
For those engaged in the timely production of high-quality software, threat modeling is an invaluable method to minimize rework. Design defects can include useless code, or “cruft” and can be costly to fix. But the manual process of threat modeling doesn’t always fit well into ever-tightening iterative development methodologies.
Fortunately, our industry is making big strides in the direction of automating threat modeling. I’ve explored as many of these tools as I can while looking for something that works best for us here at NetSPI. While I’m quite optimistic about the very near future of threat modeling automation, I’ve got my reservations. These reservations can be generalized as conjectures.
If you are buying or building threat modeling automation, here are three conjectures to take into consideration.
Conjecture 1: The Only Automation is Semi-Automation
Don’t expect to run a threat modeling process entirely free of human care and attention. No matter your methodology, threat modeling operates on ideas about software – and the outputs of threat modeling are other, better ideas about software. Completely automating the improvement of these ideas requires expressing them in a useful format and yielding the resulting better ideas in a format suitable for implementation by another automated system.
You see where this is going.
It also requires producing genuine improvements which would unquestionably result in a better system overall: error free output.
So, let’s consider how semi-automation is a more realistic expectation than full automation by looking at this input-process-output (IPO) model in more detail, from bottom to top.
Automating the Outputs
The results of a threat modeling assessment do not need to be consumable as non-functional requirements (NFRs). They can inform coding standards, product roadmaps, build procedures, test plans, monitoring activities, and more.
For example: let’s say the consumer-grade IoT device your team is building requires customizations to the kernel level containerization system for OTA updates. Your product manager sees this as an indicator of how cutting edge this device is compared to the market, while your architect sees this as a necessary annoyance. But what the threat modeler sees is an unmanaged attack surface, accessible from the network, written in C, executing in Ring 0.
What can your team do with this information, besides draft security requirements? Adjust your static analysis strategy? Amend your vendor management boilerplate to mandate relevant training? Whip up a fuzzing protocol? How many of these represent automatable opportunities?
Threat modeling is a decision support process. You can automate aspects of it, but you’ll be limited by the amount of decision-making that is automated.
Now, you may have scripts available to automate the creation of backlog items—Jira tickets and the like. Keep in mind that 90 percent of all security tooling outputs are false positives. Threat modeling automation systems make no promises of being any different. So, you can either devote human care and attention to triaging the results, or you can let the implementation team do the triage work themselves. Either way, there’s still work to be done.
Many organizations are beginning to approach their going software concerns by finding an optimal balance considering known limitations. It isn’t security versus usability. It’s making sure our products are suitably usable, secure, performant, testable, resilient, scalable, marketable, et cetera.
So, your turnkey end-to-end threat modeling automation has to be able to recognize and accommodate other requirements in terms of the product’s usability, reliability, marketability, scalability, et ceterability. If it doesn’t, it will fall to you to strike the right balance. And if you’re the one striking a balance, you don’t have a fully automated system.
Automating the Inputs
What tools do your security architects use? The ones I work with mostly use whiteboards. Many use team collaboration / CMS software like Confluence. Some use drawing tools like Visio. Does anyone still use Rational Rose?
If your threat modeling automation can meaningfully parse this information, great. If not, and you have to reproduce the architect’s design, then you won’t achieve full automation.
Otherwise, what inputs can be automatically fed into your threat modeling tool?
Automatic scanning of Infrastructure-as-Code files can bring to light threats to the infrastructure. They may not have much to say about the actual software, though. And automatic code scanners tend to ignore those values of quality that I enumerated above.
Finally, threat modeling tools that scan implementation artifacts often lack efficiency. You’ve already built to your design. Any findings produced by a scanner are opportunities for rework, and as I said at the beginning, threat modeling is supposed to minimize rework.
Conjecture 2: Your Tool’s Diagrams and Your Team’s Diagrams Should Be Compatible
Whether your tool consumes or emits them, diagrams of the subject system must be recognizable by the implementation team as being a genuine, faithful reflection of the values of that system. Tools that invite you to re-invent or re-think the system’s architecture in a new schema tend to miss the mark.
