Kevin has over 7 years of experience in computer security, Linux administration, and Windows administration. As a security consultant he has worked for clients in several industries, including health care and finance. He specializes in web application and network security testing. Recently, Kevin has been focusing on researching memory analysis tools for penetration testing and using built-in tools for network escalations. He has also found numerous high risk issues during penetration testing. In his spare time Kevin participates in various Security CTF events with the team Robot Mafia.
Directory traversal and local file inclusion bugs are frequently seen in web applications. Directory traversal is when a server allows an attacker to read a file or directories outside of the normal web server directory. Local file inclusion allows an attacker the ability to include an arbitrary local file (from the web server) in the web server’s response. Both of these bugs can be used to read arbitrary files from the server.
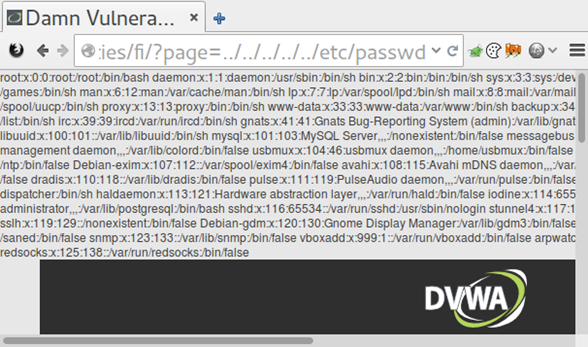
FILE INCLUSION EXAMPLE IN DVWA
In most cases, this means that an attacker can read the /etc/passwd file and the shell history files in order to find information leaks. However, an attacker can also use this to read the proc file system. This can provide some interesting insights into what's running on the server.
A few of the more interesting proc entries include:
Directory
Description
/proc/sched_debug
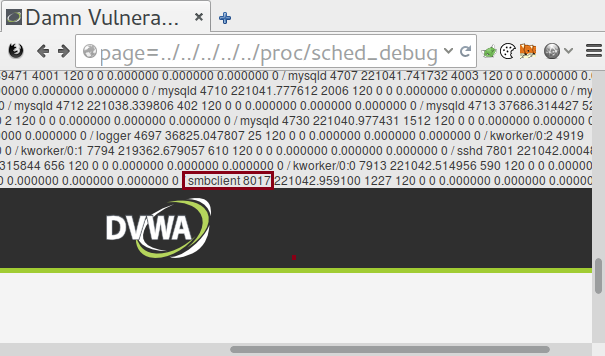
This is usually enabled on newer systems, such as RHEL 6. It provides information as to what process is running on which cpu. This can be handy to get a list of processes and their PID number.
/proc/mounts
Provides a list of mounted file systems. Can be used to determine where other interesting files might be located
/proc/net/arp
Shows the ARP table. This is one way to find out IP addresses for other internal servers.
/proc/net/route
Shows the routing table information.
/proc/net/tcp and /proc/net/udp
Provides a list of active connections. Can be used to determine what ports are listening on the server
/proc/net/fib_trie
This is used for route caching. This can also be used to determine local IPs, as well as gain a better understanding of the target’s networking structure
/proc/version
Shows the kernel version. This can be used to help determine the OS running and the last time it’s been fully updated.
OUTPUT OF /PROC/SCHED_DEBUG SHOWS SMBCLIENT RUNNING ON PID 8017
Each process also has its own set of attributes. If you have the PID number and access to that process, then you can obtain some useful information about it, such as its environmental variables and any command line options that were run. Sometimes these include passwords. Linux also has a special proc directory called self which can be used to query information about the current process without having to know it’s PID. In the following examples you can replace [PID] with either self or the PID of the process you wish to examine.
Directory
Description
/proc/[PID]/cmdline
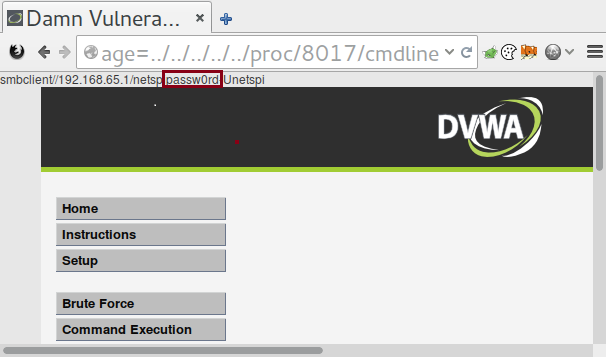
Lists everything that was used to invoke the process. This sometimes contains useful paths to configuration files as well as usernames and passwords.
/proc/[PID]/environ
Lists all the environment variables that were set when the process was invoked. This also sometimes contains useful paths to configuration files as well as usernames and passwords.
/proc/[PID]/cwd
Points to the current working directory of the process. This may be useful if you don’t know the absolute path to a configuration file.
/proc/[PID]/fd/[#]
Provides access to the file descriptors being used. In some cases this can be used to read files that are opened by a process.
CMDLINE LEAKS A CIFS SHARE PASSWORD VIA SMBCLIENT
Combining directory traversal and file inclusion vulnerabilities with the proc file system ends up being a great way to gain access to information relating to the running processes on a Linux system. For instance, it's possible to locate database servers by looking at the current connections the machine has. It also makes it easier to fingerprint what software is running on the machines in order to help determine if they are vulnerable to version-specific issues. It's important not to overlook the proc file system when one of these vulnerabilities are found during a penetration test.
If you've ever used SSH keys to manage multiple machines, then chances are you've used SSH-agent. This tool is designed to keep a SSH key in memory so that the user doesn't have to type their passphrase in every time. However, this can create some security risk. A user running as root may have the ability to pull the decrypted SSH key from memory and reconstruct it.
Due to needing root access, this attack may seem useless. For example, an attacker may be able to install a keylogger and use that to obtain the passphrase for the SSH key. However, this causes the attacker to have to wait for the target to type in their passphrase. This might be hours, days, or weeks, depending on how often the target logs out. This is why obtaining the SSH key from memory is vital to pivoting to other machines in a speedy fashion.
Using SSH-agent
A common method of using SSH-agent is running "SSH-agent bash" and then "SSH-add" to add the key to the agent. Once added, the key will stay in the SSH-agent's stack until the process ends, another key is added, or the user uses the -d or -D option with SSH-add. Most people will run this once and then forget about it until they need to reboot.
Pulling a SSH Key From Memory
There are a few ways to create a copy of the SSH-agents memory. The easiest way is through the use of gdb. Gdb uses the ptrace call to attach to the SSH-agent. This provides gdb with the privileges necessary to create a memory dump of the running process. The grabagentmem.sh script provides a way of automating the dumping of this memory. By default, when it runs it will create a memory dump of the stack for each SSH-agent process. These files are named SSHagent-PID.stack.
root@test:/tmp# grabagentmem.sh Created /tmp/SSHagent-17019.stack
If gdb is not available on the system, then it might be feasible to take a memory dump of the entire machine and use volatility to extract the stack of the SSH-agent processes. However, this process is currently out of the scope for this document.
Parsing SSH Keys From the Memory Dump
Once we have a copy of the stack it becomes possible to extract the key from this file. However, the key is kept in the stack in a different format then the one that was generated by SSH-keygen. This is where the parse_mem.py script comes in handy. This script requires the installation of the pyasn1 python module. Once that is installed the script can be run against the memory file. If that memory file contains a valid RSA SSH key then it will save it to disk. Future versions of the tool may support additional key formats, such as DSA, ECDSA, ED25519, and RSA1.
This key.rsa file can then be used as an argument to the -i switch in SSH. This will act like the original user's key, only without requiring a pass phrase to unlock it.
Obtaining valid, usable SSH keys can help a penetration tester gain further access into a client's network. It's common for keys to be used on both the user's account, as well as the root account on servers. It is also possible that a server is configured to only allow key access. Having access to an unencrypted key can make moving around the environment much easier.
As a penetration tester, I like to avoid replacing binaries on running systems as it makes it more difficult to clean up the system after we're done. Occasionally a tester will come across a Linux server that is used to connect to other internal systems. It would be nice to be able to monitor the SSH sessions without replacing the SSHD daemon. This is where ptrace comes in handy.
Using strace to hook into SSH
The system call ptrace is used to monitor and control another process. It's mostly used by debuggers and programs that map out what another application is doing. One of these applications is strace. Strace connects to another process and prints out all the system calls that the attached process is using. This includes the data that is being sent from a user through SSH.
The SSH client and SSH server use different system calls to read data from the user and show data on the screen. For example, you can read what the user is typing into an SSH client by connecting strace to the process and looking for read(#, "[data]", 16384) system calls. If you attach to an SSH server then you can read what the user is sending by looking for the write(#, "[data]", 1) system calls. The # symbol represents the file descriptor number that SSH is using. This can change based on a number of factors, but should be the same for each SSH process on a system.
Automated strace SSH key logger Python proof of concept
It is possible to automate hooking into new SSH connections using strace and outputting the results to a file. The python code available here can do that. Due to how the python code is parsing the data it will update the log files after a certain amount of bytes are read. While this method isn't that stealthy, it is possible to use exec -a [name] to have strace appear to be a different command in ps and top.