This is not to say that re-diagramming is always problematic. Architecture diagrams must reflect the values of the organization, such as structure, redundancy, symmetry, priority, urgency, or flow. This helps them present the system—especially its attack surfaces—naturally. Automatically generated diagrams tend to disregard these values.
Conjecture 3: Your Tool’s Guidance Should Be Delivered with Humility
As mentioned earlier, threat modeling operates on ideas about software and its outputs include better ideas about software. The best tools and techniques will lead the threat modeler to the best ideas, faster.
But architecture works with abstractions about systems. Lacking a complete architecture description, any threat modeling tool is working on incomplete input. And who has time to produce complete architecture documents?
Have you seen a 300-page architecture document? Probably. But have you ever seen a 300-page architecture document that was up to date?
The problem arises when a threat modeling tool can’t adjust to the subtleties of your software. If a tool mistakes design elements for threats, you’ll be required to spend time adjusting its output.
Sometimes your tool will just be wrong through no fault of its own and it is easier to ignore the tool than to correct it.
Your Threat Modeling System Shouldn’t Be Repudiating Raisins
Some design intricacies are difficult to articulate. Consider the ‘R’ in STRIDE: Repudiation.
The Orange Book lists accountability as a fundamental requirement of computer security:
“Audit information must be selectively kept and protected so that actions affecting security can be traced to the responsible party. A trusted system must be able to record the occurrences of security-relevant events in an audit log. The capability to select the audit events to be recorded is necessary to minimize the expense of auditing and to allow efficient analysis. Audit data must be protected from modification and unauthorized destruction to permit detection and after-the-fact investigations of security violations.”
Clearly, the non-repudiation of audit logs is an important aspect of a system, and conventions around logging should be designed to be of adequate depth and granularity, and resilient against forging and deletion.
But what’s true for audit logs isn’t true for every single aspect of every single software product.
Suppose you were threat modeling a smart appliance, like a smart toaster. We want to make a simple change with little security impact, perhaps extending its capabilities to allow it to handle raisin bread. What are our repudiation concerns? What does that mean? Someone fakes a raisin? The question is trivial, and pondering it is not a great use of time.
A little time spent deciding what actions really warrant logging is time well spent. Applying a blanket repudiation standard to every system element, on the other hand, is tedious. By extension, tools that alert to every form of threat every time you make an adjustment to your architecture are tedious. A tool should be able to measure the threat at the proper scale. Tool output should be non-punitive.
Threats Can Be Features
Moreover, sometimes repudiation is not an attack but a feature. Consider repudiation in the following system contexts: ballot secrecy, civil-rights-related anonymity, digital cash, drive encryption.
For these systems, the implementation of some non-repudiation controls is antithetical to the business goal of the system.
Similarly, many systems offer user-impersonation features for support purposes, basically spoofing-as-a-service. Such functionality needs to thread a tight needle of security attention. Uniformly treating all forms of spoofing as threats is incorrect.
Should tooling let users treat threats as security features? Maybe. These are edge cases. Perhaps this is a nice-to-have. It would suffice to have a tool treat its recommendations as suggestions for consideration.
Final Thoughts
Threat modeling is a time-consuming process and deserving of as much automation as we can throw at it. The teams making the current generation of tooling are right to be proud of their products. But these tools have limitations to be kept in mind, whether you are building or buying them.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Name
Domain
Purpose
Expiry
Type
YSC
youtube.com
YouTube session cookie.
52 years
HTTP
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Name
Domain
Purpose
Expiry
Type
VISITOR_INFO1_LIVE
youtube.com
YouTube cookie.
6 months
HTTP
Test
test.com
Testing
7 days
HTTP
Analytics cookies help website owners to understand how visitors interact with websites by collecting and reporting information anonymously.
We do not use cookies of this type.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.
We do not use cookies of this type.
Unclassified cookies are cookies that we are in the process of classifying, together with the providers of individual cookies.
We do not use cookies of this type.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies we need your permission. This site uses different types of cookies. Some cookies are placed by third party services that appear on our pages.
Cookie Settings
Discover how the NetSPI BAS solution helps organizations validate the efficacy of existing security controls and understand their Security Posture and Readiness.