Mitigate ptrace attacks by disabling ptrace
Linux Kernel version 3.4 and above support the ability to limit or disable ptrace altogether. This can be done by using sysctl to set kernel.yama.ptrace_scope to a 1, 2, or 3. By default most distributions set this to 1. According to the Linux Kernel Yama Documentation These numbers map to the following permissions:
0 - Allow non-child processes to ptrace a process
1 - Block non-child processes from ptrace-ing a process
2 - Only processes with CAP_SYS_PTRACE may use it or children calling PTRACE_TRACEME
3 - Disable ptrace. Requires a reboot to change
This makes it possible to disable ptrace on a system by running "sysctl kernel.yama.ptrace_scope=3". However, this may break other programs that are running. Wine, for example, does not work properly with ptrace disabled. I suggest that you test a non-production server and verify that all of its functions can run properly without ptrace enabled. Disabling ptrace also prevents some debugging features.
Conclusion
While ptrace provides useful debugging functionality, in the wrong scenario it can cause security issues. This is why it is important to take a look at what is needed for a server to perform its function and disable any unneeded functionality and services.
Directory traversal and local file inclusion bugs are frequently seen in web applications. Directory traversal is when a server allows an attacker to read a file or directories outside of the normal web server directory. Local file inclusion allows an attacker the ability to include an arbitrary local file (from the web server) in the web server’s response. Both of these bugs can be used to read arbitrary files from the server.
FILE INCLUSION EXAMPLE IN DVWA
In most cases, this means that an attacker can read the /etc/passwd file and the shell history files in order to find information leaks. However, an attacker can also use this to read the proc file system. This can provide some interesting insights into what's running on the server.
A few of the more interesting proc entries include:
Directory
Description
/proc/sched_debug
This is usually enabled on newer systems, such as RHEL 6. It provides information as to what process is running on which cpu. This can be handy to get a list of processes and their PID number.
/proc/mounts
Provides a list of mounted file systems. Can be used to determine where other interesting files might be located
/proc/net/arp
Shows the ARP table. This is one way to find out IP addresses for other internal servers.
/proc/net/route
Shows the routing table information.
/proc/net/tcp and /proc/net/udp
Provides a list of active connections. Can be used to determine what ports are listening on the server
/proc/net/fib_trie
This is used for route caching. This can also be used to determine local IPs, as well as gain a better understanding of the target’s networking structure
/proc/version
Shows the kernel version. This can be used to help determine the OS running and the last time it’s been fully updated.
OUTPUT OF /PROC/SCHED_DEBUG SHOWS SMBCLIENT RUNNING ON PID 8017
Each process also has its own set of attributes. If you have the PID number and access to that process, then you can obtain some useful information about it, such as its environmental variables and any command line options that were run. Sometimes these include passwords. Linux also has a special proc directory called self which can be used to query information about the current process without having to know it’s PID. In the following examples you can replace [PID] with either self or the PID of the process you wish to examine.
Directory
Description
/proc/[PID]/cmdline
Lists everything that was used to invoke the process. This sometimes contains useful paths to configuration files as well as usernames and passwords.
/proc/[PID]/environ
Lists all the environment variables that were set when the process was invoked. This also sometimes contains useful paths to configuration files as well as usernames and passwords.
/proc/[PID]/cwd
Points to the current working directory of the process. This may be useful if you don’t know the absolute path to a configuration file.
/proc/[PID]/fd/[#]
Provides access to the file descriptors being used. In some cases this can be used to read files that are opened by a process.
CMDLINE LEAKS A CIFS SHARE PASSWORD VIA SMBCLIENT
Combining directory traversal and file inclusion vulnerabilities with the proc file system ends up being a great way to gain access to information relating to the running processes on a Linux system. For instance, it's possible to locate database servers by looking at the current connections the machine has. It also makes it easier to fingerprint what software is running on the machines in order to help determine if they are vulnerable to version-specific issues. It's important not to overlook the proc file system when one of these vulnerabilities are found during a penetration test.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Name
Domain
Purpose
Expiry
Type
YSC
youtube.com
YouTube session cookie.
52 years
HTTP
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Name
Domain
Purpose
Expiry
Type
VISITOR_INFO1_LIVE
youtube.com
YouTube cookie.
6 months
HTTP
Test
test.com
Testing
7 days
HTTP
Analytics cookies help website owners to understand how visitors interact with websites by collecting and reporting information anonymously.
We do not use cookies of this type.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.
We do not use cookies of this type.
Unclassified cookies are cookies that we are in the process of classifying, together with the providers of individual cookies.
We do not use cookies of this type.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies we need your permission. This site uses different types of cookies. Some cookies are placed by third party services that appear on our pages.
Cookie Settings
Discover how the NetSPI BAS solution helps organizations validate the efficacy of existing security controls and understand their Security Posture and Readiness.